
监控告警说明
监控告警
KDP平台在Grafana中同步了多个Prometheus Alert监控告警规则,可以在Grafana中通过配置告警通知路径,来及时发现并处理异常情况。
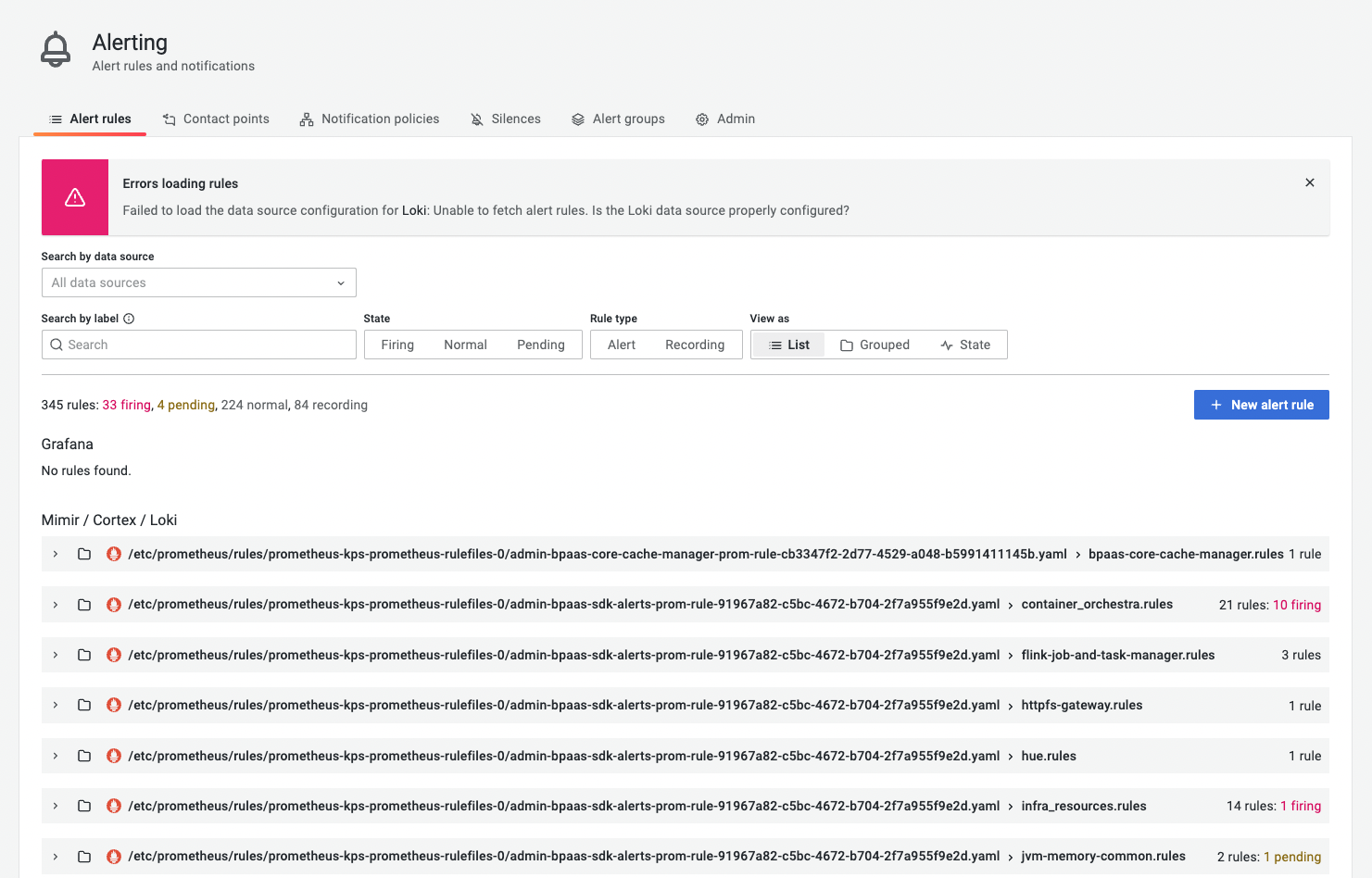
Grafana alert 预警主要是三步:alert rules设置触发告警的规则、contact points设置通过什么发送预警、notification policies将alert rules与contact points关联起来。alert rules设置触发告警的规则时,定义不同label,在notification policies中配置label与contact points的关系。告警方式包括发送Slack、发送邮件、发送钉钉消息等。
同时用户也可以在Prometheus中新增告警规则,来满足业务上的限制。私有化部署时,可联系智领云协助完成告警通知功能。
告警规则说明
告警级别:
- Critical:表示严重的问题需要立即处理,可能会导致系统崩溃或无法正常运行。例如,磁盘空间不足,数据库连接丢失,或者CPU使用率超过阈值等。
- Warning:表示有潜在的问题需要关注,但不会导致系统崩溃。例如,系统负载较高,磁盘使用率接近阈值,或者网络延迟增加等。
- Info:表示一些通知性的信息,例如系统启动和停止,或者更新了某个服务。
- Unknown:表示监控目标的状态无法确定,例如监控目标不可用或无法连接到 Prometheus。
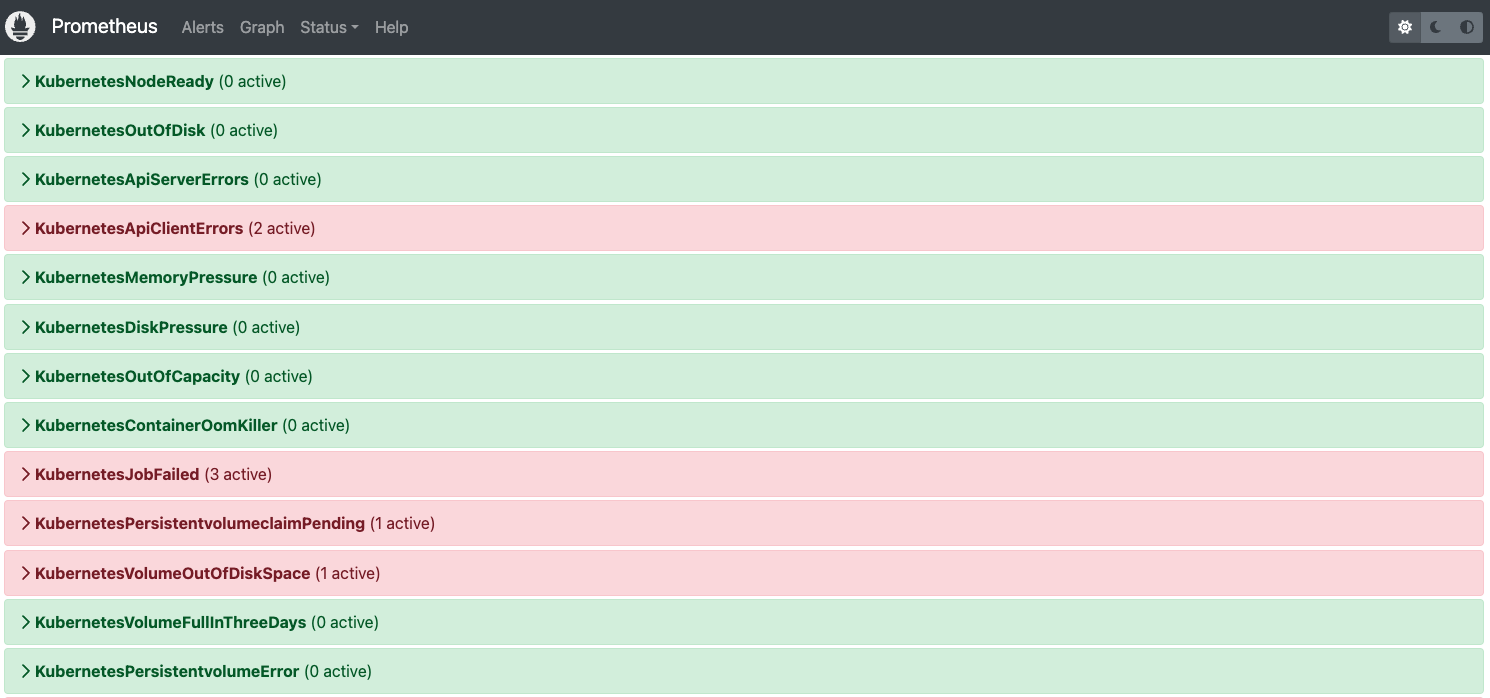
以下介绍部分重要的告警规则。
KubernetesNodeReady
K8s集群节点状态异常
告警表达式
kube_node_status_condition{condition="Ready",status="true"} == 0 |
告警说明
监控了 kube_node_status_condition metric,并检查节点是否处于 Ready 状态,若至少一个节点在2分钟内都不处于 Ready 状态则触发告警。节点的 Ready 状态是指 kubelet 组件可以与 Kubernetes API 通信,并且节点上的所有容器都处于运行状态。如果一个节点的 Ready 状态为 false,则意味着该节点上可能存在一些问题,例如网络故障或硬件问题。
告警级别
critical
告警处理
检查未就绪的节点的状态。确认节点上的 kubelet 组件是否正在运行,并且可以与 Kubernetes API 通信;确认节点上的容器是否正在运行;检查节点是否存在硬件问题或网络故障。
KubernetesOutOfDisk
K8s集群磁盘资源紧缺
告警表达式
kube_node_status_condition{condition="OutOfDisk",status="true"} == 1 |
告警说明
监控了 kube_node_status_condition metric,并检查节点是否处于 OutOfDisk 状态。若至少一个节点上磁盘空间在2分钟内持续不足,则触发告警。若节点上磁盘空间不足可能会导致无法调度新的Pod到该节点上。
告警级别
critical
告警处理
检查磁盘空间不足的节点的状态。确认该节点上的磁盘使用情况,并释放空间。
KubernetesApiServerErrors
ApiServer错误率
告警表达式
sum(rate(apiserver_request_total{code=~"^(?:5..)$",job="apiserver"}[1m])) |
告警说明
检查 Kubernetes API Server 错误率是否超过3%,在2分钟内持续超过则告警。如果触发了该告警,表示 API Server 正在经历较高的错误率,这可能会影响 Kubernetes 群集的可用性。
告警级别
critical
告警处理
检查Kubernetes API Server 的日志,检查错误是否由特定的资源或操作引起。确认 Kubernetes 集群的资源是否足够,例如 CPU,内存,磁盘等。
KubernetesMemoryPressure
K8s内存压力
告警表达式
kube_node_status_condition{condition="MemoryPressure",status="true"} == 1 |
告警说明
检查 Kubernetes Node 是否受到了内存压力,如果2分钟内持续受到内存压力,就会触发告警。这种情况可能会影响节点的性能和稳定性。
告警级别
warning
告警处理
确认是否有应用程序或进程占用了大量的内存资源。确认 Kubernetes Node 的资源是否足够,例如 CPU,内存,磁盘等。
KubernetesDiskPressure
K8s磁盘压力
告警表达式
kube_node_status_condition{condition="DiskPressure",status="true"} == 1 |
告警说明
检查 Kubernetes Node 是否受到了磁盘压力,如果2分钟内持续受到磁盘压力,就会触发告警。这种情况可能会影响节点的性能和稳定性。
告警级别
warning
告警处理
确认是否有应用程序或进程占用了大量的磁盘资源。确认该节点上的磁盘使用情况,并释放空间。
KubernetesContainerOomKiller
容器被OOM杀死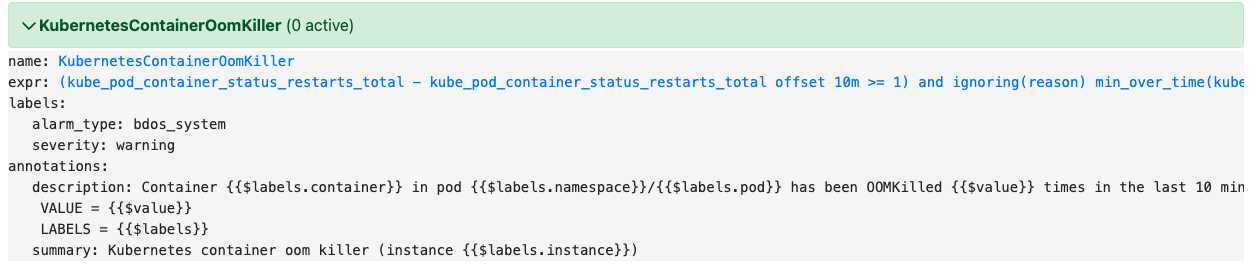
告警表达式
(kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring(reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1 |
告警说明
检测 Kubernetes Pod 中是否有容器因 OOM(Out Of Memory)而被杀死,如果出现这种情况,则会触发告警。
此告警需满足公式中两种情况。其一,容器在过去 10 分钟内是否发生了重启,如果重启次数大于等于 1,则视为满足条件。这个条件可以排除一些短暂的故障或噪声数据的影响。其二,过去 10 分钟内是否有容器被 OOM 杀死,如果有容器被 OOM 杀死,则视为满足条件。当两个条件都满足时,就会触发告警,提示 Pod 中的某个容器被 OOM 杀死了。
告警级别
warning
告警处理
检查容器的内存使用情况,确认是否存在内存泄漏或内存使用过高的情况。确认容器的资源限制是否正确配置。考虑增加节点资源。
KubernetesPodNotHealthy
集群中Pod状态、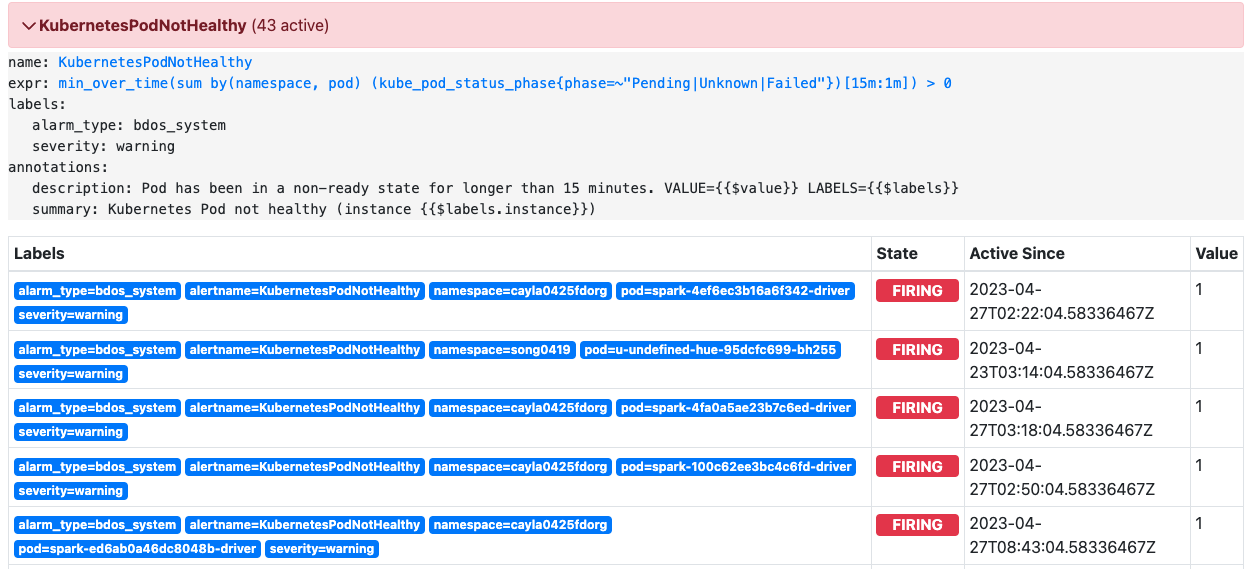
告警表达式
min_over_time(sum by(namespace, pod) (kube_pod_status_phase{phase=~"Pending|Unknown|Failed"})[15m:1m]) > 0 |
告警说明
检测 Kubernetes 集群过去 15 分钟内是否存在处于 Pending、Unknown 或 Failed 状态的 Pod,如果有则会触发告警。
告警级别
warning
告警处理
查看所有应用Pod的状态,并确认是否存在处于 Pending、Unknown 或 Failed 状态的应用Pod。查看详细信息,并尝试解决问题。
KubernetesPodCrashLooping
集群中Pod中容器重启频繁
告警表达式
increase(kube_pod_container_status_restarts_total[1m]) > 3 |
告警说明
检测在近2分钟内,容器每分钟重启的次数是否均超过3次,如果是则会触发告警。
告警级别
warning
告警处理
查看应用Pod中所有容器的状态,并确认哪些容器频繁重启,查看容器日志,确定重启原因。
HostClockNotSynchronising
节点时间同步状态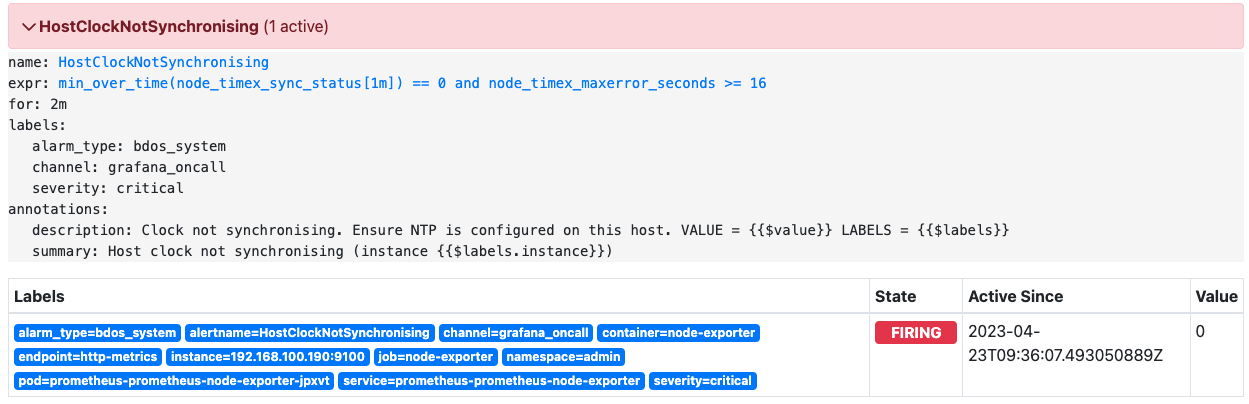
告警表达式
min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16 |
告警说明
节点的时间同步状态为不正常并且连续2分钟内最大误差时间每分钟均超过16秒,则会触发告警。
告警级别
critical
告警处理
检查节点当前的系统时间是否正确,检查节点的时钟同步状态,确定问题所在。
HostHighCpuUsage
主机CPU使用率过高
告警表达式
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80 |
告警说明
节点在2分钟内平均CPU使用率超过80%,触发告警。
告警级别
warning
告警处理
检查节点上进程的CPU使用情况。
HostOutOfMemory
主机可使用内存过少
告警表达式
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10 |
告警说明
节点内存可使用率低于10%,触发告警。
告警级别
warning
告警处理
检查节点上进程的内存使用情况。
HostOomKillDetected
节点发生OOM
告警表达式
increase(node_vmstat_oom_kill[1m]) > 0 |
告警说明
在过去的 1 分钟内,node_vmstat_oom_kill 时间序列发生的 OOM 事件的数量的增长率。如果增长率大于 0,则触发告警。
告警级别
warning
告警处理
查看节点OOM事件的日志文件获取具体信息。分析 OOM 事件发生的原因,通常是由于系统内存不足导致的,可能是因为某个进程占用了过多的内存,或者系统中运行的应用程序数量过多,导致内存不足。针对性地调整系统配置或者应用程序配置,以减少内存的使用,例如,可以增加系统的物理内存或者 swap 空间,或者减少应用程序的并发数量或者降低应用程序的内存使用量。
PrometheusTooManyRestarts
Prometheus进程反复重启
告警表达式
changes(process_start_time_seconds{job=~"prometheus|pushgateway|alertmanager"}[15m]) > 2 |
告警说明
Prometheus、Pushgateway 或 Alertmanager 进程在过去15分钟内重启的情况,如果重启次数大于2,则触发告警。
告警级别
warning
告警处理
检查 Prometheus、Pushgateway 或 Alertmanager 进程是否存在重启的情况。分析进程重启的原因。针对性地调整系统配置或者应用程序配置,以减少进程重启的发生。
MinioDiskOffline
MinIO存储服务的硬盘离线
告警表达式
minio_disks_offline > 0 |
告警说明
检测 MinIO 存储服务的硬盘是否离线,离线则触发告警。
告警级别
warning
告警处理
通过查看硬盘的物理连接、控制器日志等方式来确定硬盘的状态。
MinioDiskSpaceUsage
MinIO磁盘可用空间过低
告警表达式
disk_storage_available / disk_storage_total * 100 < 10 |
告警说明
计算MinIO磁盘可用空间占总空间的百分比,如果百分比小于10,则触发告警。
告警级别
warning
告警处理
考虑清理磁盘上不必要的文件或者增加磁盘容量。如果磁盘空间充足,但是告警依然存在,需要进一步排查是否存在磁盘空间占用异常或者磁盘损坏的情况。
admin-hdfs-NamenodePodNotReady
HDFS NameNode Pod故障
告警表达式
min_over_time(sum by(namespace, pod, phase) (kube_pod_status_phase{namespace="admin",phase=~"Pending|Unknown|Failed",pod=~"hdfs-namenode-[0,1]"})[5m:1m]) > 0 |
告警说明
监控 admin 命名空间中名为 hdfs-namenode-0 和 hdfs-namenode-1 的 Pod是否处于 Pending、Unknown 或 Failed 状态超过5分钟,则告警。
告警级别
critical
告警处理
检查应用Pod状态,确定异常状态原因。
admin-hdfs-JournalnodePodNotReady
HDFS JournalNode Pod故障
告警表达式
min_over_time(sum by(namespace, pod, phase) (kube_pod_status_phase{namespace="admin",phase=~"Pending|Unknown|Failed",pod=~"hdfs-journalnode-[0,1,2]"})[5m:1m]) > 0 |
告警说明
监控 admin 命名空间中 Hadoop HDFS 组件的 JournalNode 是否处于 Pending、Unknown 或 Failed 状态超过 5 分钟,如果超过则触发告警。
告警级别
critical
admin-hdfs-NamenodeContainerNotRunning
HDFS NameNode Container故障
告警表达式
min_over_time(sum by(container) (kube_pod_container_status_running{container="hdfs-namenode",namespace="admin",pod=~"hdfs-namenode-[0,1]"})[5m:1m]) < 2 |
告警说明
监控 admin 命名空间中 HDFS NameNode 组件是否正常运行,如果不足 2 个容器处于运行状态超过 5 分钟,则触发告警。
告警级别
warning
admin-hdfs-JournalnodeContainerNotRunning
HDFS JournalNode Container故障

告警表达式
min_over_time(sum by(container) (kube_pod_container_status_running{container="hdfs-journalnode",namespace="admin",pod=~"hdfs-journalnode-[0,1,2]"})[5m:1m]) < 3 |
告警说明
监控 admin 命名空间中 HDFS JournalNode 组件是否正常运行,如果不足 3 个容器处于运行状态超过 5 分钟,则触发告警。
告警级别
warning
KerberosIsUnavailable
Kerberos不可用
告警表达式
sum(kerberos_status_available) == 0 |
告警说明
监控 Kerberos 是否可用,如果 Kerberos 不可用,则触发告警。
告警级别
warning
告警处理
确认 Kerberos 服务是否已经停止或者发生了故障,重新启动或者修复 Kerberos 服务。
ConfigReloaderSidecarErrors
Reloader故障
告警表达式
max_over_time(reloader_last_reload_successful{namespace=~".+"}[5m]) == 0 |
告警说明
过去的5分钟内,所有命名空间的reloader没有成功加载配置。
告警级别
warning
etcdMembersDown
etcd集群不可用
告警表达式
max without(endpoint) (sum without(instance) (up{job=~".*etcd.*"} == bool 0) or count without(To) (sum without(instance) (rate(etcd_network_peer_sent_failures_total{job=~".*etcd.*"}[2m])) > 0.01)) > 0 |
告警说明
支持10分钟中没有可用的etcd实例或者peer通信失败率高于1%的情况下发送告警
告警级别
critical
告警处理
检查etcd集群的健康状态,确认是否存在etcd实例不可用或者peer通信失败的情况,并尝试重新启动相应的etcd实例或调整etcd集群的配置以解决问题。检查网络连接是否正常,包括etcd实例之间的网络连接以及etcd与Prometheus之间的网络连接。
KubeAPIDown
ApiServer异常
告警表达式
absent(up{job="apiserver"} == 1) |
告警说明
检测是否有 apiserver 实例15分钟均处于宕机或不可达状态。
告警级别
critical
KubeControllerManagerDown
KubeControllerManager异常
告警表达式
absent(up{job="kube-controller-manager"} == 1) |
告警说明
检测是否 kube-controller-manager 组件15分钟均未正常运行。
告警级别
critical
KubeProxyDown
KubeProxy异常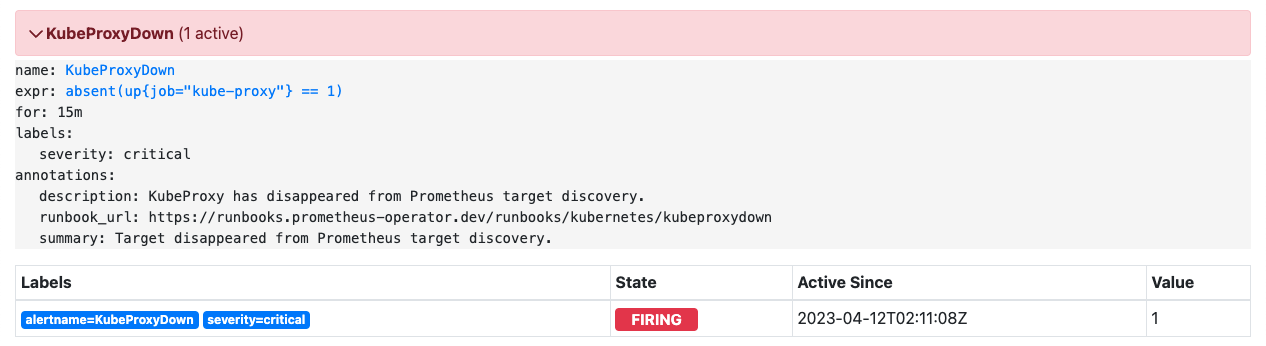
告警表达式
absent(up{job="kube-proxy"} == 1) |
告警说明
检测是否kube-proxy组件15分钟均未正常运行。
告警级别
critical
KubeletServerCertificateExpiration
证书快过期
告警表达式
kubelet_certificate_manager_client_ttl_seconds < 604800 |
告警说明
检查 Kubernetes 中 kubelet 证书管理器(kubelet-certificate-manager)客户端证书的 TTL(Time-To-Live,生存时间)是否小于一周(604800 秒),如果小于一周则触发告警。
告警级别
warning
告警处理
检查 kubelet-certificate-manager 配置,确保其客户端证书的 TTL 设置得当,以避免证书过期导致的故障。