
核心指标说明
集群
集群寿命
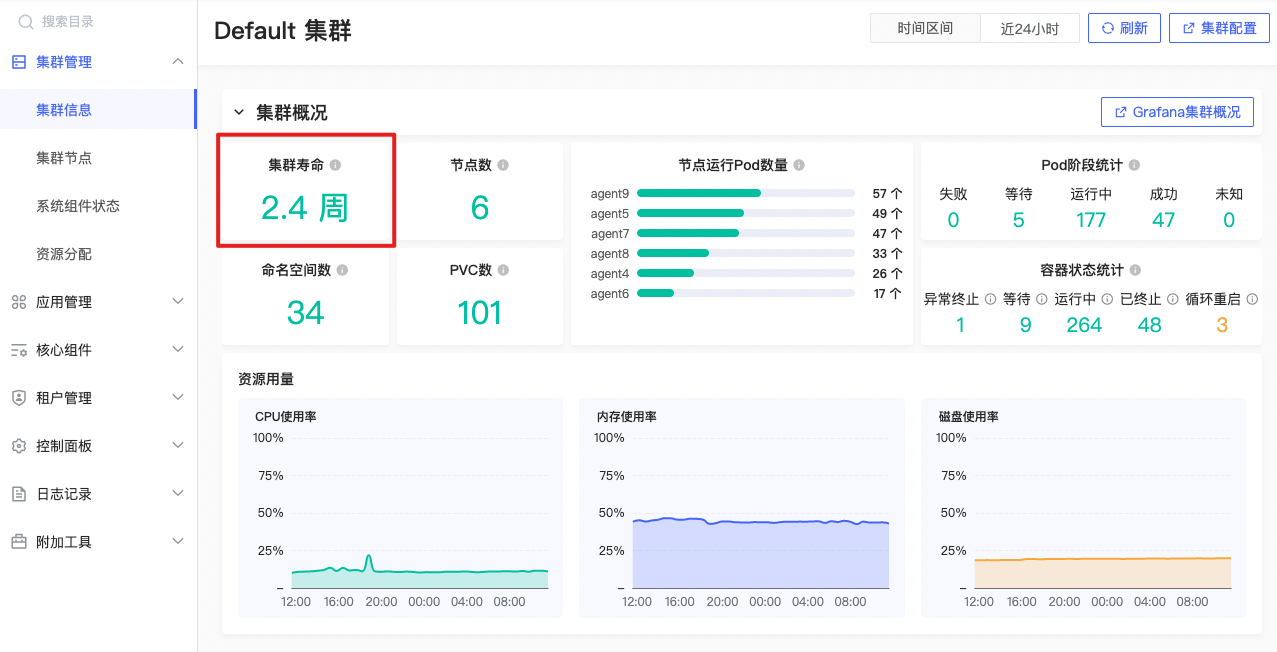
sum(time() - kube_service_created{namespace=\"default\",service=\"kubernetes\"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_service_created | K8s服务的创建时间 |
公式释义
default集群寿命,当前时间-k8s集群”default”创建时间。
将选择器返回的所有时间戳与当前时间戳相减,然后将所有时间差相加。最终结果是”kubernetes”服务在”default”命名空间中的总存在时间。
节点数
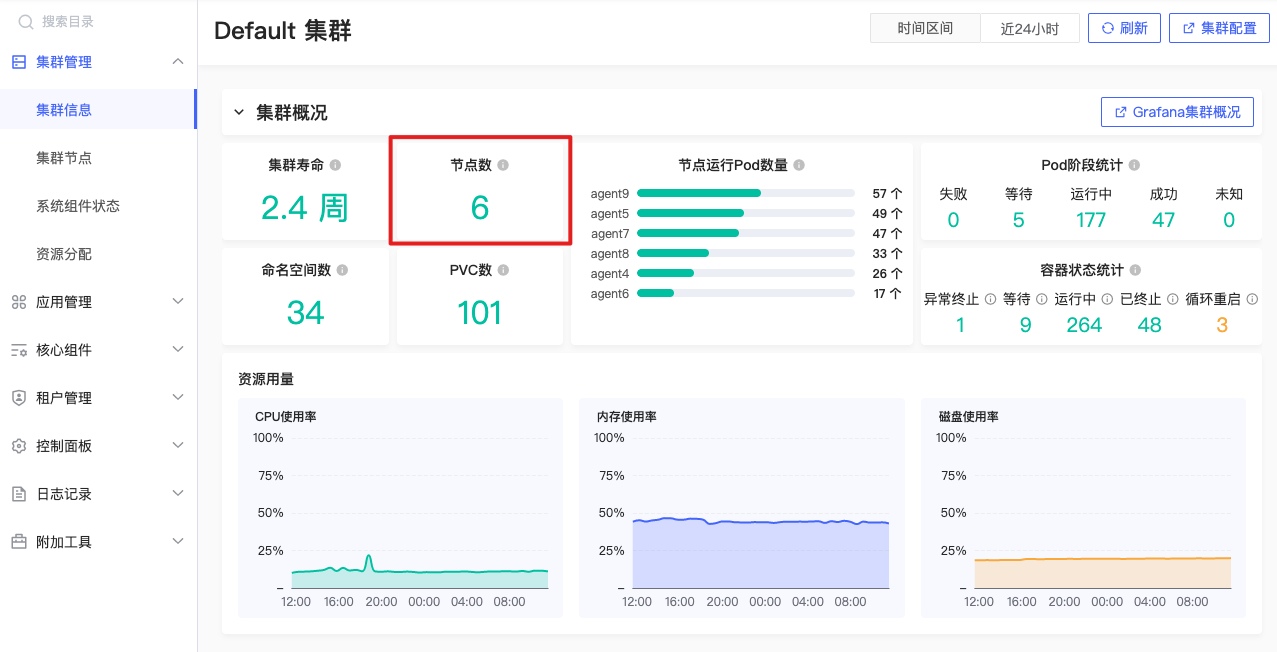
count(kube_node_info) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_node_info | K8s集群节点信息 |
公式释义
计算集群节点个数,统计K8s集群中主控节点及工作节点个数
Pod数
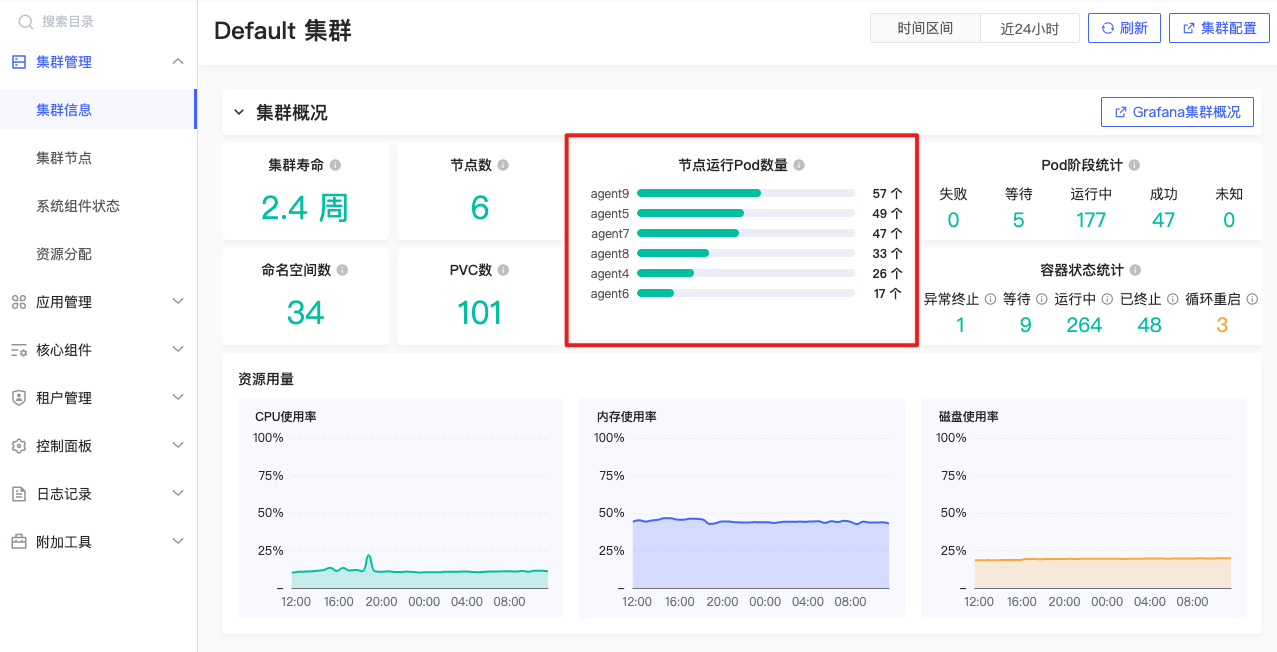
每个节点Pod数量
sum by (node) (kube_pod_info{node!~""}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_info | Kubernetes 集群中每个 Pod 的元数据信息,例如 Pod 名称、命名空间、标签、容器等 |
公式释义
计算各个节点当前正在运行的Pod数
命名空间数
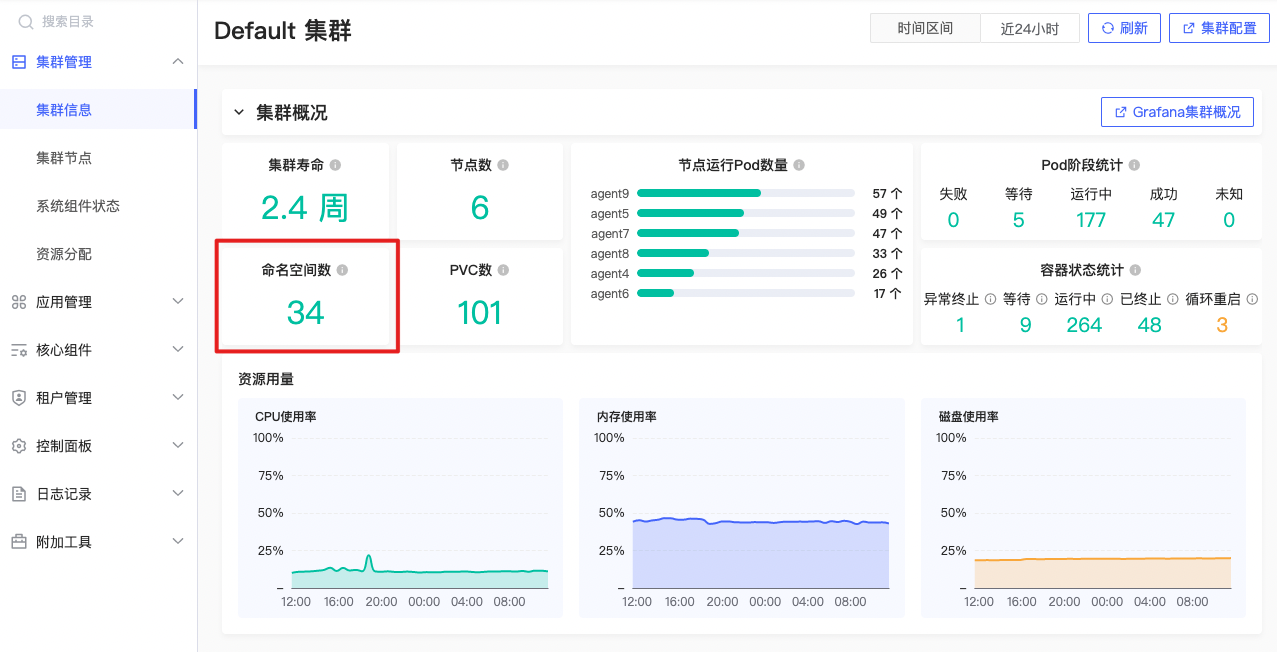
count(kube_namespace_created) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_namespace_created | Kubernetes 集群中命名空间(namespace)的创建时间 |
公式释义
Kubernetes 集群中所有创建过的命名空间数量
PVC数
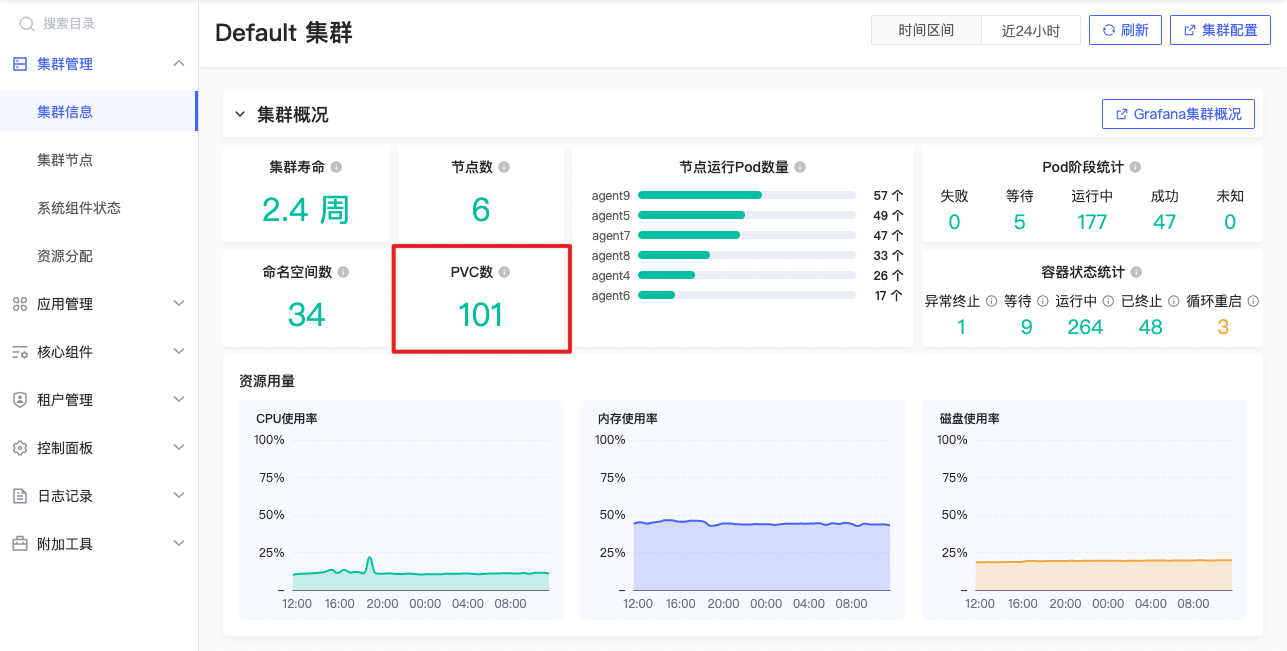
count(kube_persistentvolumeclaim_info) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_persistentvolumeclaim_info | Kubernetes 集群中每个持久卷声明(Persistent Volume Claim,PVC)的元数据信息,例如 PVC 名称、命名空间、状态、存储类、请求的存储大小等 |
公式释义
集群中持久卷申领次数。持久卷是Kubernetes中用于存储数据的一种抽象概念,它可以是云存储、网络存储或本地存储。
Pod阶段统计
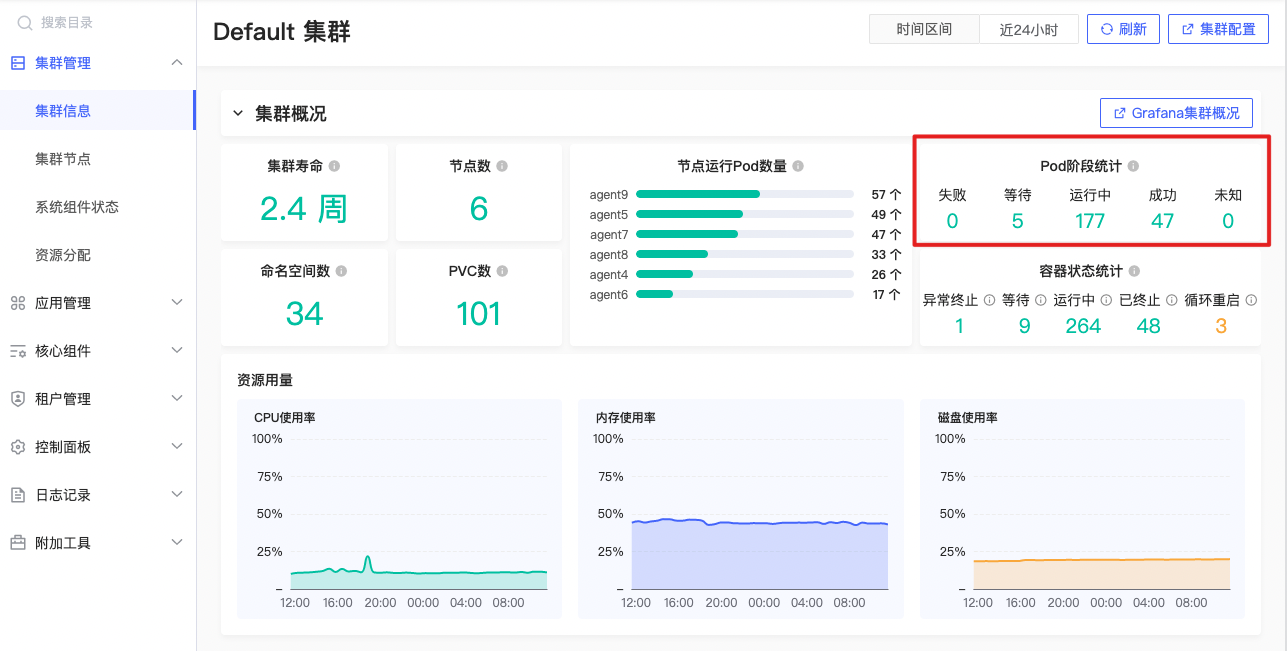
sum by (phase) (kube_pod_status_phase) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_status_phase | Kubernetes 集群中每个 Pod 的运行状态(Phase),即 Pod 的当前生命周期阶段。 |
Pod阶段包括如下五种
Pending: Pod 正在被调度并等待创建
Running: Pod 已经成功创建并正在运行中
Succeeded: Pod 中的所有容器都已经成功完成并退出
Failed: Pod 中的一个或多个容器已经失败
Unknown: Pod 状态无法确定,通常是由于与 API 服务器通信失败导致的
公式释义
当前集群中Pod处于等待、运行中、成功、失败、未知五种不同运行状态个数
容器阶段统计
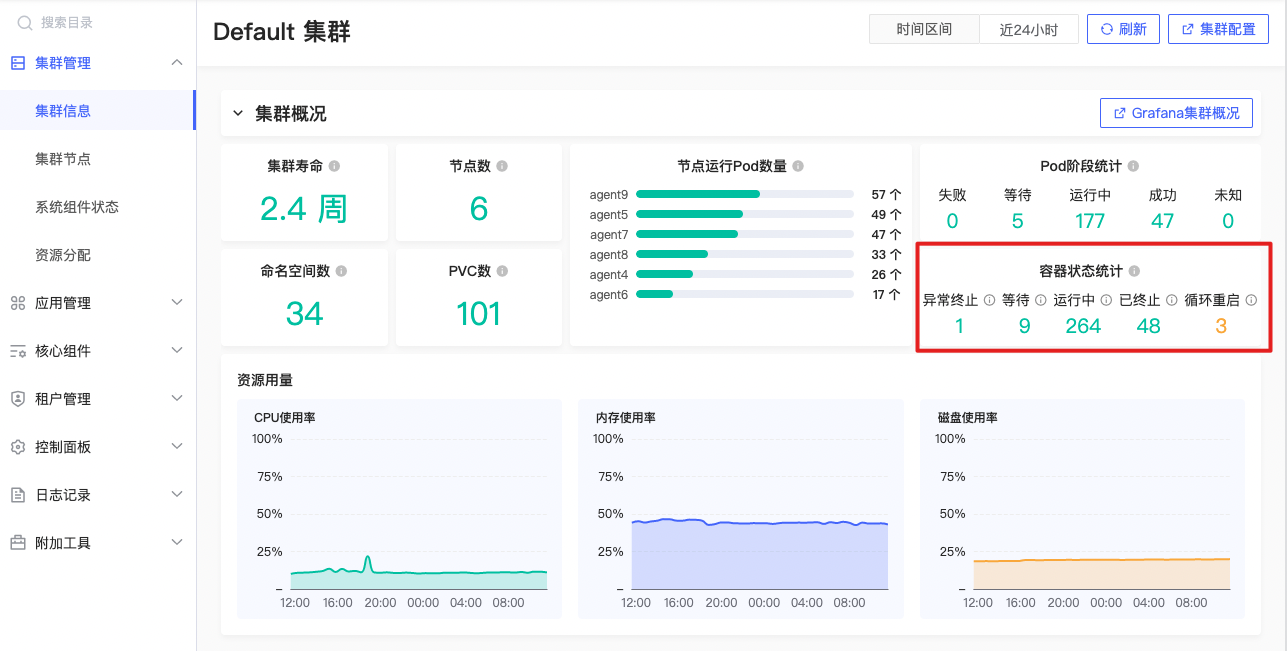
- 异常终止数
count(kube_pod_container_status_terminated_reason{reason!=\"Completed\"} !=0 ) or vector(0) |
- 等待数
count(kube_pod_container_status_waiting !=0 ) or vector(0) |
- 运行中
count(kube_pod_container_status_running !=0 ) or vector(0) |
- 已终止
count(kube_pod_container_status_terminated_reason !=0 ) or vector(0) |
- 循环重启
count(rate(kube_pod_container_status_restarts_total{job=\"kube-state-metrics\"}[5m]) * 60 * 5 > 0) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_terminated_reason | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的终止原因 |
| kube_pod_container_status_waiting | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的等待状态 |
| kube_pod_container_status_running | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的运行状态 |
| kube_pod_container_status_restarts_total | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的重启次数 |
公式释义
- 容器终止且终止原因不为“Completed”的容器数量,若无返回0
- 容器处于等待中的容器数量,若无返回0
- 容器处于运行中的容器数量,若无返回0
- 容器终止且有终止原因的容器数量,若无返回0
- 容器五分钟内重启次数大于0的容器数
集群CPU使用率趋势
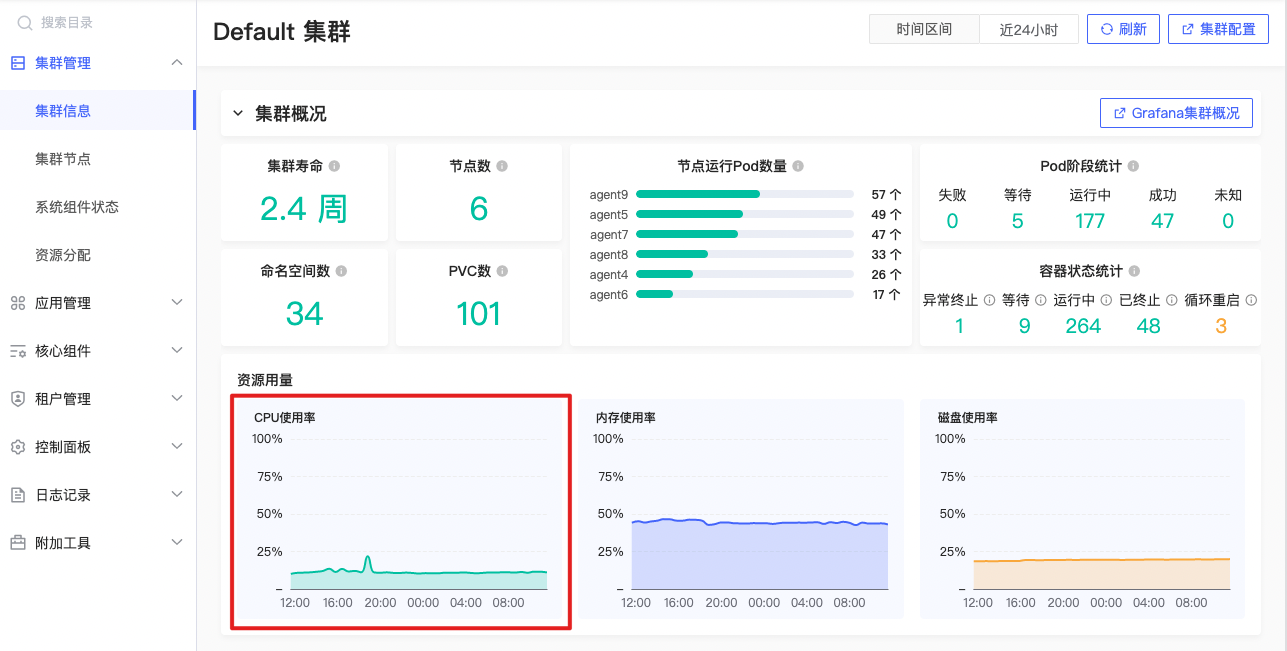
avg(1 - avg(rate(node_cpu_seconds_total{origin_prometheus=~\"$origin_prometheus\", mode=\"idle\"}[$interval])) by (instance)) * 100 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_cpu_seconds_total | 是一个 Prometheus 指标,用于衡量 Linux 系统上 CPU 的使用情况。它表示自系统启动以来,每个 CPU 核心(包括逻辑核心)使用 CPU 的总时间(单位为秒)。这个指标提供了对 CPU 使用情况的详细信息,可以帮助管理员更好地了解系统负载以及应用程序的 CPU 使用情况。 |
| node_load5 | 是一个 Linux 系统性能指标,用于衡量系统的负载情况。它表示系统在过去的 5 分钟内平均负载情况,也就是在这个时间段内正在运行和等待运行的进程数。 |
公式释义
系统在指定时间段内平均CPU使用率趋势变化
集群内存使用率趋势
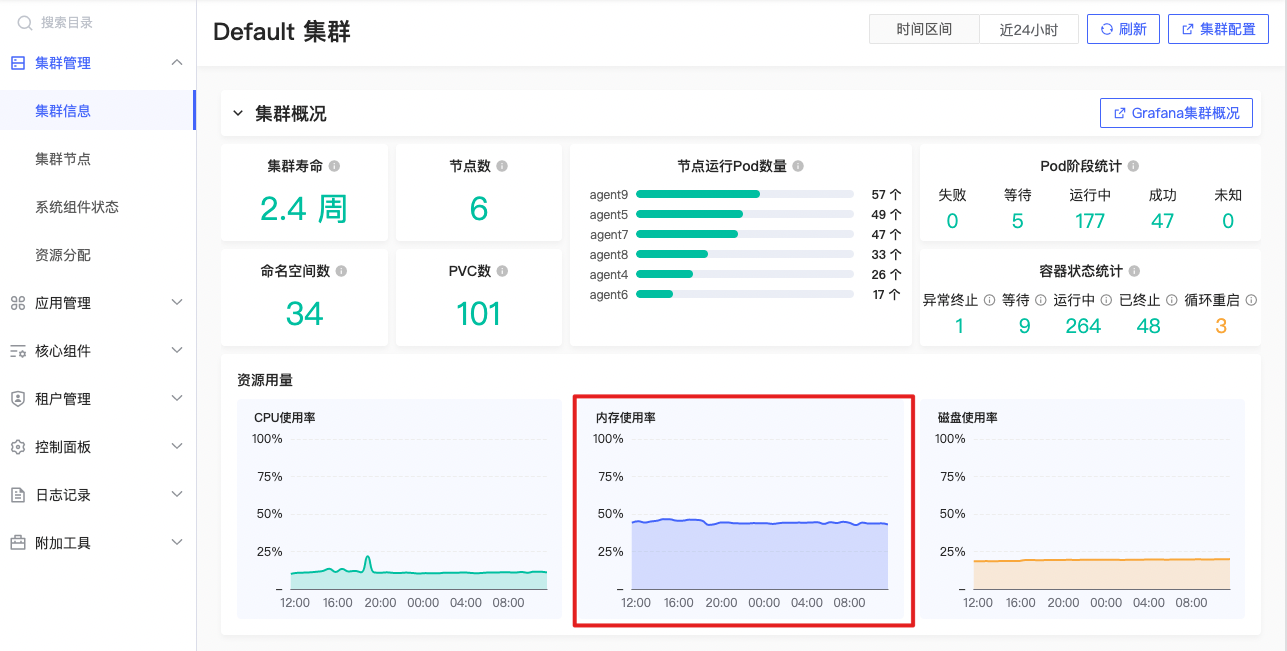
(sum(node_memory_MemTotal_bytes{origin_prometheus=~\"$origin_prometheus\"} - node_memory_MemAvailable_bytes{origin_prometheus=~\"$origin_prometheus\",job=~\"node-exporter\"}) / sum(node_memory_MemTotal_bytes{origin_prometheus=~\"$origin_prometheus\",job=~\"node-exporter\"}))*100 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_memory_MemTotal_bytes | 表示系统上可用的物理内存总量(单位为字节) |
| node_memory_MemAvailable_bytes | 一个 Prometheus 指标,用于衡量 Linux 系统上可用的内存量。它表示系统上当前可供进程和应用程序使用的空闲内存总量(单位为字节)。它考虑了 Linux 内核对内存的管理方式,包括缓存和缓冲区等。 |
公式释义
Node Exporter的实例中,平均内存使用率变化趋势
集群磁盘使用率趋势
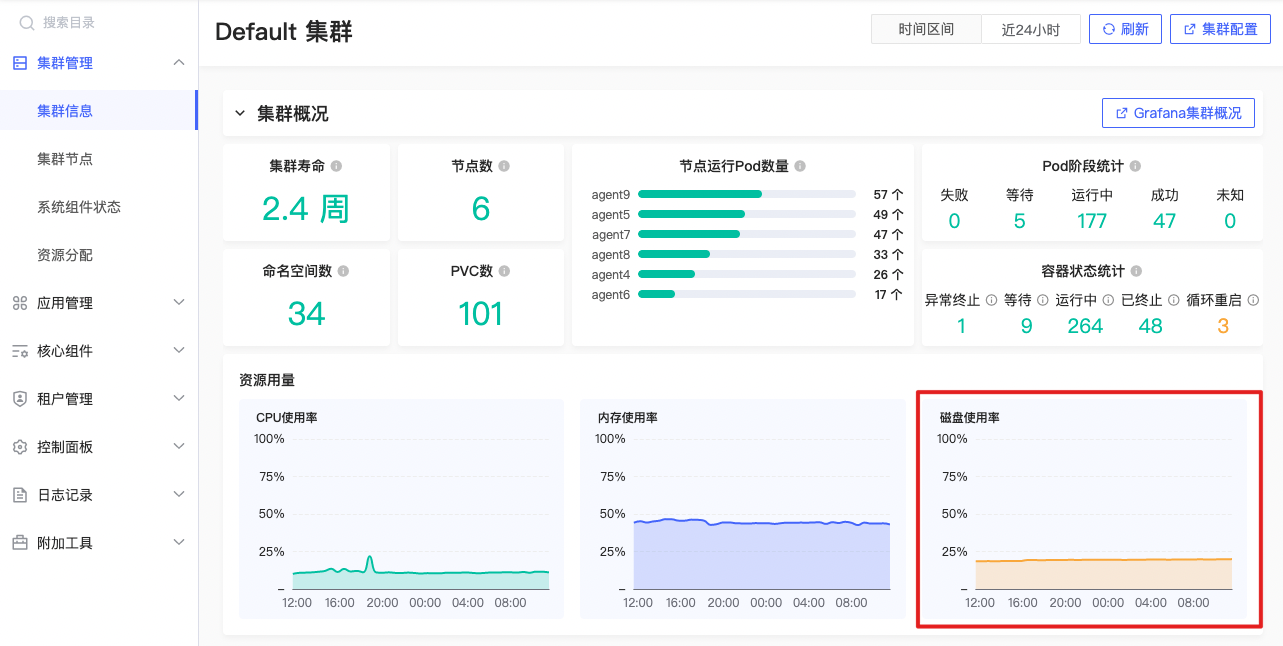
sum(max by (device,instance) (node_filesystem_size_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"} - node_filesystem_free_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"})) * 100 / sum(max by (device,instance) (node_filesystem_size_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"} - node_filesystem_free_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"} + node_filesystem_avail_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"})) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_filesystem_size_bytes | 一个Prometheus指标,它用于记录节点上文件系统的总大小 |
| node_filesystem_free_bytes | 一个Prometheus指标,它用于记录节点上文件系统的可用空间 |
公式释义
在指定时间段内所有节点磁盘使用率的平均值
“max by (device,instance)”函数,根据设备名称和实例名称对每个节点的值进行聚合,并返回每个设备和实例的最大值。然后,这两个部分的结果进行数学运算,以计算每个节点的磁盘使用率。
CPU请求率
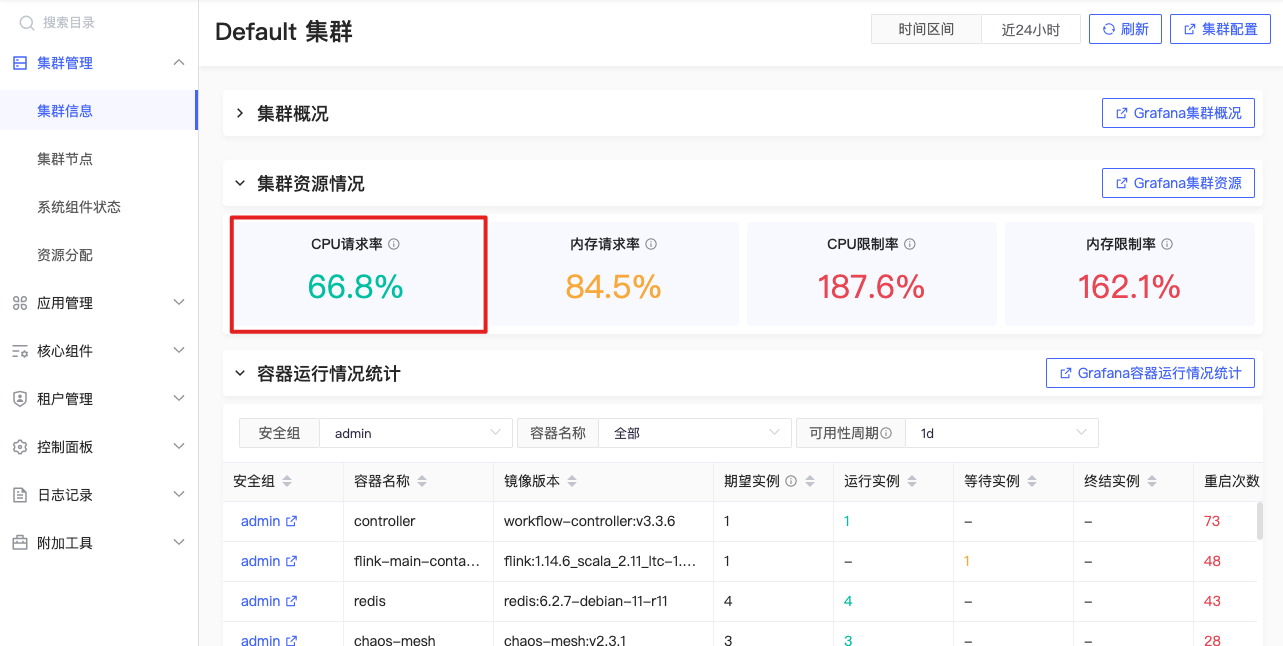
sum(namespace_cpu:kube_pod_container_resource_requests:sum) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
集群中所有容器的CPU请求量/工作节点上可分配的总CPU %
一般来说,如果容器的request都是比较合理的设置,整体请求率的范围应该保证:
- 新的容器比较容易拿到资源启动;
- 单个节点失效后需要迁移的负载不会造成整体请求率的太大波动。实际中一般60%-70%比较正常,超过80%有可能会影响新的负载的发布,或者在节点失效后无法进行负载迁移。
内存请求率
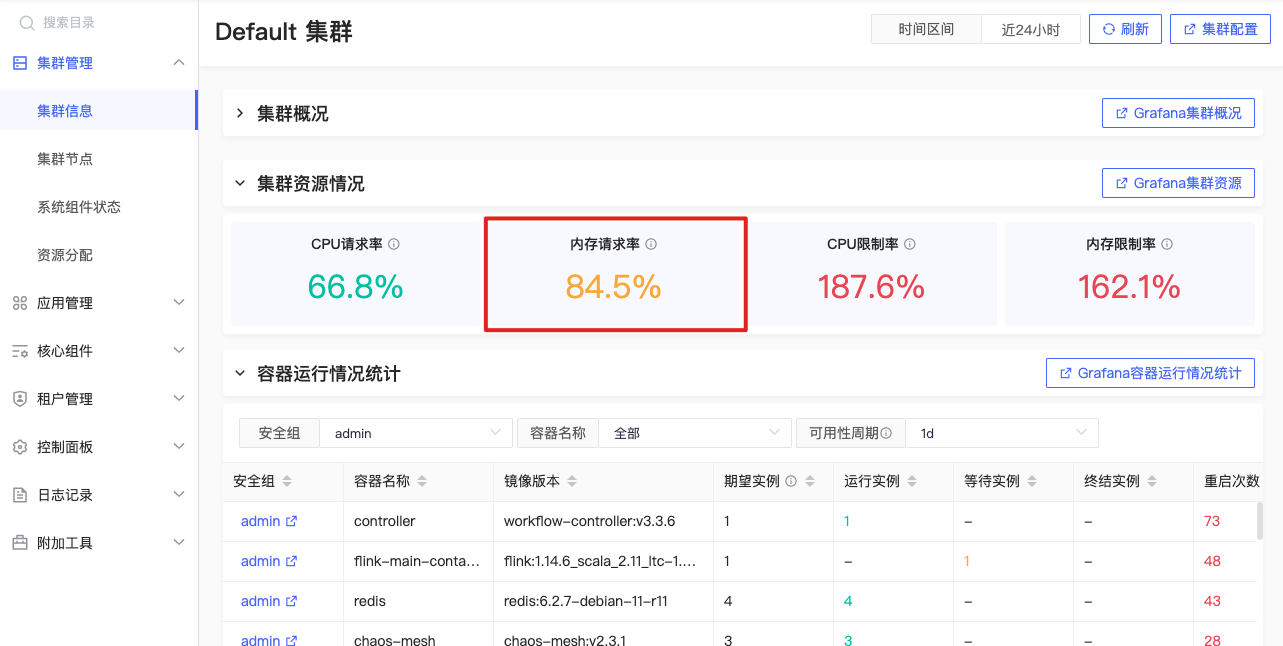
sum(namespace_memory:kube_pod_container_resource_requests:sum) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
集群中所有容器的内存请求量/工作节点上可分配的总内存 %
CPU限制率
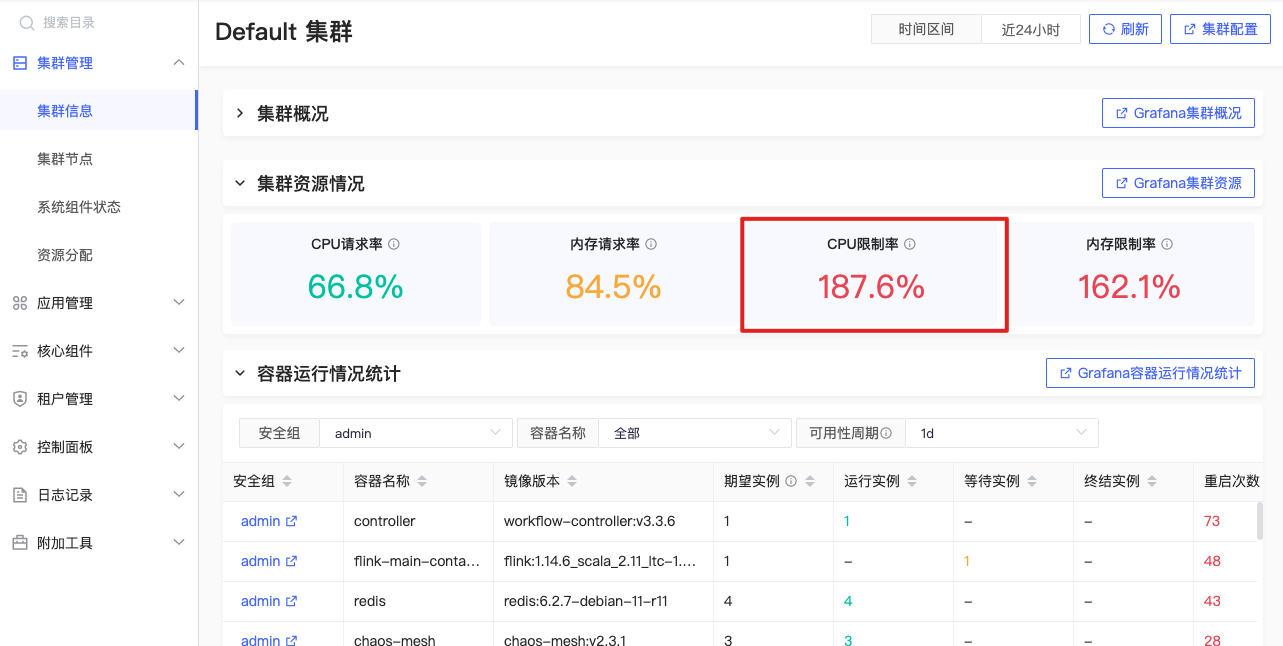
sum(namespace_cpu:kube_pod_container_resource_limits:sum) / sum(kube_node_status_allocatable{resource="cpu"} and on(node) kube_node_role{role!~"control-plane|master"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
集群中所有容器的CPU限制量/工作节点上可分配的总CPU %
内存限制率
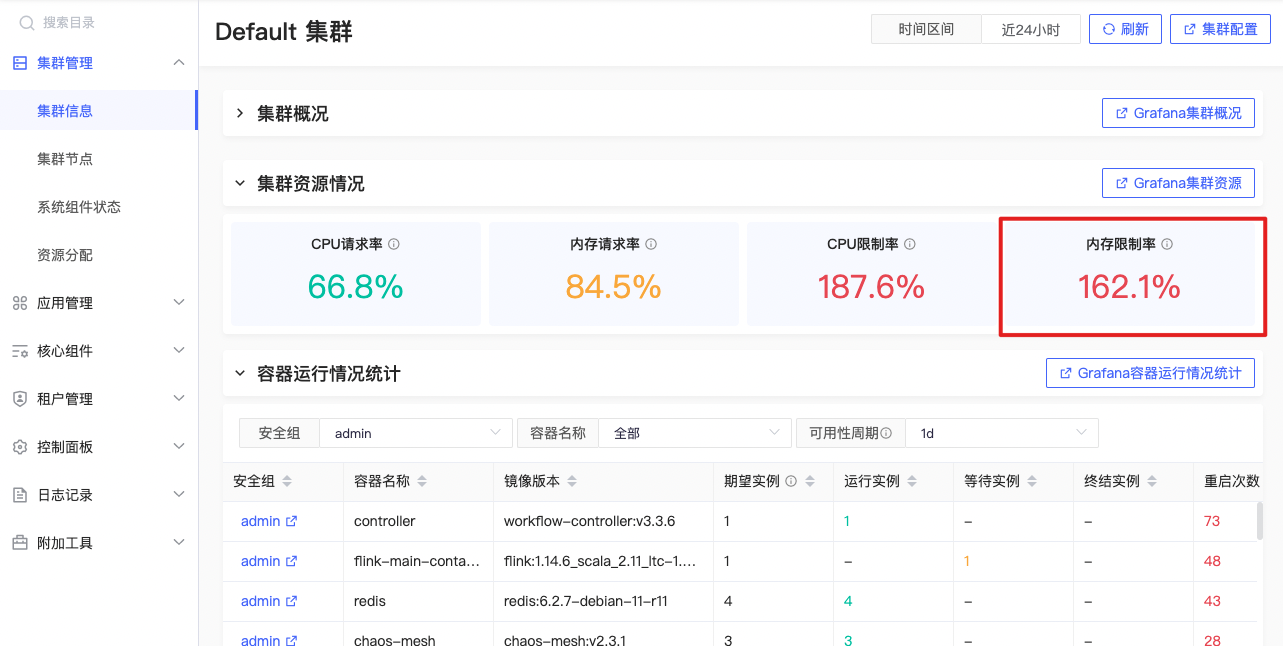
sum(namespace_memory:kube_pod_container_resource_limits:sum) / sum(kube_node_status_allocatable{resource="memory"} and on(node) kube_node_role{role!~"control-plane|master"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
集群中所有容器的内存限制量/工作节点上可分配的总内存 %
节点
节点状态
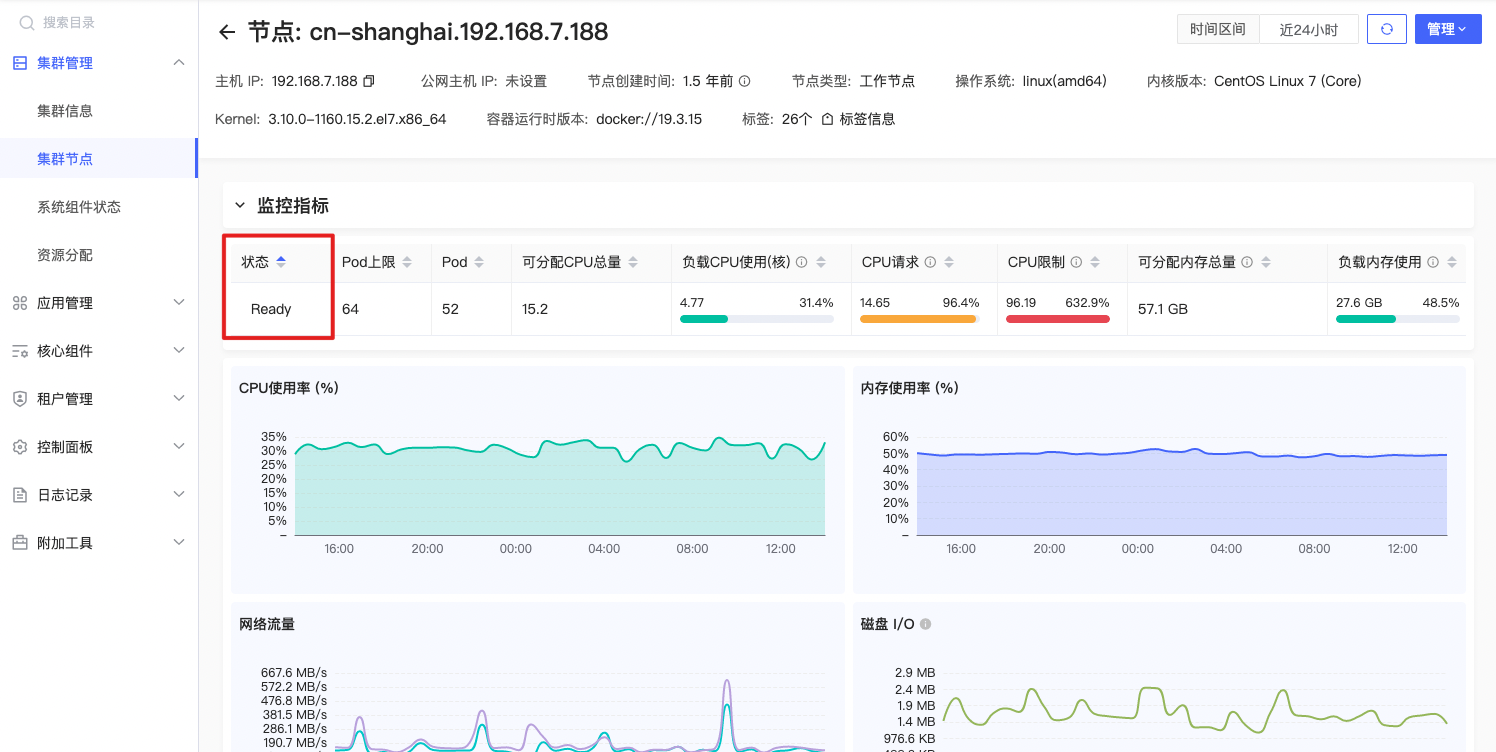
kube_node_status_condition{origin_prometheus=~\"$origin_prometheus\",status=\"true\",node=~\"^$node$\"} == 1 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_node_status_condition | Kubernetes 集群中每个节点的运行状态。每个节点的运行状态可以通过节点的条件(Condition)来表示。condition: 节点的条件类型(Ready、OutOfDisk、MemoryPressure、DiskPressure 或 NetworkUnavailable);status: 节点的条件状态(True 或 False);node: 节点的名称 |
节点状态类型包括
- Ready: 节点是否已经准备好接受工作负载。当节点处于 Ready 状态时,Kubernetes 调度器可以将 Pod 调度到该节点上。
- OutOfDisk: 节点是否已经用尽了磁盘空间。当节点处于 OutOfDisk 状态时,Kubernetes 将阻止调度新的 Pod 到该节点上。
- MemoryPressure: 节点是否已经用尽了内存空间。当节点处于 MemoryPressure 状态时,Kubernetes 将尝试通过终止运行在该节点上的 Pod 来释放内存。
- DiskPressure: 节点是否已经用尽了磁盘空间。当节点处于 DiskPressure 状态时,Kubernetes 将尝试通过终止运行在该节点上的 Pod 来释放磁盘空间。
- NetworkUnavailable: 节点的网络连接是否可用。当节点处于 NetworkUnavailable 状态时,Kubernetes 将尝试通过终止运行在该节点上的 Pod 来解决网络连接问题。
公式释义
判断指定集群节点是否已经准备好接收工作负载状态,是则返回1,否则返回0。
最大可分配Pod数
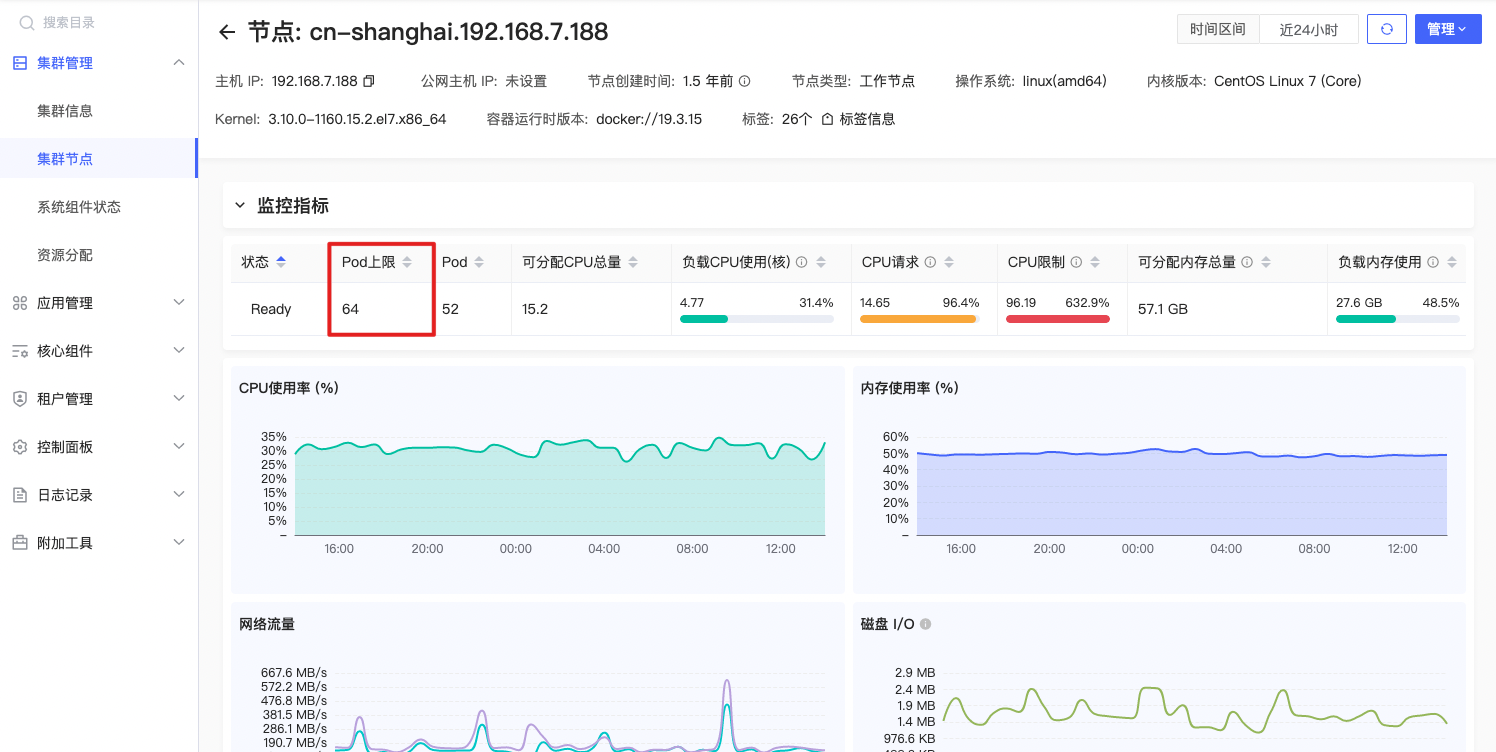
sum(kube_node_status_allocatable{origin_prometheus=~\"$origin_prometheus\",resource=\"pods\", unit=\"integer\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中最大可分配的应用Pod数量。查询中的过滤器”{resource=”pods”, unit=”integer”}”用于选择可分配的Pod资源,并过滤掉其他资源类型,如CPU和内存。查询使用”sum()”函数对每个节点上可分配Pod的数量进行求和,并按节点名称进行分组,以得到每个节点可分配Pod数量的时间序列。
“origin_prometheus”和”node”是PromQL查询中的变量,它们将在查询执行时动态替换为当前页面展示节点具体的值。
节点Pod数
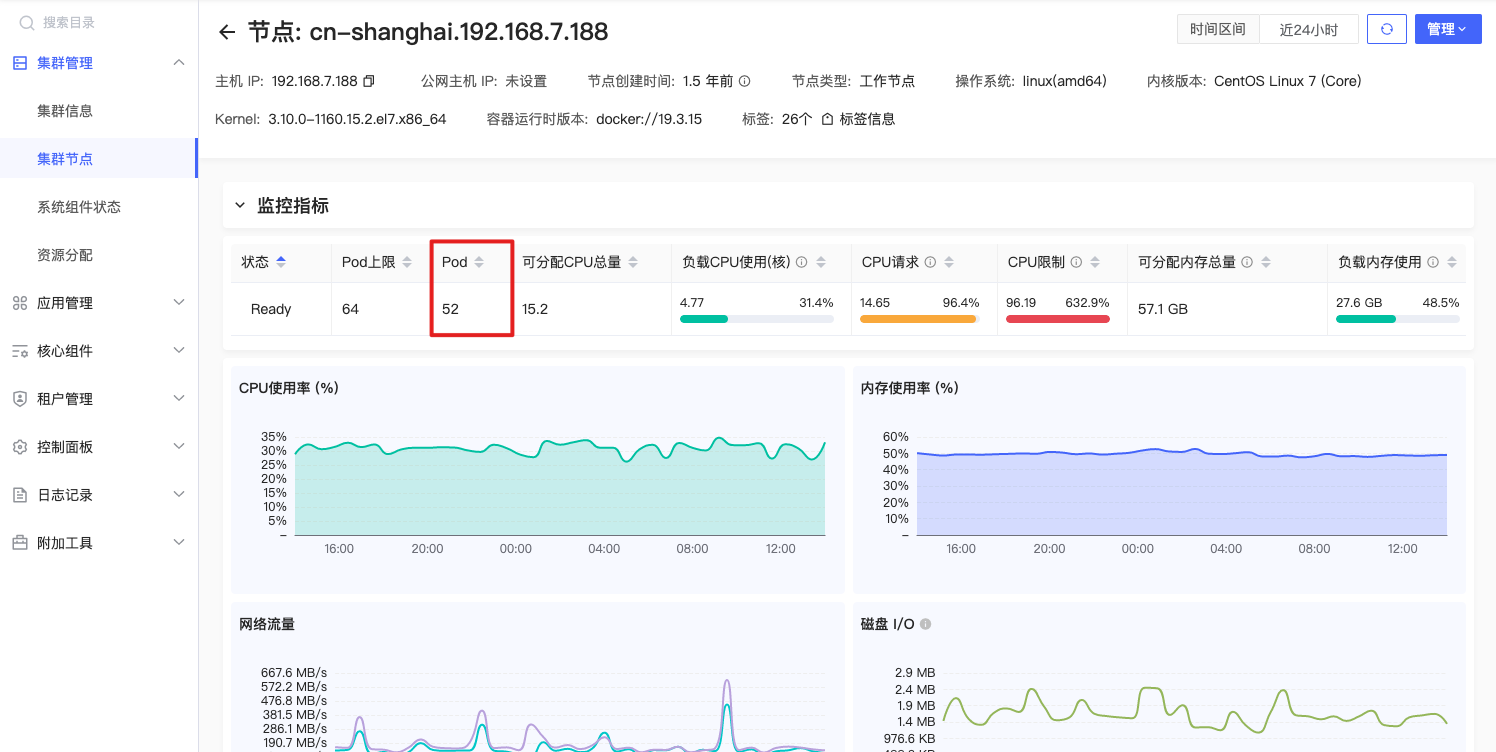
sum by (node,host_ip) (kube_pod_info{node=~"^$node$"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_info | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod的元数据信息。具体来说,它记录了每个Pod的名称、命名空间、IP地址和所在的节点等信息 |
公式释义
节点中正在运行的应用Pod数量
CPU可分配
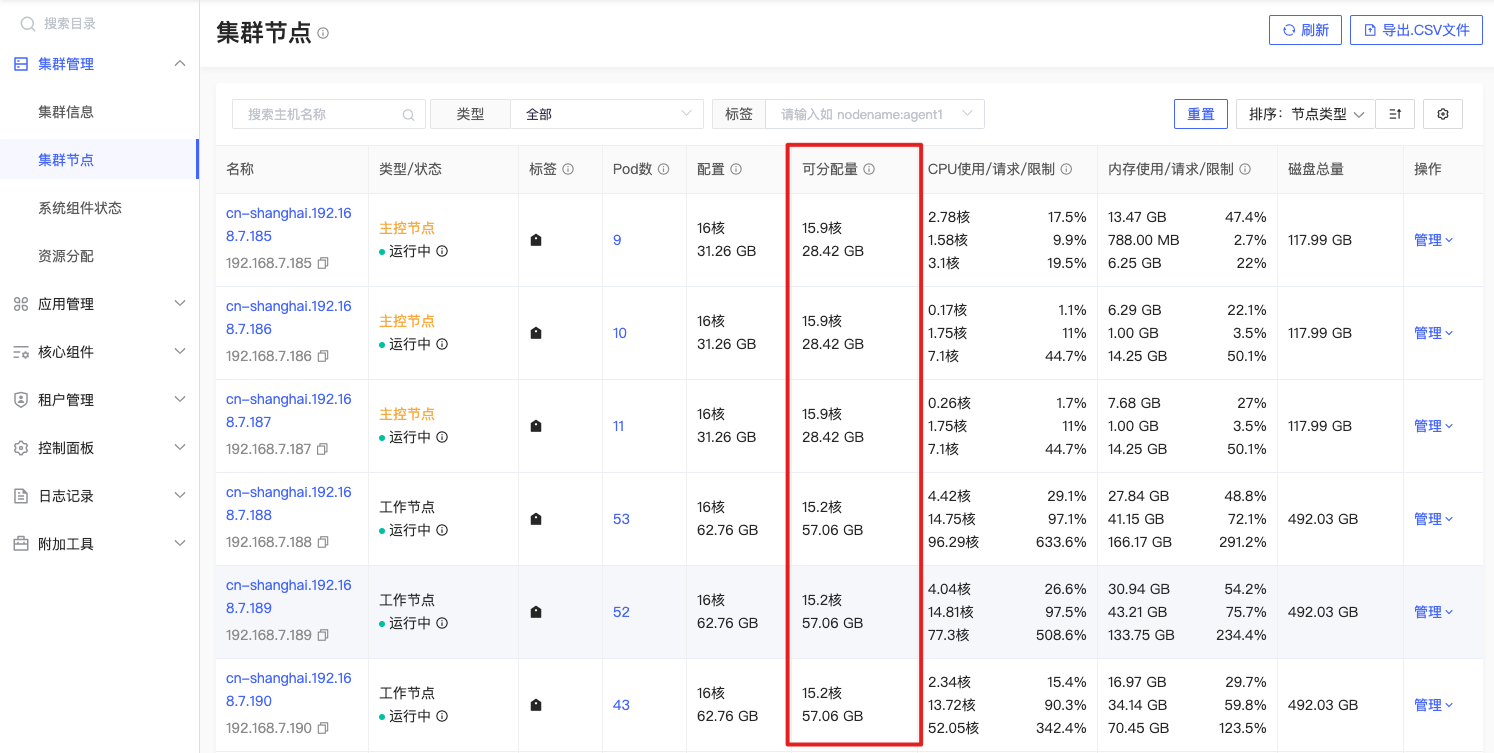
kube_node_status_allocatable{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\", node=~\"^$node$\"} - 0 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
包含以下标签
resource: 资源名称(例如 cpu、memory、ephemeral-storage 等)
node: 节点名称
公式释义
指定节点中可用于Pod调度的CPU总量
CPU使用
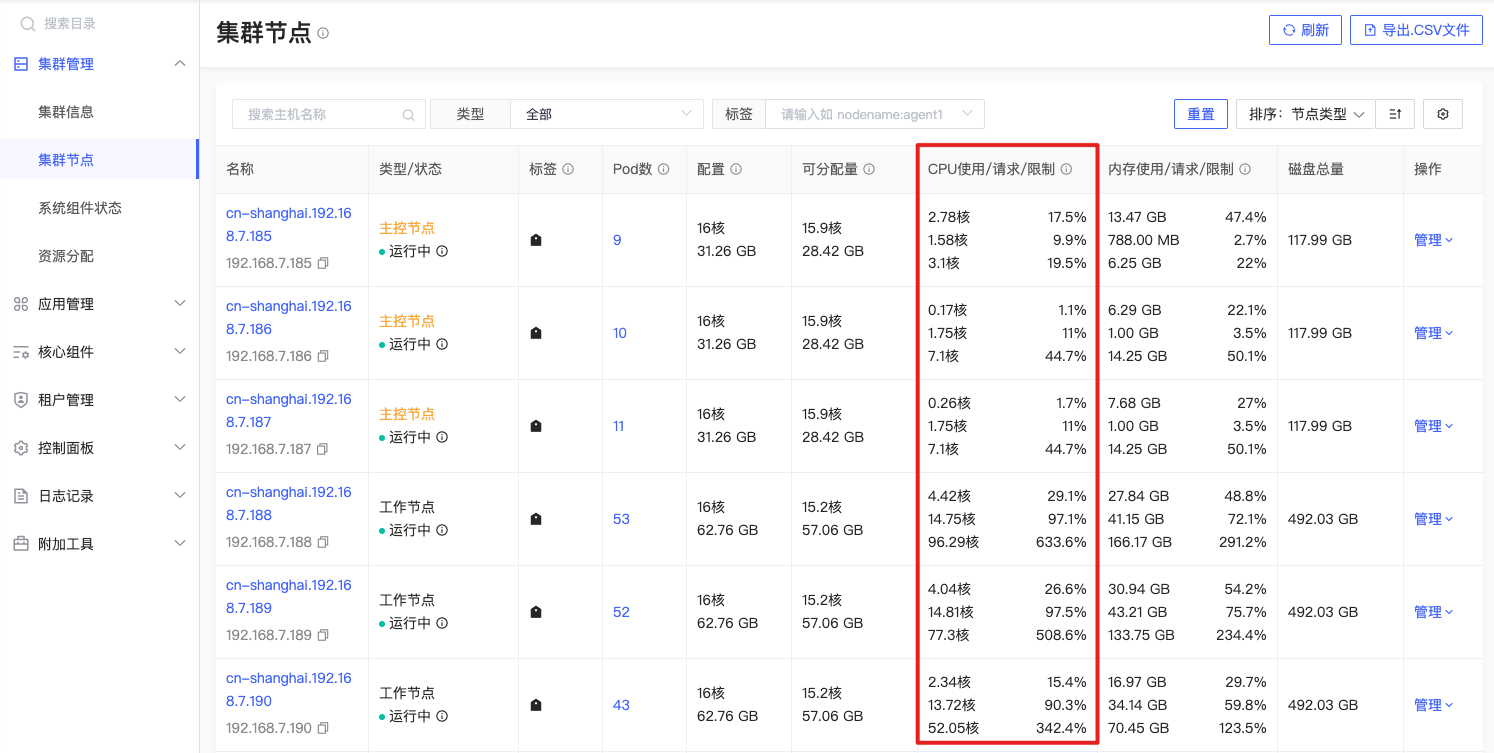
sum (irate(container_cpu_usage_seconds_total{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"}[2m])) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
公式释义
irate(container_cpu_usage_seconds_total{origin_prometheus=~\”$origin_prometheus\”,container!=\”\”,node=~\”^$node$\”}[2m]): 这是一个子查询,它返回每个容器在过去2分钟内使用的 CPU 时间量,以每秒为单位。
sum(…) by (node): 这是一个外部查询,它对子查询返回的指标进行求和,以计算每个节点在过去2分钟内使用的CPU时间总量。结果将按node标签进行分组,以便于识别每个节点的CPU使用情况。
CPU请求
sum(kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",node=~\"^$node$\"}) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
包含以下标签:
resource: 资源名称(例如 cpu、memory、ephemeral-storage 等)
namespace: Kubernetes 命名空间名称
pod: Pod 名称
container: 容器名称
公式释义
指定节点中所有运行容器在启动时CPU请求量之和
CPU限制
sum(kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",node=~\"^$node$\"}) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定节点中所有运行容器在启动时CPU限制量之和
内存可分配
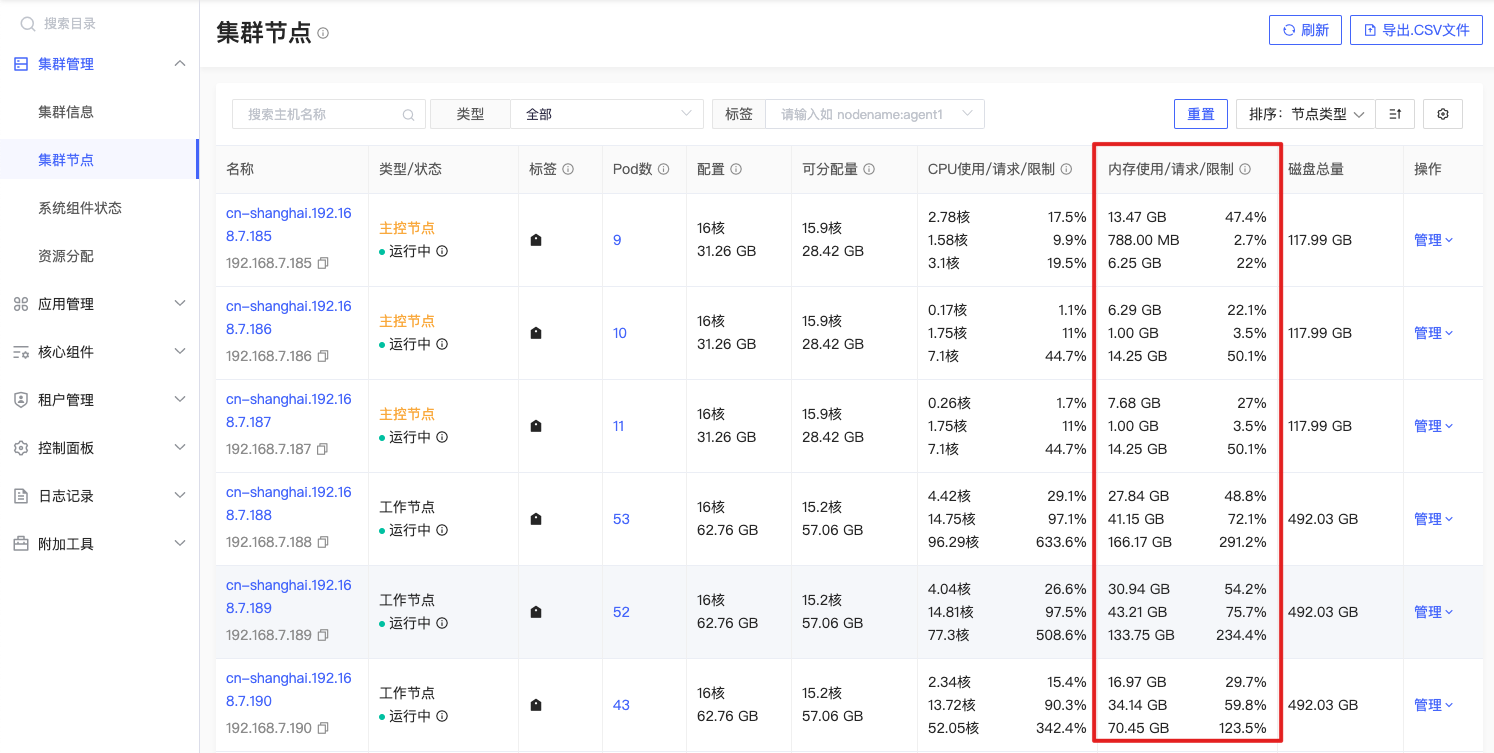
sum(kube_node_status_allocatable{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\", node=~\"^$node$\"}) by (node) - 0 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
包含以下标签
resource: 资源名称(例如 cpu、memory、ephemeral-storage 等)
node: 节点名称
公式释义
指定节点中可用于Pod调度的内存总量
内存使用
sum (container_memory_working_set_bytes{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"}) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_working_set_bytes | Kubernetes 中的一个指标,用于表示一个容器当前正在使用的物理内存大小,包括容器进程和它的所有子进程占用的内存 |
公式释义
指定节点中正在使用内存总量
内存请求
sum(cluster:namespace:pod_memory:active:kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",node=~\"^$node$\"}) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
包含以下标签:
resource: 资源名称(例如 cpu、memory、ephemeral-storage 等)
namespace: Kubernetes 命名空间名称
pod: Pod 名称
container: 容器名称
公式释义
指定节点中所有运行容器在启动时内存请求量之和
内存限制
sum(cluster:namespace:pod_memory:active:kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",node=~\"^$node$\"}) by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定节点中所有运行容器在启动时内存限制量之和。
CPU使用率
sum (irate(container_cpu_usage_seconds_total{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"}[2m]))by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 CPU使用/CPU可分配 %
CPU请求率
sum(cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 CPU请求/CPU可分配 %
CPU限制率
sum(cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 CPU限制/CPU可分配 %
内存使用率
sum (container_memory_working_set_bytes{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_working_set_bytes | Kubernetes 中的一个指标,用于表示一个容器当前正在使用的物理内存大小,包括容器进程和它的所有子进程占用的内存 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 内存使用/内存可分配 %
内存请求率
sum(cluster:namespace:pod_memory:active:kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 内存请求/内存可分配 %
内存限制率
sum(cluster:namespace:pod_memory:active:kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
指定节点中 内存限制/内存可分配 %
磁盘读取
max by (host_ip) (label_replace(rate(node_disk_read_bytes_total{}[2m]),\"host_ip\",\"$1\",\"instance\",\"(.*):9100\")) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_disk_read_bytes_total | 操作系统指标,它用于记录每个节点的磁盘读取操作的总字节数,以便可以监控节点的磁盘 I/O 活动情况 |
公式释义
使用 rate() 函数计算 node_disk_read_bytes_total 指标在过去2分钟内的磁盘读取速率;
使用 label_replace() 函数根据 instance 标签创建一个名为 host_ip 的新标签,增加数据可读性;
使用 max() 函数按照 host_ip 标签对结果进行分组,并返回每个分组中的最大值。
返回指定节点在过去2分钟内的最大磁盘分区的读取速率。
磁盘写入
max by (host_ip) (label_replace(rate(node_disk_written_bytes_total{}[2m]),\"host_ip\",\"$1\",\"instance\",\"(.*):9100\")) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_disk_written_bytes_total | 操作系统指标,用于表示节点磁盘上写入的字节数总量 |
公式释义
使用 rate() 函数计算 node_disk_written_bytes_total 指标在过去2分钟内的磁盘写入速率;
使用 label_replace() 函数根据 instance 标签创建一个名为 host_ip 的新标签,增加数据可读性;
使用 max() 函数按照 host_ip 标签对结果进行分组,并返回每个分组中的最大值。
返回指定节点在过去2分钟内的最大磁盘分区的写入速率。
分区使用率
max by (host_ip) ((label_replace(node_filesystem_size_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"},"host_ip","$1","instance","(.*):9100") - label_replace(node_filesystem_free_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"},"host_ip","$1","instance","(.*):9100")) / (label_replace(node_filesystem_avail_bytes {fstype!~"tmpfs|fuse(.*)|nfs(.*)"},"host_ip","$1","instance","(.*):9100") + label_replace(node_filesystem_size_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"},"host_ip","$1","instance","(.*):9100") - label_replace(node_filesystem_free_bytes{fstype!~"tmpfs|fuse(.*)|nfs(.*)"},"host_ip","$1","instance","(.*):9100"))) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_filesystem_size_bytes | 一个Prometheus指标,它用于记录节点上文件系统的总大小 |
| node_filesystem_avail_bytes | 一个Prometheus指标,表示指定节点上文件系统中可用的字节数。 |
| node_filesystem_free_bytes | 一个Prometheus指标,它用于记录节点上文件系统的可用空间 |
公式释义
计算出每个节点的磁盘使用率,并返回每个节点中的最大值。
节点CPU使用率趋势
sum (irate(container_cpu_usage_seconds_total{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"}[2m]))by (node) *100 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
所有节点中 容器使用CPU之和/节点可分配CPU%
节点内存使用率趋势
sum (container_memory_working_set_bytes{origin_prometheus=~\"$origin_prometheus\",container!=\"\",node=~\"^$node$\"})by (node) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_working_set_bytes | Kubernetes 中的一个指标,用于表示一个容器当前正在使用的物理内存大小,包括容器进程和它的所有子进程占用的内存 |
| kube_node_status_allocatable | Kubernetes 中的指标名称,用于记录Kubernetes节点的可分配资源量。包含节点上可用的CPU资源量、内存资源量、临时存储资源量、可用的Pod数量 |
公式释义
所有节点中 容器使用内存之和/节点可分配内存%
节点流入流出带宽趋势
- 流入
sum (irate(container_network_receive_bytes_total{origin_prometheus=~\"$origin_prometheus\",node=~\"^$node$\"}[2m]))by (node) *8 |
- 流出
sum (irate(container_network_transmit_bytes_total{origin_prometheus=~\"$origin_prometheus\",node=~\"^$node$\"}[2m]))by (node) *8 |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_network_receive_bytes_total | Prometheus指标,用于表示容器接收的字节数。帮助用户了解容器的网络使用情况 |
| container_network_transmit_bytes_total | Prometheus指标,用于表示容器的网络传输字节数。可以用于衡量容器的网络活动情况 |
公式释义
- 计算最近2分钟内接收网络字节数的平均速率,单位bits/s
- 计算最近2分钟内发送网络字节数的平均速率,单位
节点磁盘I/O趋势
- 读取
rate(node_disk_read_bytes_total{job=\"node-exporter\", instance=\"$instance\", device=~\"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|dasd.+)\"}[$__interval]) |
- 写入
rate(node_disk_written_bytes_total{job=\"node-exporter\", instance=\"$instance\", device=~\"(/dev/)?(mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|dasd.+)\"}[$__interval]) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| node_disk_read_bytes_total | 操作系统指标,它用于记录每个节点的磁盘读取操作的总字节数,以便可以监控节点的磁盘 I/O 活动情况 |
| node_disk_written_bytes_total | 操作系统指标,用于表示节点磁盘上写入的字节数总量 |
公式释义
- 指定时间区间内节点磁盘读取速率的平均值(单位是每秒钟读取的字节数)。
- rate()函数计算指定时间范围内时间序列数据的速率,这里是节点磁盘的读取速率。
- instance 表示节点实例名称,device 用于过滤指定的磁盘设备名称。[$__interval] 表示查询时间区间,它是一个 PromQL 内置变量,用于指定查询时间范围。
- 指定时间区间内节点磁盘的写入速率。
- instance 表示节点实例名称,device 用于过滤指定的磁盘设备名称。[$__interval] 表示查询时间区间,它是一个 PromQL 内置变量,用于指定查询时间范围。
安全组
应用Pod数
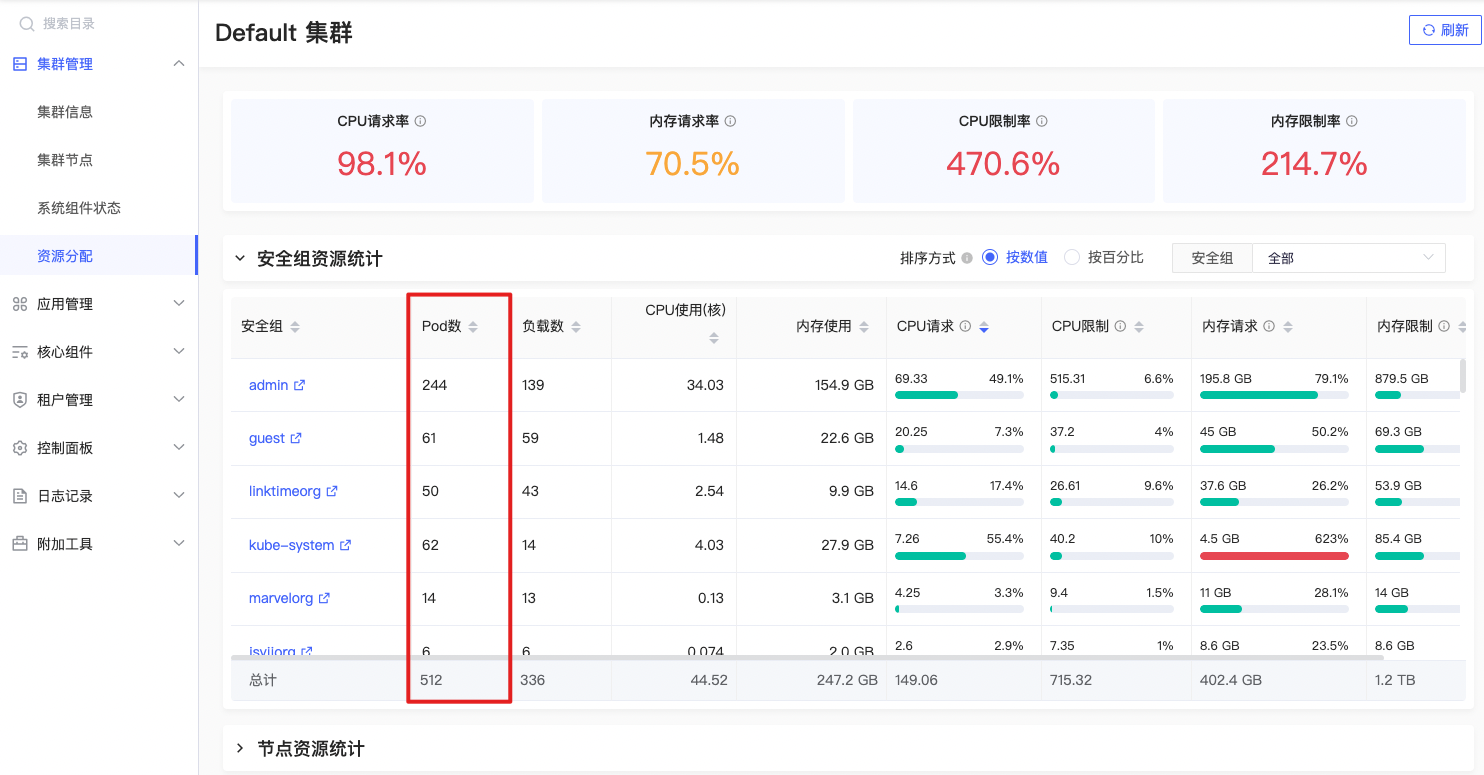
sum(kube_pod_owner{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\",job=\"kube-state-metrics\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_owner | 自定义指标,用于了解Pod所属的OwnerKind和OwnerName |
公式释义
该指标按命名空间分组,并返回每个命名空间下应用Pod数量
应用负载数
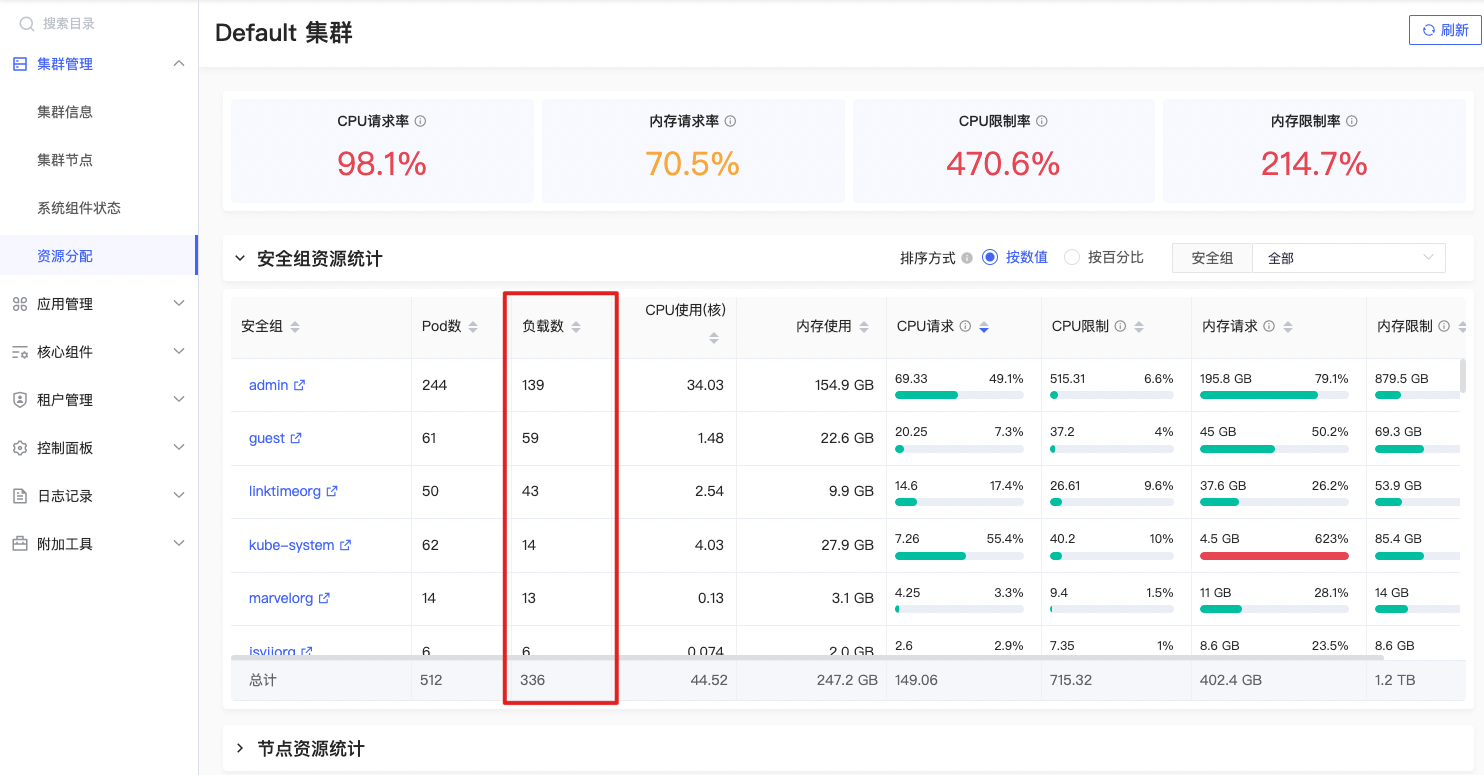
count(avg(namespace_workload_pod:kube_pod_owner:relabel{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (workload, namespace)) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| namespace_workload_pod:kube_pod_owner:relabel | 标签筛选,从Kubernetes API获取每个Pod的工作负载标签(例如 deployment 或 statefulset)以及所属的命名空间 |
公式释义
指定命名空间中应用负载数量
CPU使用
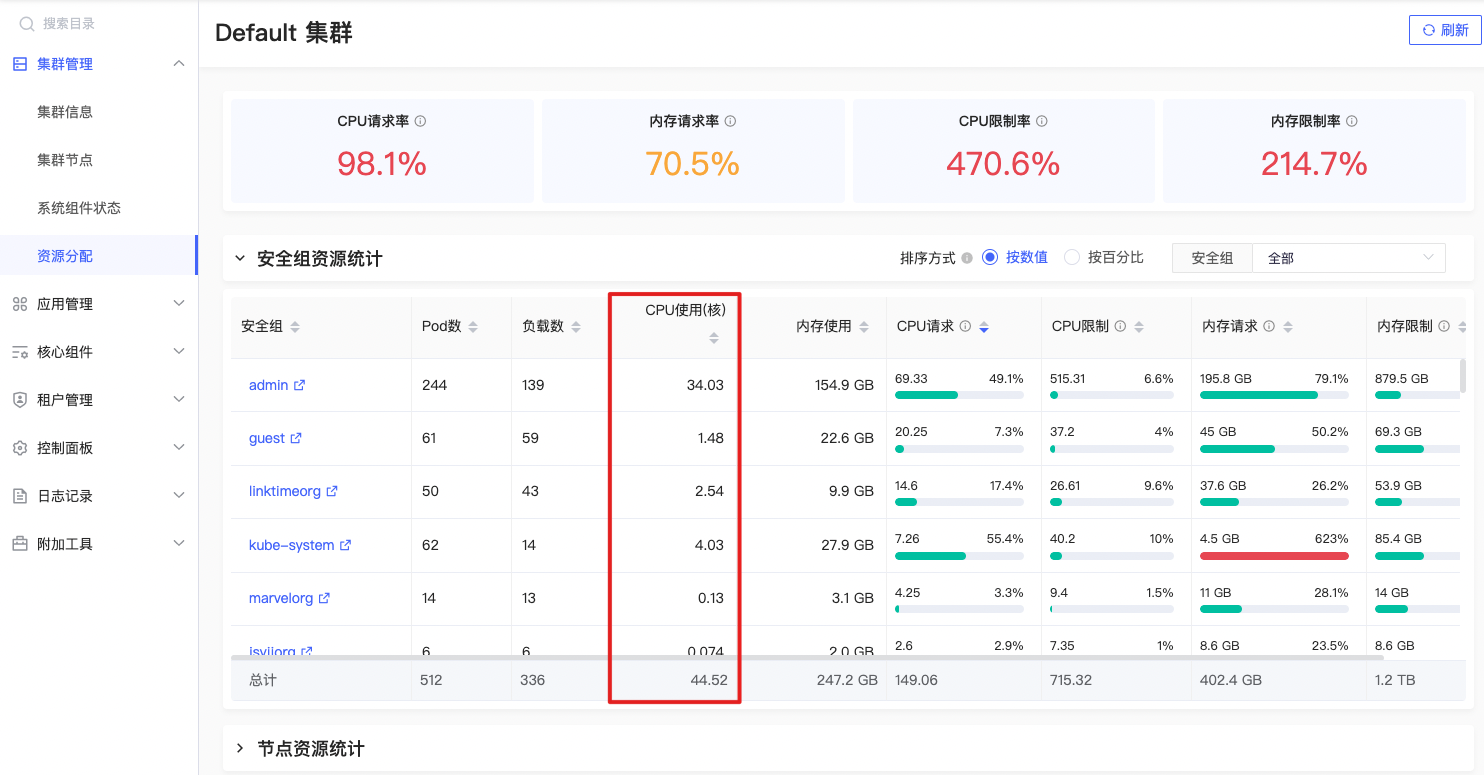
sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
公式释义
指定安全组下所有运行容器使用CPU
CPU请求
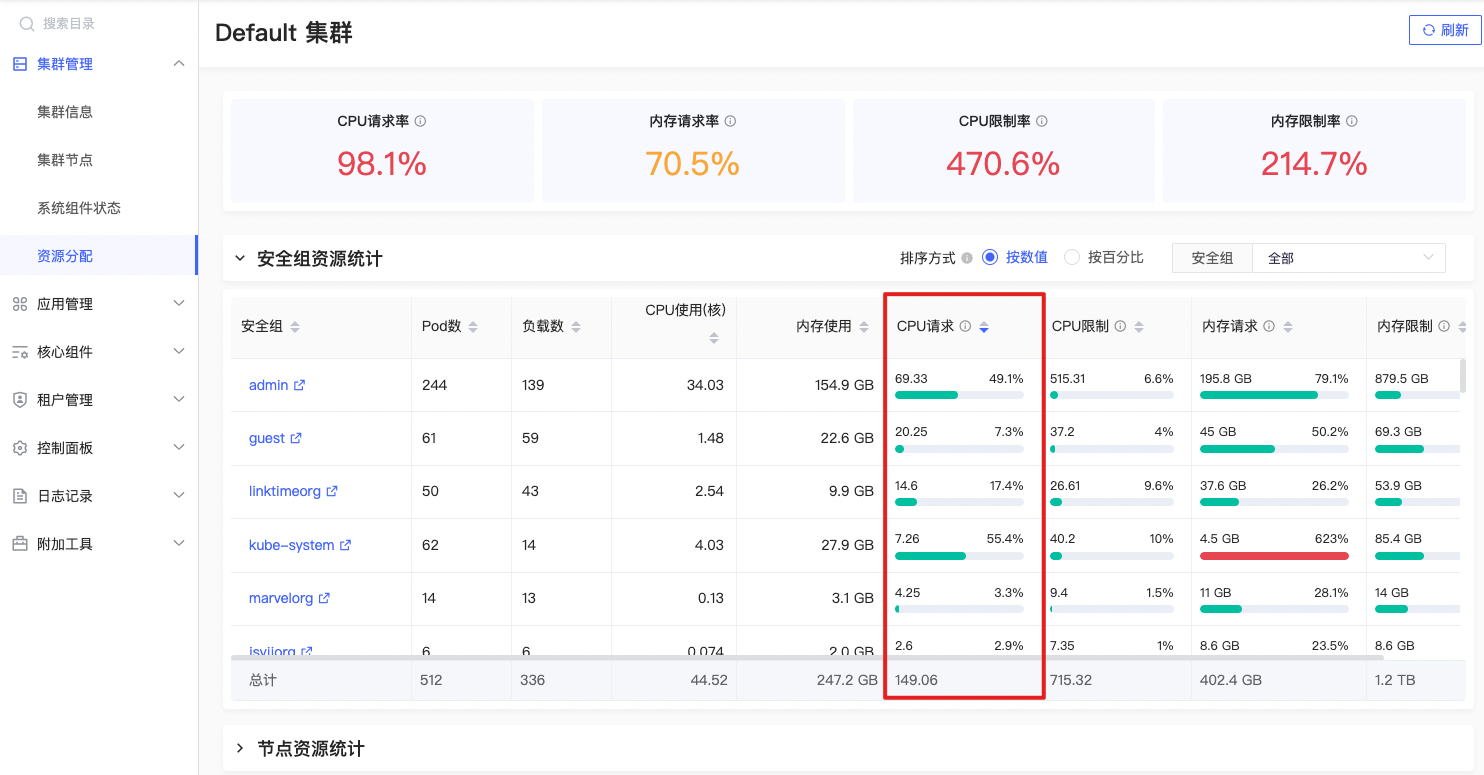
sum(namespace_cpu:kube_pod_container_resource_requests:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
指定命名空间下所有容器的CPU请求总量
CPU请求率
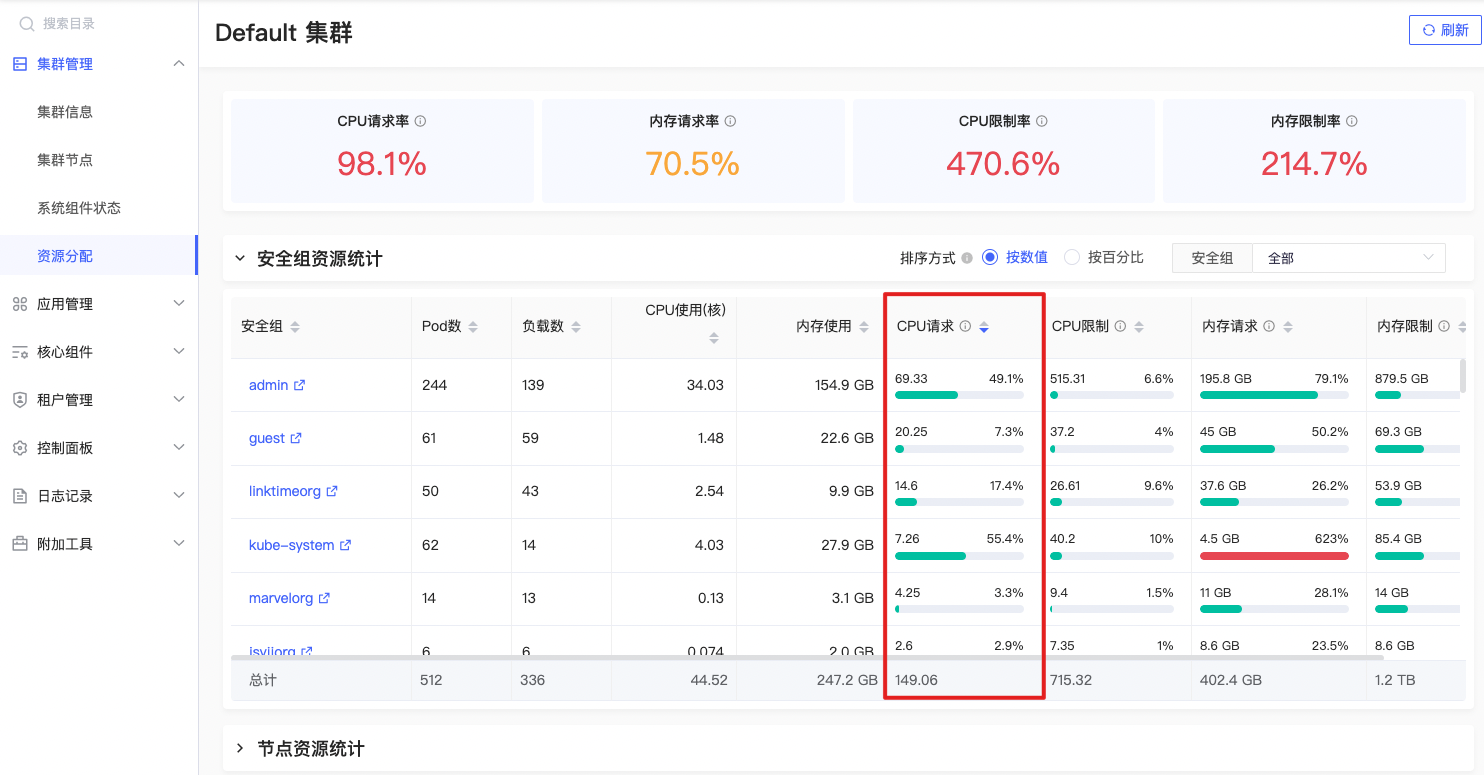
sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) / sum(namespace_cpu:kube_pod_container_resource_requests:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
指定命名空间下所有容器的CPU使用总量 / 总请求 %
CPU限制

sum(namespace_cpu:kube_pod_container_resource_limits:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定命名空间中所有容器CPU资源限制的总和
CPU限制率
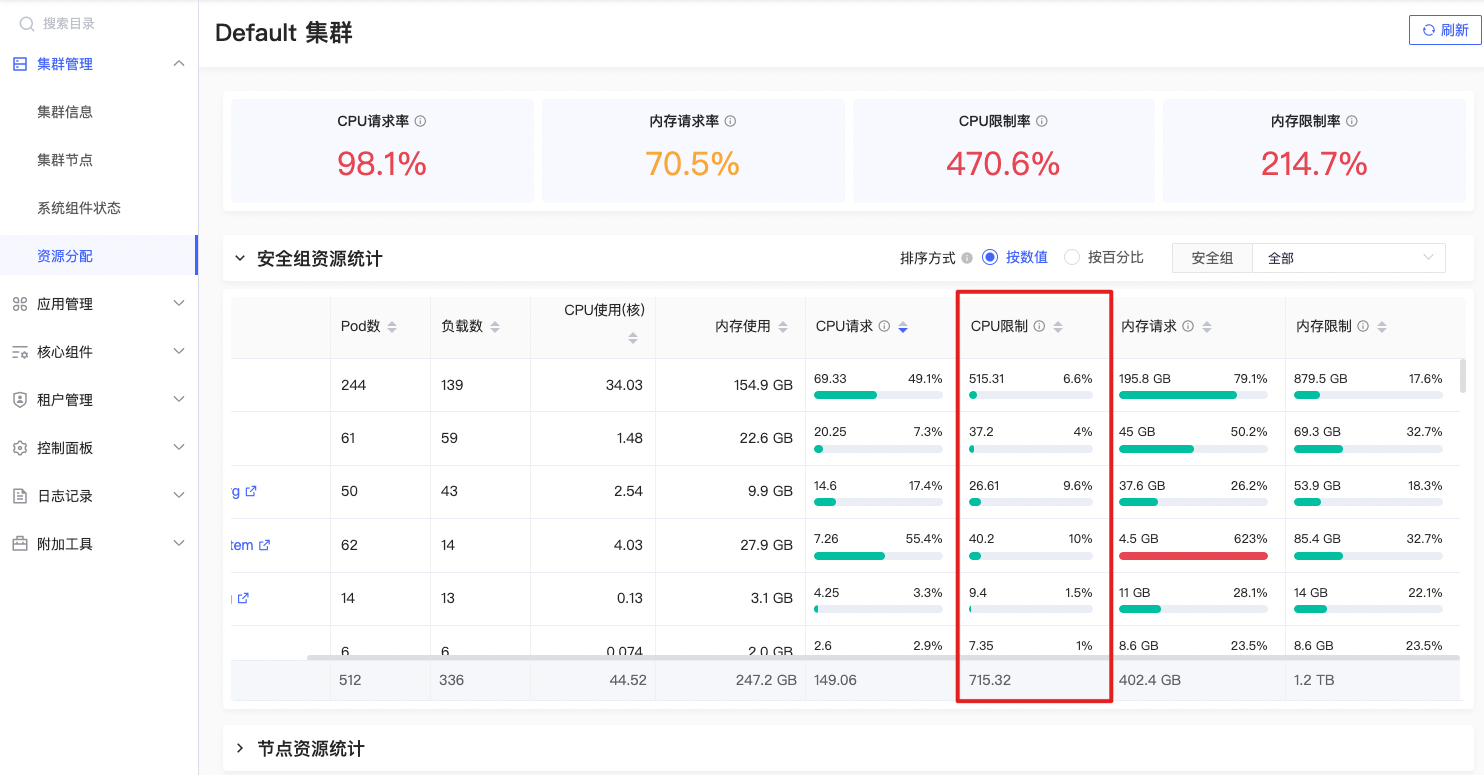
sum(node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) / sum(namespace_cpu:kube_pod_container_resource_limits:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定命名空间下所有容器的CPU使用总量 / 总限制 %
内存使用
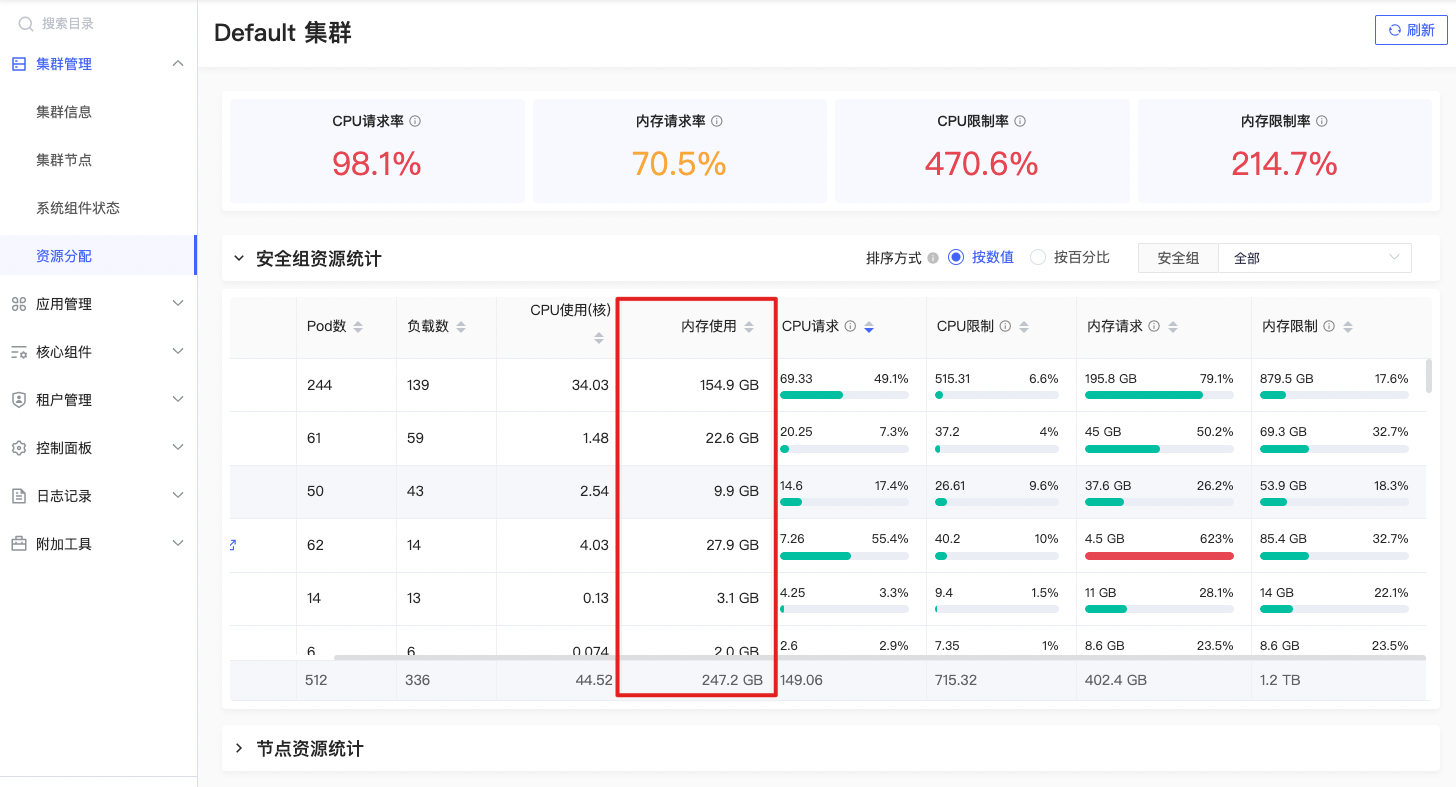
sum(container_memory_rss{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\", job=\"kubelet\", metrics_path=\"/metrics/cadvisor\", container!=\"\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_rss | Prometheus指标,用于记录容器进程的Resident Set Size(RSS),即进程占用的物理内存大小。单位为字节。 |
公式释义
指定命名空间下所有容器的RSS内存使用量的总和
内存请求
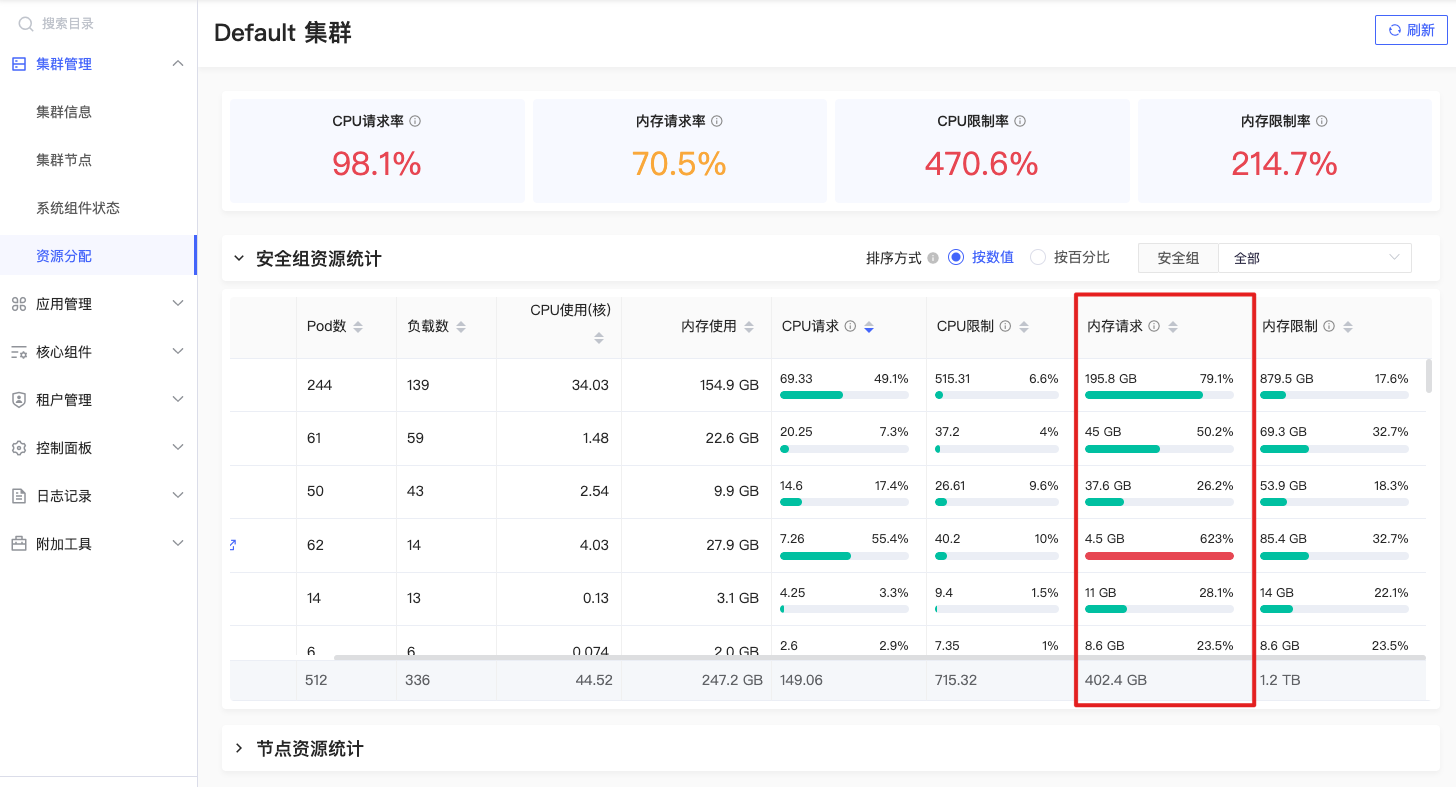
sum(namespace_memory:kube_pod_container_resource_requests:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
指定命名空间下所有容器的内存资源请求总和
内存请求率
sum(container_memory_rss{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\", job=\"kubelet\", metrics_path=\"/metrics/cadvisor\", container!=\"\"}) by (namespace) / sum(namespace_memory:kube_pod_container_resource_requests:sum) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_rss | Prometheus指标,用于记录容器进程的Resident Set Size(RSS),即进程占用的物理内存大小。单位为字节。 |
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
命名空间内所有容器的 RSS(Resident Set Size)内存占用的总和 除以 命名空间内所有容器请求的内存总量的总和,以此来估算命名空间内所有容器的内存使用率。
内存限制
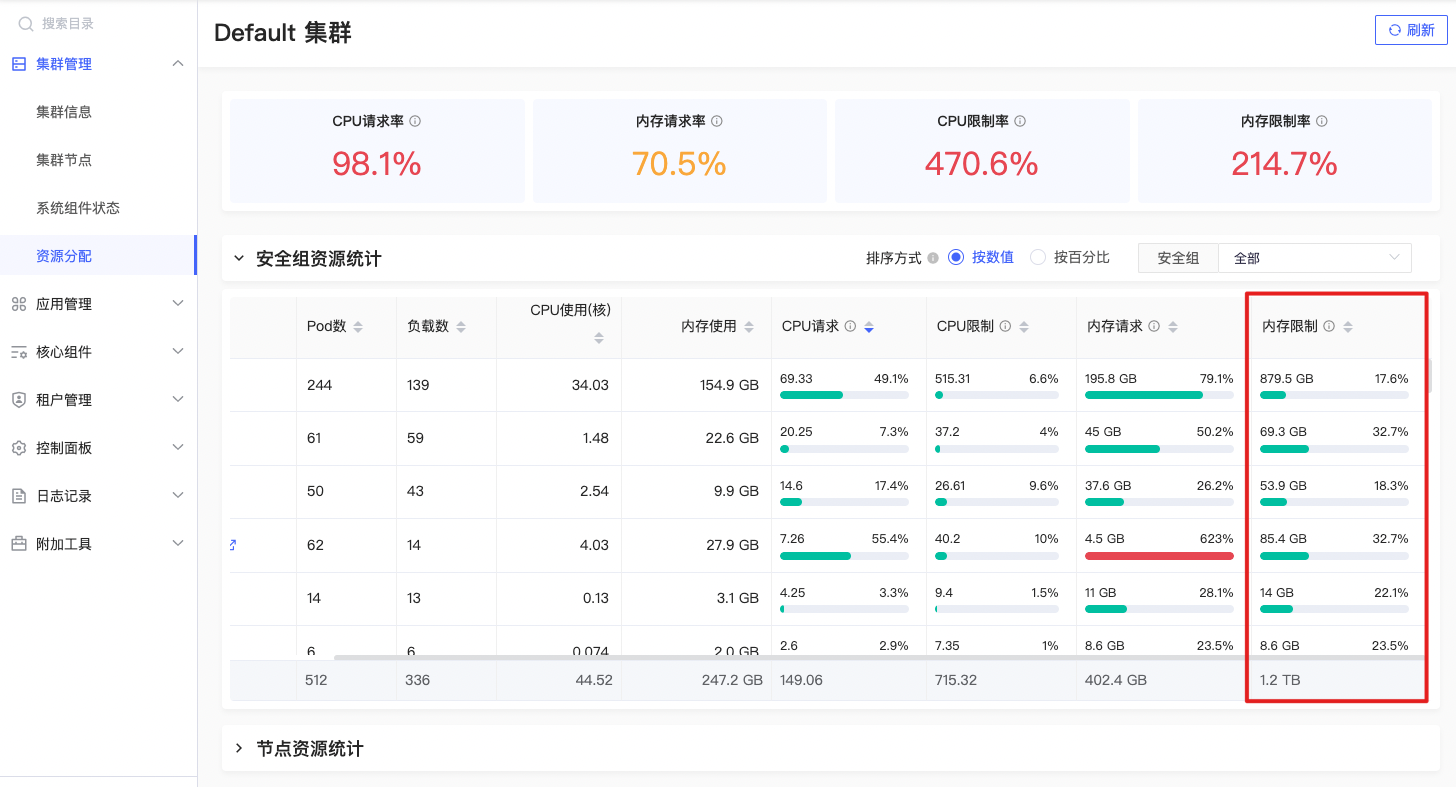
sum(namespace_memory:kube_pod_container_resource_limits:sum{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\"}) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定命名空间下所有容器限制量之和
内存限制率
sum(container_memory_rss{prometheus=\"admin/kps-prometheus\",namespace=~\"$namespace\", job=\"kubelet\", metrics_path=\"/metrics/cadvisor\", container!=\"\"}) by (namespace) / sum(namespace_memory:kube_pod_container_resource_limits:sum) by (namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_rss | Prometheus指标,用于记录容器进程的Resident Set Size(RSS),即进程占用的物理内存大小。单位为字节。 |
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定命名空间下运行容器内存 使用量之和 / 限制量之和 %
应用Pod
CPU使用趋势
sum(\n node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster=\"$cluster\", namespace=\"$namespace\"}\n * on(namespace,pod)\n group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{cluster=\"$cluster\", namespace=\"$namespace\", workload=\"$workload\", workload_type=\"$type\"}\n) by (pod) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| namespace_workload_pod:kube_pod_owner:relabel | 标签筛选,从Kubernetes API获取每个Pod的工作负载标签(例如 deployment 或 statefulset)以及所属的命名空间 |
公式释义
指定应用负载下所有Pod的CPU使用趋势
内存使用趋势
sum(\n container_memory_working_set_bytes{cluster=\"$cluster\", namespace=\"$namespace\", container!=\"\", image!=\"\"}\n * on(namespace,pod)\n group_left(workload, workload_type) namespace_workload_pod:kube_pod_owner:relabel{cluster=\"$cluster\", namespace=\"$namespace\", workload=\"$workload\", workload_type=\"$type\"}\n) by (pod) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
| namespace_workload_pod:kube_pod_owner:relabel | 标签筛选,从Kubernetes API获取每个Pod的工作负载标签(例如 deployment 或 statefulset)以及所属的命名空间 |
公式释义
指定应用负载下每个Pod的CPU使用趋势。
workload_type:Pod 所属的 Kubernetes 工作负载类型,例如 Deployment、StatefulSet 等。
namespace_workload_pod:kube_pod_owner:relabel:用于确定每个 Pod 所属的 Kubernetes 工作负载的名称。
聚合应用Pod中容器名称、容器镜像名称不为空的容器内存使用量,若容器镜像为空,则该容器的内存使用量不计算在内。
网络流入趋势
sum(irate(container_network_receive_bytes_total{job=\"kubelet\", metrics_path=\"/metrics/cadvisor\", cluster=\"$cluster\", namespace=\"$namespace\"}[$__interval])\n* on (namespace,pod)\ngroup_left(workload,workload_type) namespace_workload_pod:kube_pod_owner:relabel{cluster=\"$cluster\", namespace=\"$namespace\", workload=~\"$workload\", workload_type=\"$type\"}) by (pod))\n |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_network_receive_bytes_total | Prometheus指标,用于表示容器接收的字节数。帮助用户了解容器的网络使用情况 |
| namespace_workload_pod:kube_pod_owner:relabel | 标签筛选,从Kubernetes API获取每个Pod的工作负载标签(例如 deployment 或 statefulset)以及所属的命名空间 |
公式释义
指定应用负载中 每个Pod指定时间范围内接收的网络流量总量
- irate() 函数计算每秒钟接收的网络流量,并过滤掉指定集群(cluster)和命名空间(namespace)以外的数据。
- group_left() 函数将结果按照 namespace 和 pod 分组,与标签为 kube_pod_owner 的指标关联起来。
- sum() 函数按照 pod 进行聚合,返回每个 Pod 在指定时间范围内接收的网络流量总量。
网络流出趋势
(sum(irate(container_network_transmit_bytes_total{job=\"kubelet\", metrics_path=\"/metrics/cadvisor\", cluster=\"$cluster\", namespace=\"$namespace\"}[$__interval])\n* on (namespace,pod)\ngroup_left(workload,workload_type) namespace_workload_pod:kube_pod_owner:relabel{cluster=\"$cluster\", namespace=\"$namespace\", workload=~\"$workload\", workload_type=\"$type\"}) by (pod))\n |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_network_receive_bytes_total | Prometheus指标,用于表示容器接收的字节数。帮助用户了解容器的网络使用情况 |
| namespace_workload_pod:kube_pod_owner:relabel | 标签筛选,从Kubernetes API获取每个Pod的工作负载标签(例如 deployment 或 statefulset)以及所属的命名空间 |
公式释义
指定应用负载中 每个Pod指定时间范围内网络传输的总字节数
- irate(…): 将 container_network_transmit_bytes_total 转化为一个时间序列向量,每个向量元素表示一秒内的容器网络传输字节数。
- on (namespace,pod) group_left(workload,workload_type): 按照 namespace 和 pod 进行分组,将与每个 pod 相关的标签(workload 和 workload_type)合并到输出的时间序列中。
- namespace_workload_pod:kube_pod_owner:relabel: 使用 Prometheus 的 label_replace 函数,将 kube_pod_owner 标签中的 owner 转换为 pod 名称,这个标签表示 pod 的拥有者(Deployment、StatefulSet 等)。
- sum(): 将聚合后的结果按照 pod 进行求和,得到每个 pod 在一段时间内传输的总字节数
容器
容器镜像名称
sum by (namespace, container, image) (label_replace(kube_pod_container_info{origin_prometheus=~\"\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"} * on(namespace, pod, cluster) group_left() max by(namespace, pod, cluster) (kube_pod_status_phase{phase=~\"Running\",pod !~ \"$IgnoredPodRegex\"} == 1), \"image\", \"$2\", \"image\", \"(.*)/(.*)\")) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_info | 获取每个容器使用的CPU和内存量 |
| kube_pod_status_phase | 确定应用Pod运行状态 |
公式释义
将每个容器的CPU和内存使用量进行聚合,按照 namespace、container 和 image 进行分组。
IgnoredPodRegex被忽略的应用Pod包括:hive-on-spark.*|sparkapplication.*|node-shell.*|.*-onelogin-register
期望实例数
sum by (namespace, container) (kube_pod_container_info{origin_prometheus=~\"\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"} * on(namespace, pod, cluster) group_left() max by(namespace, pod, cluster) (kube_pod_status_phase{phase=~\"Running\",pod !~ \"$IgnoredPodRegex\"} == 1)) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_info | 获取每个容器使用的CPU和内存量 |
| kube_pod_status_phase | 确定应用Pod运行状态 |
公式释义
将每个容器的期望实例数进行聚合,按照 namespace、container 进行分组。
IgnoredPodRegex被忽略的应用Pod包括:hive-on-spark.*|sparkapplication.*|node-shell.*|.*-onelogin-register
运行实例数
sum by (container, namespace) (kube_pod_container_status_running{origin_prometheus=~\"\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_running | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的运行状态 |
公式释义
计算每个容器在每个命名空间内正在运行的数量,将结果按容器名和命名空间进行分组
等待实例数
sum by (container, namespace) (kube_pod_container_status_waiting{origin_prometheus=~\"\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_waiting | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的等待状态 |
公式释义
返回所有状态为等待中的容器数量,并按容器名称和命名空间进行分组
终结实例数
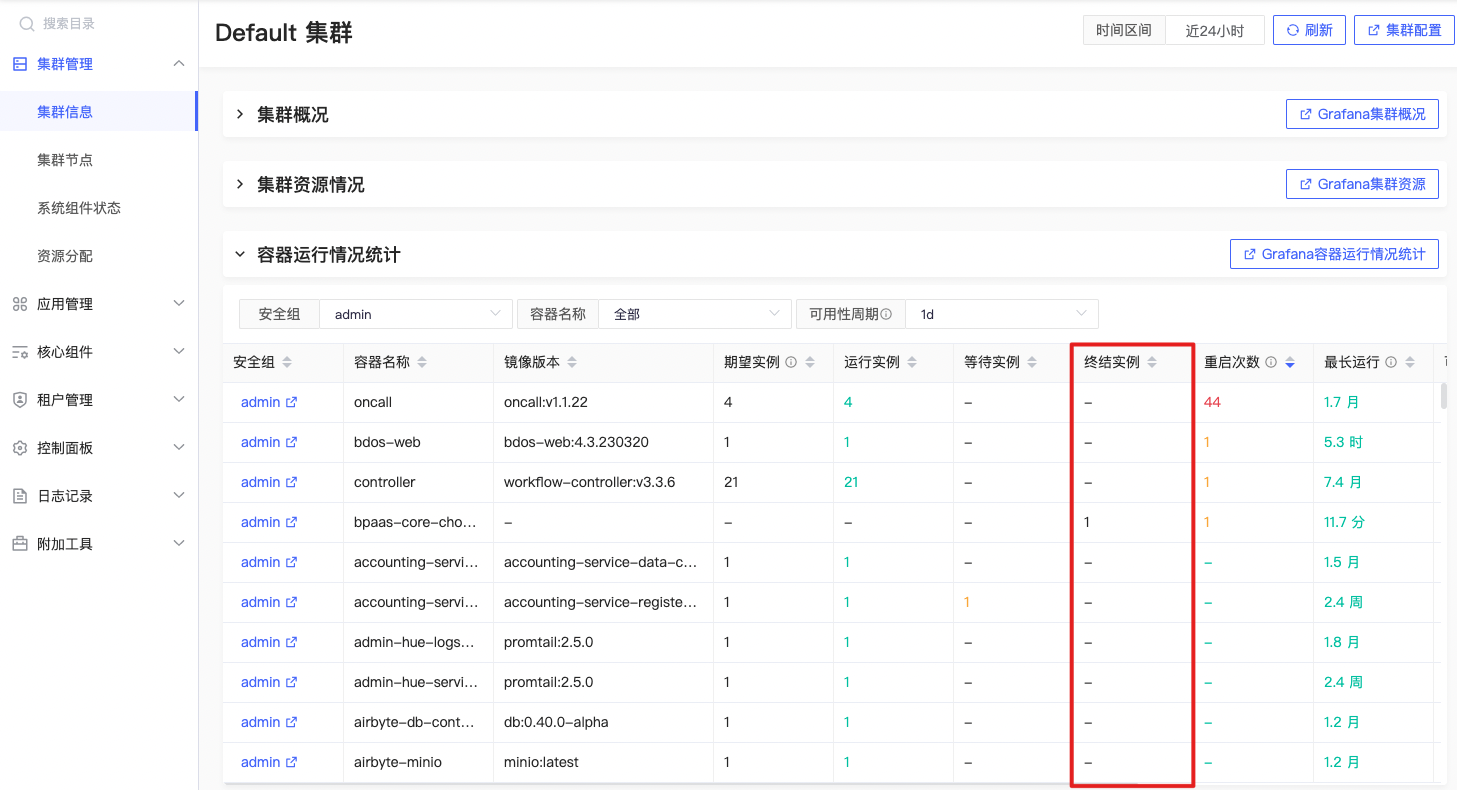
sum by (container, namespace) (kube_pod_container_status_terminated{origin_prometheus=~\"\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_terminated | Kubernetes 中的指标名称,它用于记录Kubernetes中pod中容器的终止状态 |
公式释义
指定命名空间中特定容器的被终止的Pod容器的数量
重启次数
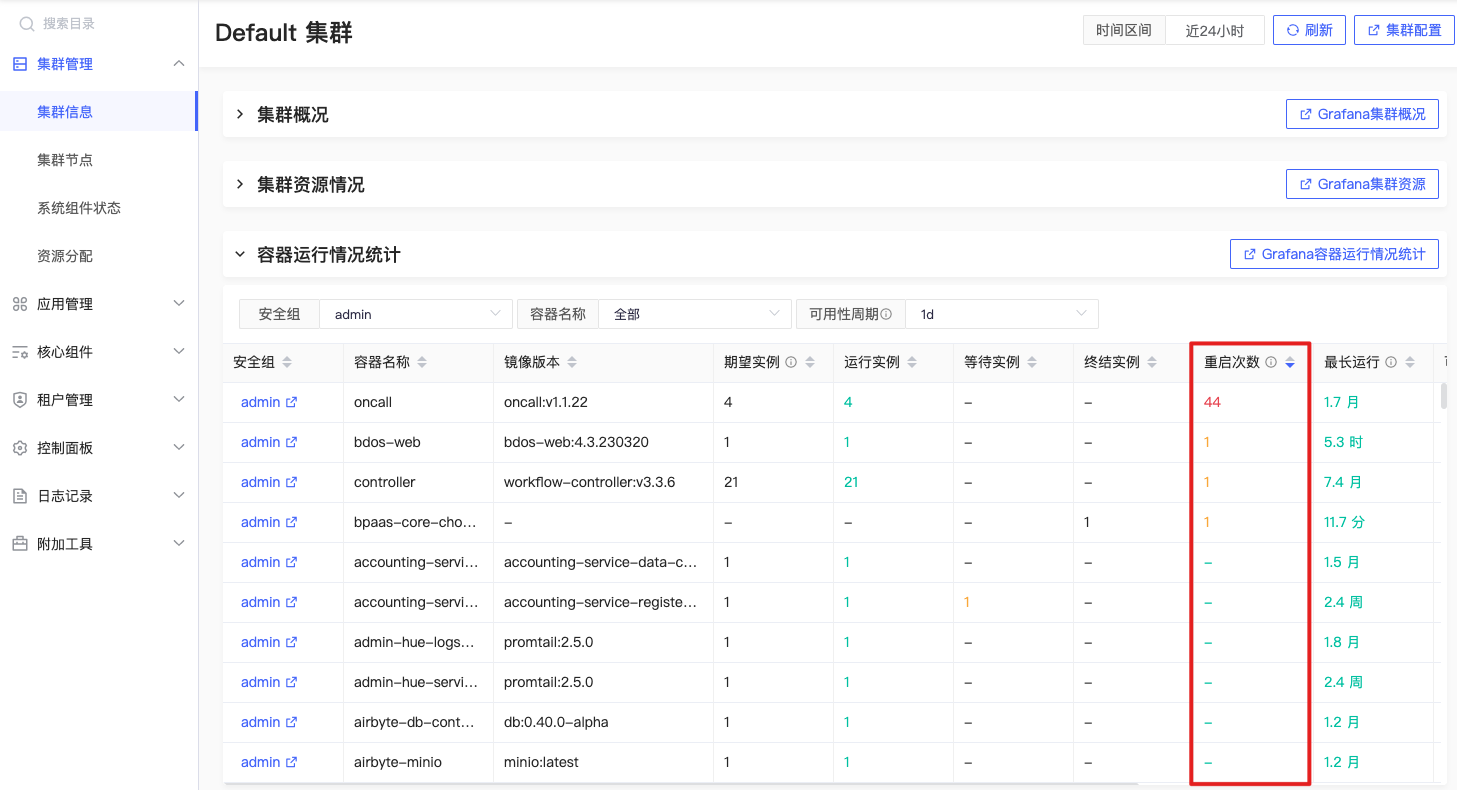
sum by (container, namespace) (changes(kube_pod_container_status_restarts_total{origin_prometheus=~\"$origin_prometheus\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}[$__range])) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_terminated | Kubernetes 中的指标名称,它用于记录Kubernetes中pod中容器的终止状态 |
公式释义
指定时间段内,同一容器名称的容器总重启次数
__range:24h,默认计算24小时内重启次数,用户可根据页面“时间区间”调整统计时长
最长运行
max by (container, namespace) (time() - (kube_pod_container_state_started{pod!~"$IgnoredPodRegex",container =~"$Container",container!="",container!="POD",namespace="$NameSpace"})) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_state_started | Kubernetes指标,记录了容器启动时间戳,即kubelet第一次观察到该容器正在运行的时间。该指标通常用于计算容器的运行时间或者容器的稳定性 |
公式释义
指定命名空间中,指定容器的最长运行时间。
可用性周期
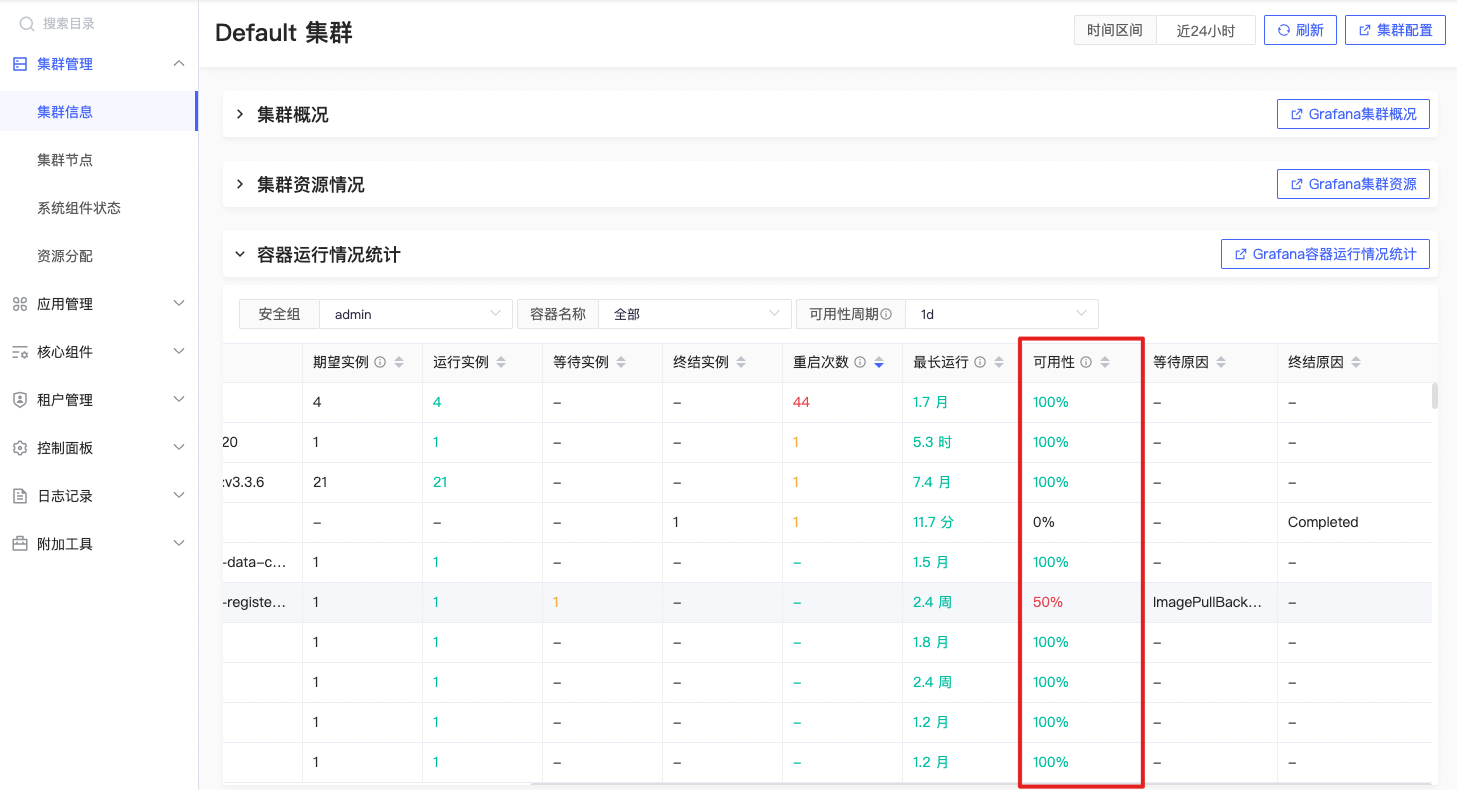
avg(\n avg_over_time((sum without ()(kube_pod_container_status_ready{origin_prometheus=~\"$origin_prometheus\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}) \n / \n count without ()(kube_pod_container_status_ready{origin_prometheus=~\"$origin_prometheus\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}))[$Duration:3h])\n) by (container, namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_terminated | Kubernetes 中的指标名称,它用于记录Kubernetes中pod中容器的终止状态 |
公式释义
指定时间段内,在每个容器和命名空间级别上的平均容器处于就绪状态的时间的百分比。
等待原因
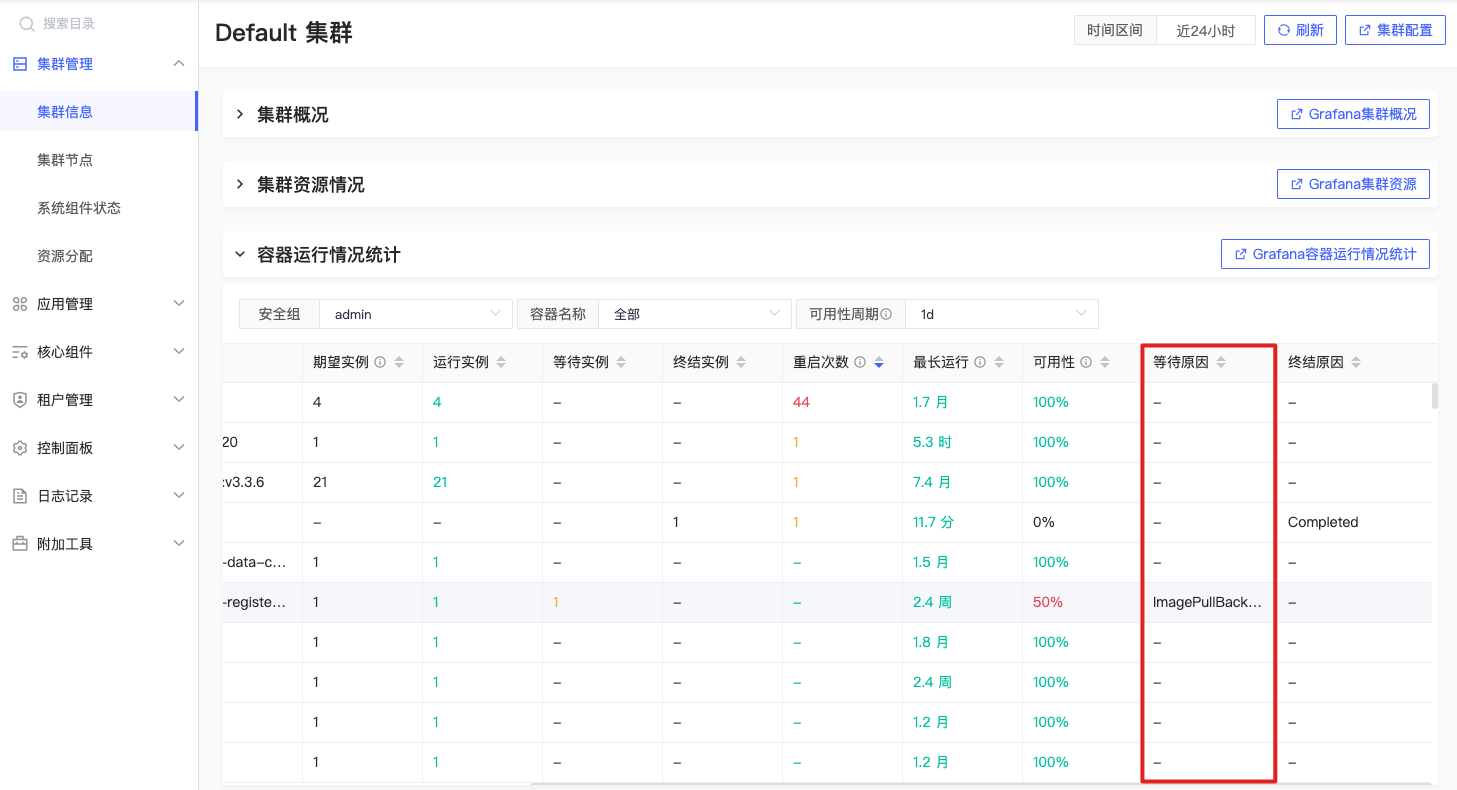
max by (container, namespace, waiting_reason) (label_replace(kube_pod_container_status_waiting_reason{origin_prometheus=~\"$origin_prometheus\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}, \"waiting_reason\", \"$1\", \"reason\", \"(.*)\")) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_waiting_reason | 一个标签名称,用于标识 Kubernetes Pod 中容器处于等待状态的原因 |
公式释义
查找特定的 Kubernetes Pod 容器中等待状态的最长时间(最大等待时间),按照容器名称、命名空间以及等待原因分组
终结原因
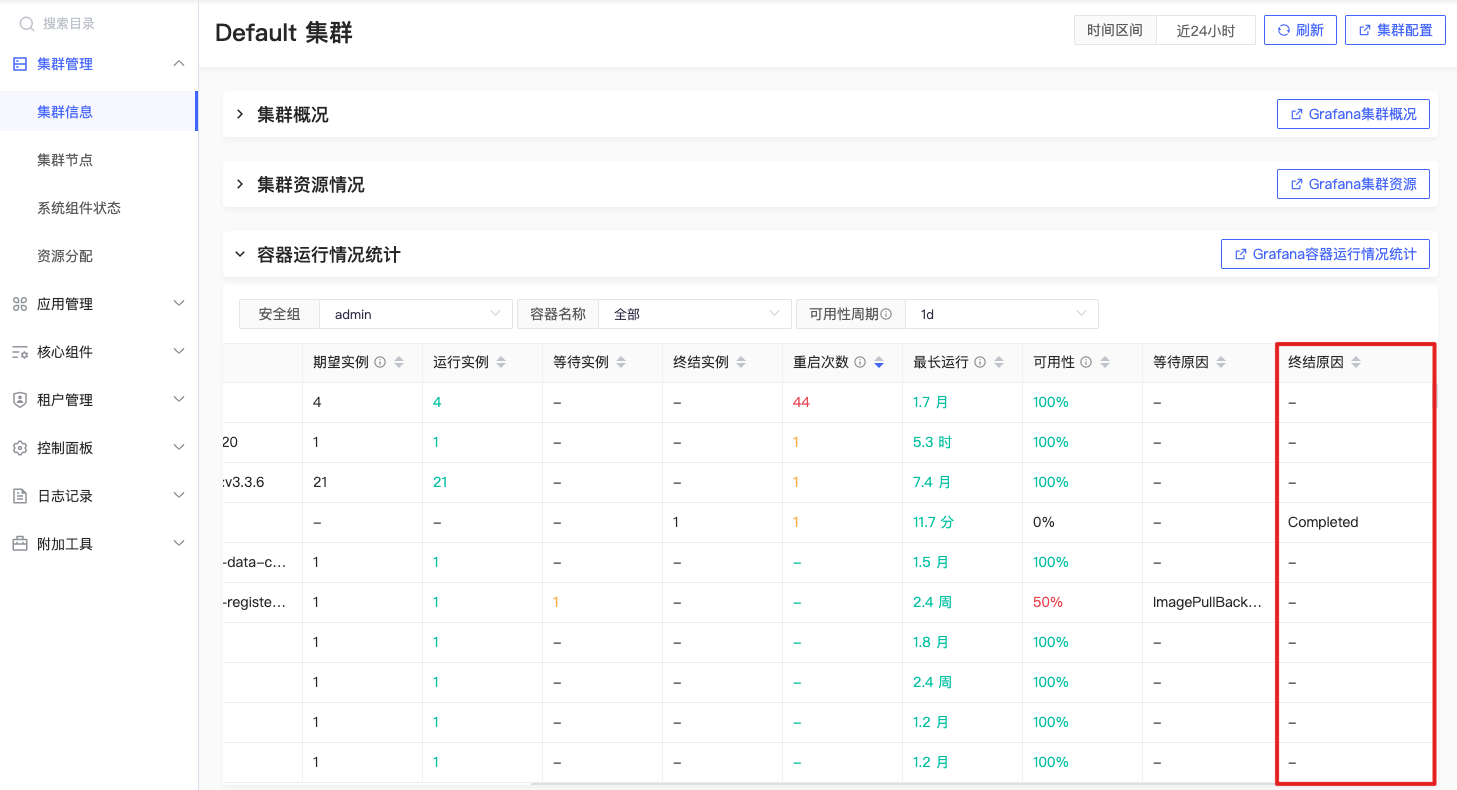
max by (container, namespace, terminated_reason) (label_replace(kube_pod_container_status_terminated_reason{origin_prometheus=~\"$origin_prometheus\",pod !~ \"$IgnoredPodRegex\",container =~\"$container\",container !=\"\",container!=\"POD\",namespace=~\"$namespace\"}, \"terminated_reason\", \"$1\", \"reason\", \"(.*)\")) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_status_terminated_reason | Kubernetes 中的指标名称,它用于记录Kubernetes中Pod中容器的终止原因 |
公式释义
取terminated_reason的最大值作为分组中容器的终止原因
CPU使用
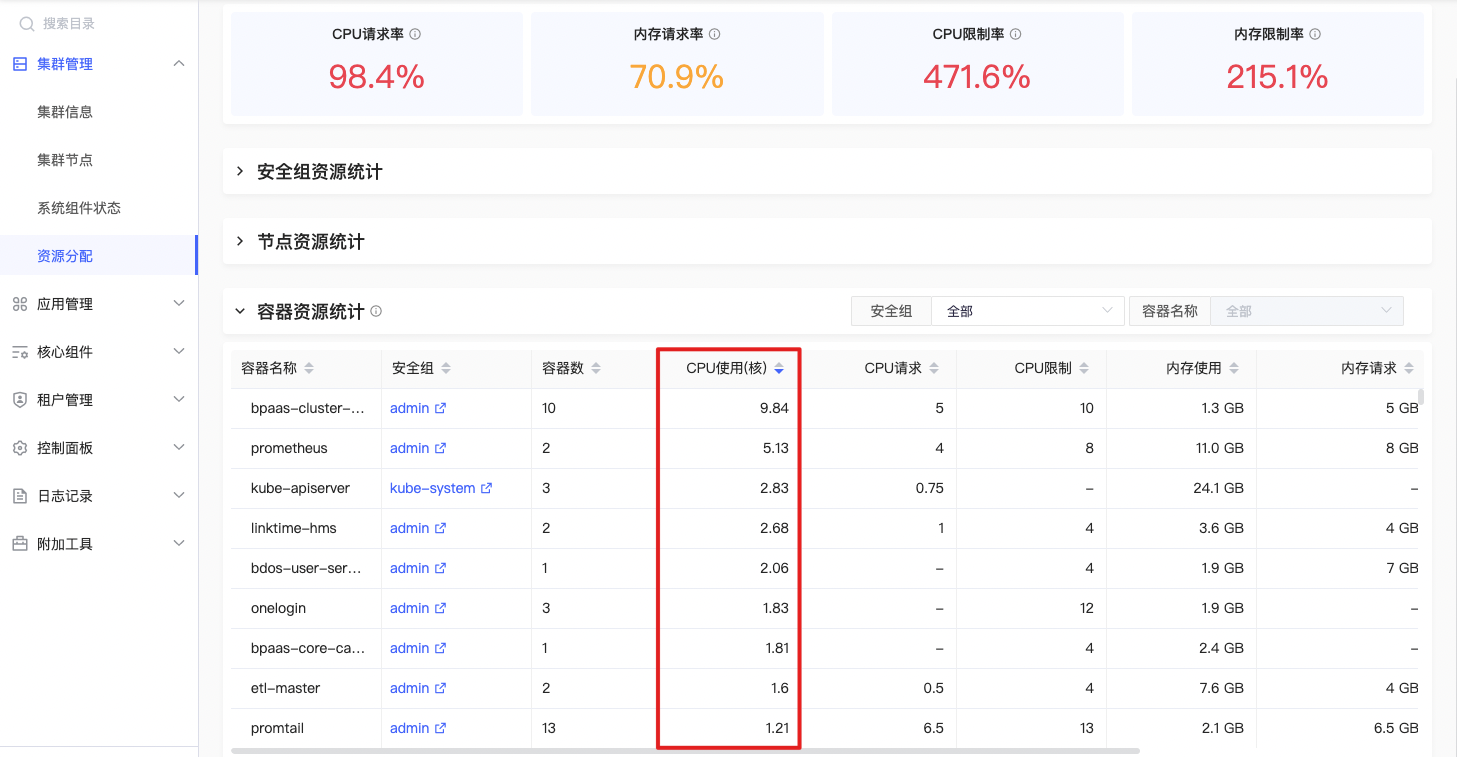
sum(irate(container_cpu_usage_seconds_total{origin_prometheus=~\"$origin_prometheus\",pod=~\"$pod\",container =~\"$container\",container !=\"\",container!=\"POD\",node=~\"^$node$\",namespace=~\"$namespace\"}[2m])) by (container, pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_cpu_usage_seconds_total | 表示容器在特定时间段内使用的CPU时间 |
公式释义
两分钟内 Pod下容器CPU使用均值
CPU请求
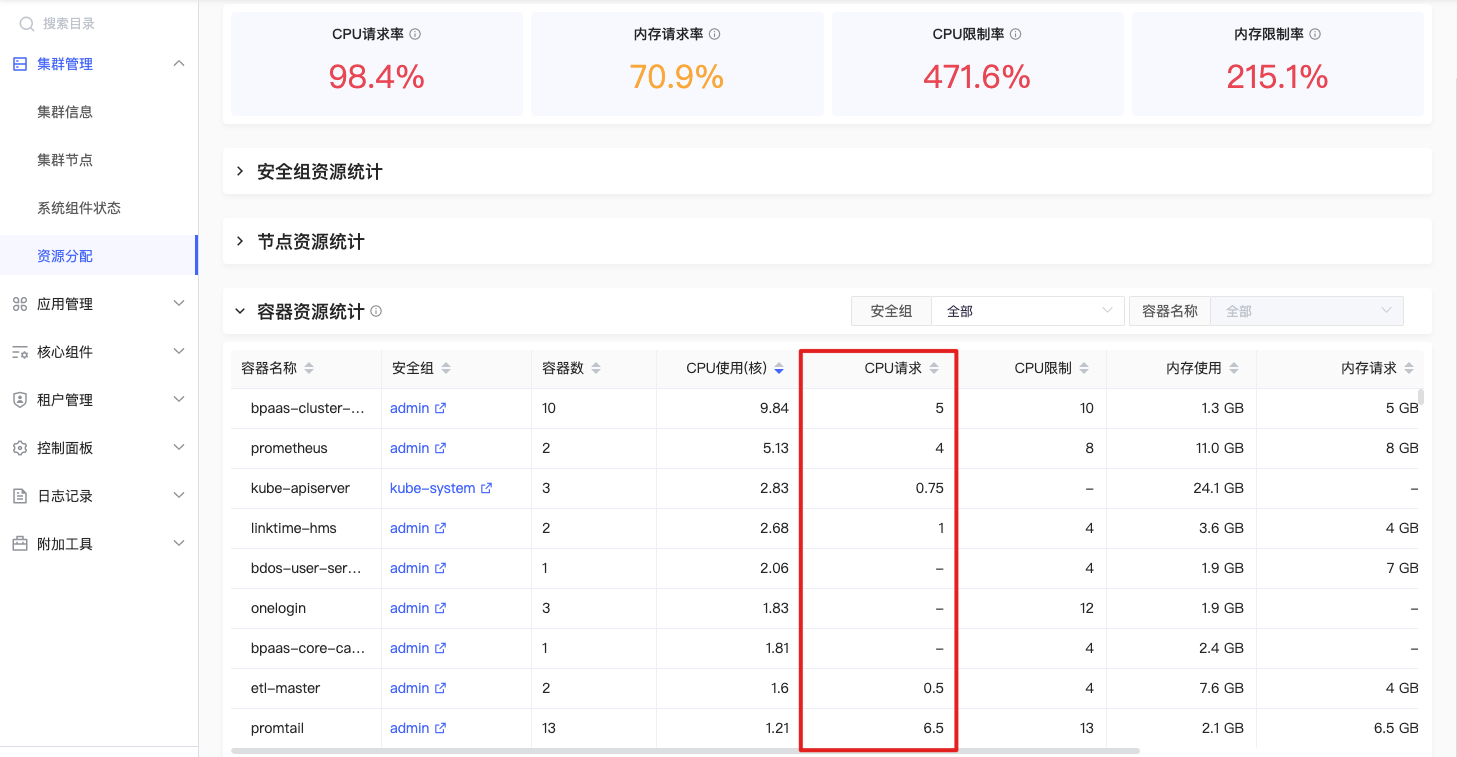
sum(kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",pod=~\"$pod\",container =~\"$container\",node=~\"^$node$\",namespace=~\"$namespace\"}) by (container,pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
指定容器CPU资源请求之和
CPU限制
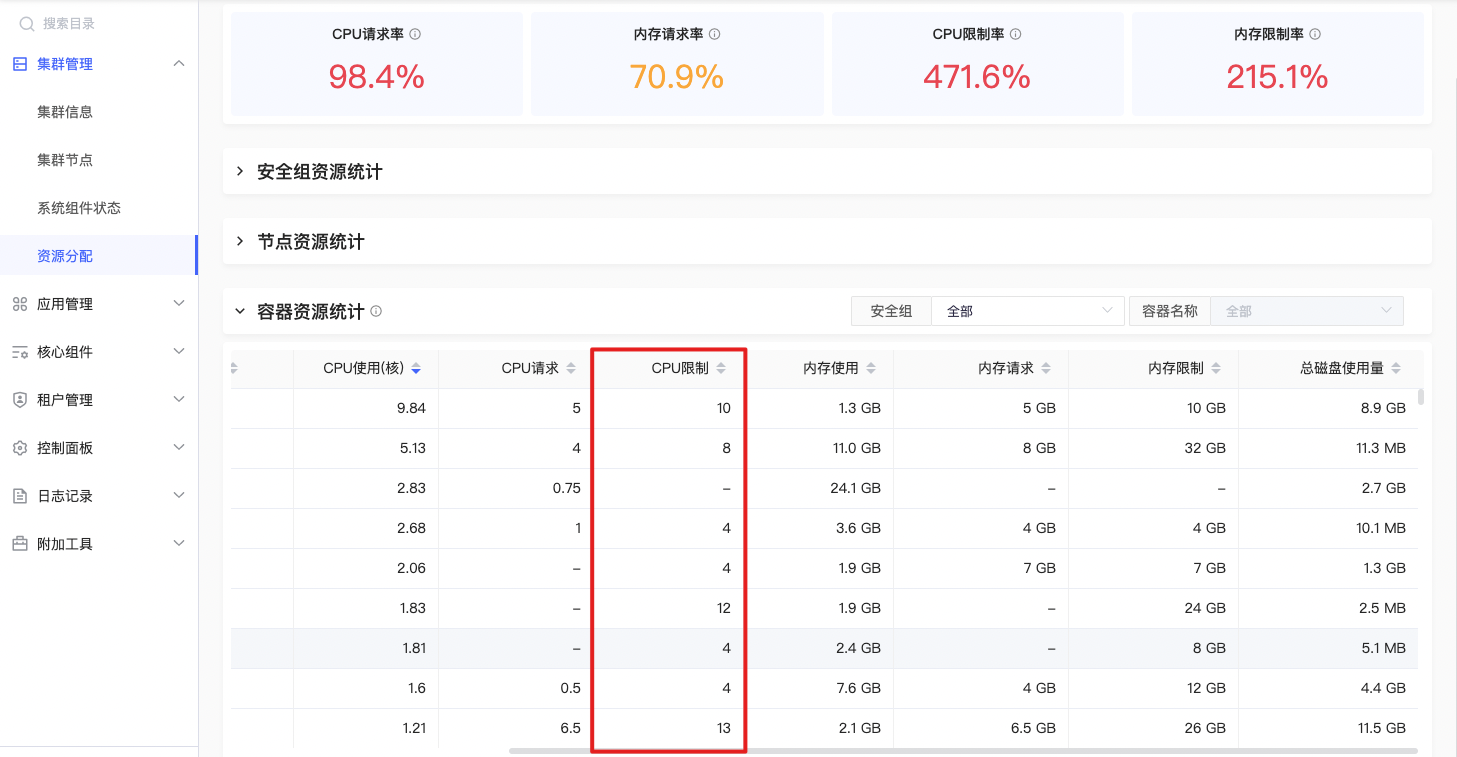
sum(kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"cpu\", unit=\"core\",pod=~\"$Pod\",container =~\"$Container\",node=~\"^$Node$\",namespace=~\"$NameSpace\"}) by (container,pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定容器CPU资源限制之和
内存使用
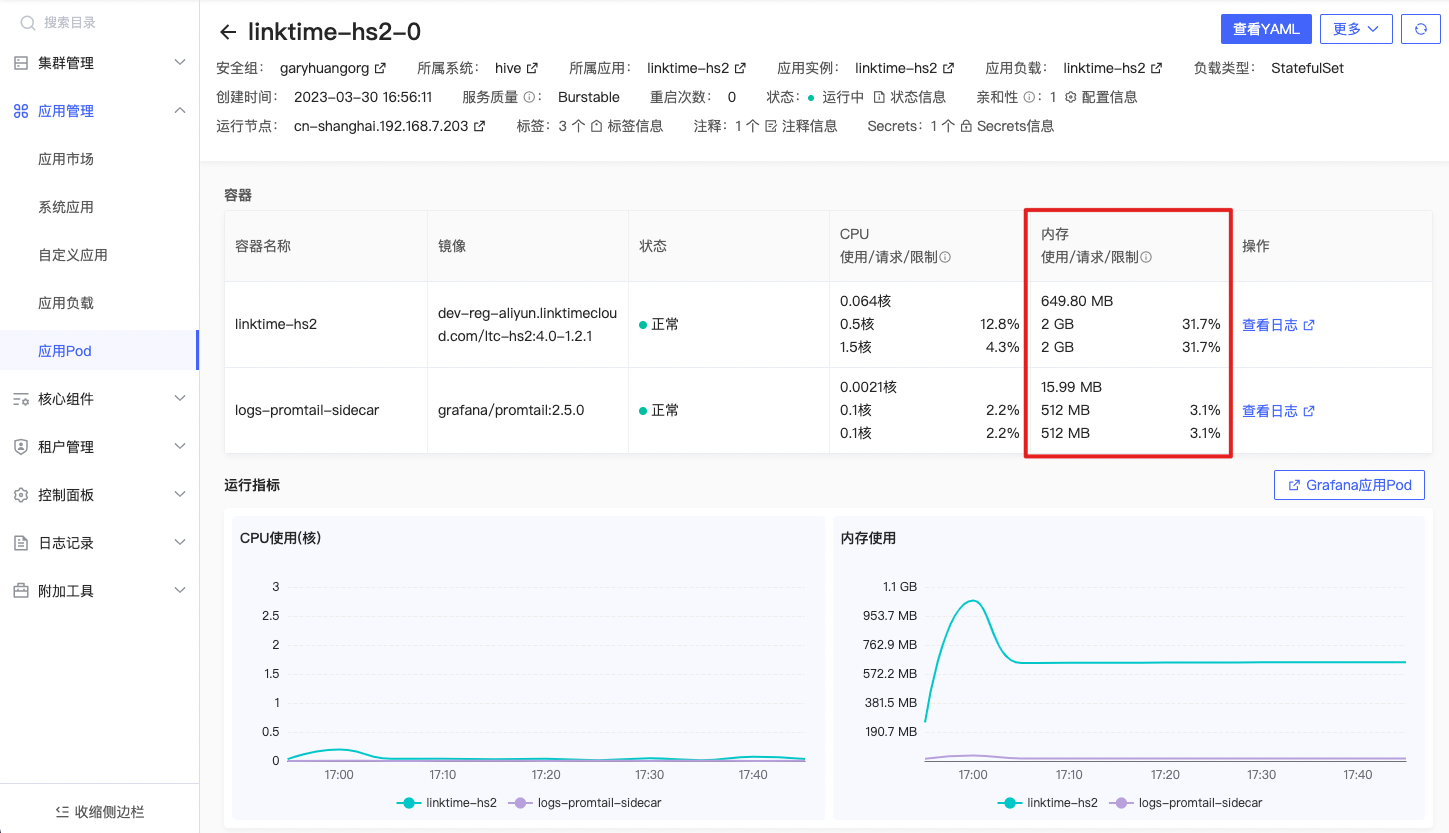
sum (container_memory_rss{origin_prometheus=~\"$origin_prometheus\",pod=~\"$pod\",container =~\"$container\",container !=\"\",container!=\"POD\",node=~\"^$node$\",namespace=~\"$namespace\"}) by (container, pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| container_memory_rss | Prometheus指标,用于记录容器进程的Resident Set Size(RSS),即进程占用的物理内存大小。单位为字节。 |
公式释义
在指定的 namespace、pod、container 和 node 上的物理内存中占用的总和
内存请求
sum(kube_pod_container_resource_requests{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",pod=~\"$pod\",container =~\"$container\",node=~\"^$node$\",namespace=~\"$namespace\"}) by (container,pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_requests | Kubernetes 中的指标名称,它用于监控 Pod 中容器资源的请求量。包含Pod中每个容器请求的CPU资源量、内存资源量、临时存储资源量 |
公式释义
内存限制
sum(kube_pod_container_resource_limits{origin_prometheus=~\"$origin_prometheus\",resource=\"memory\", unit=\"byte\",pod=~\"$pod\",container =~\"$container\",node=~\"^$node$\",namespace=~\"$namespace\"}) by (container,pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
磁盘使用
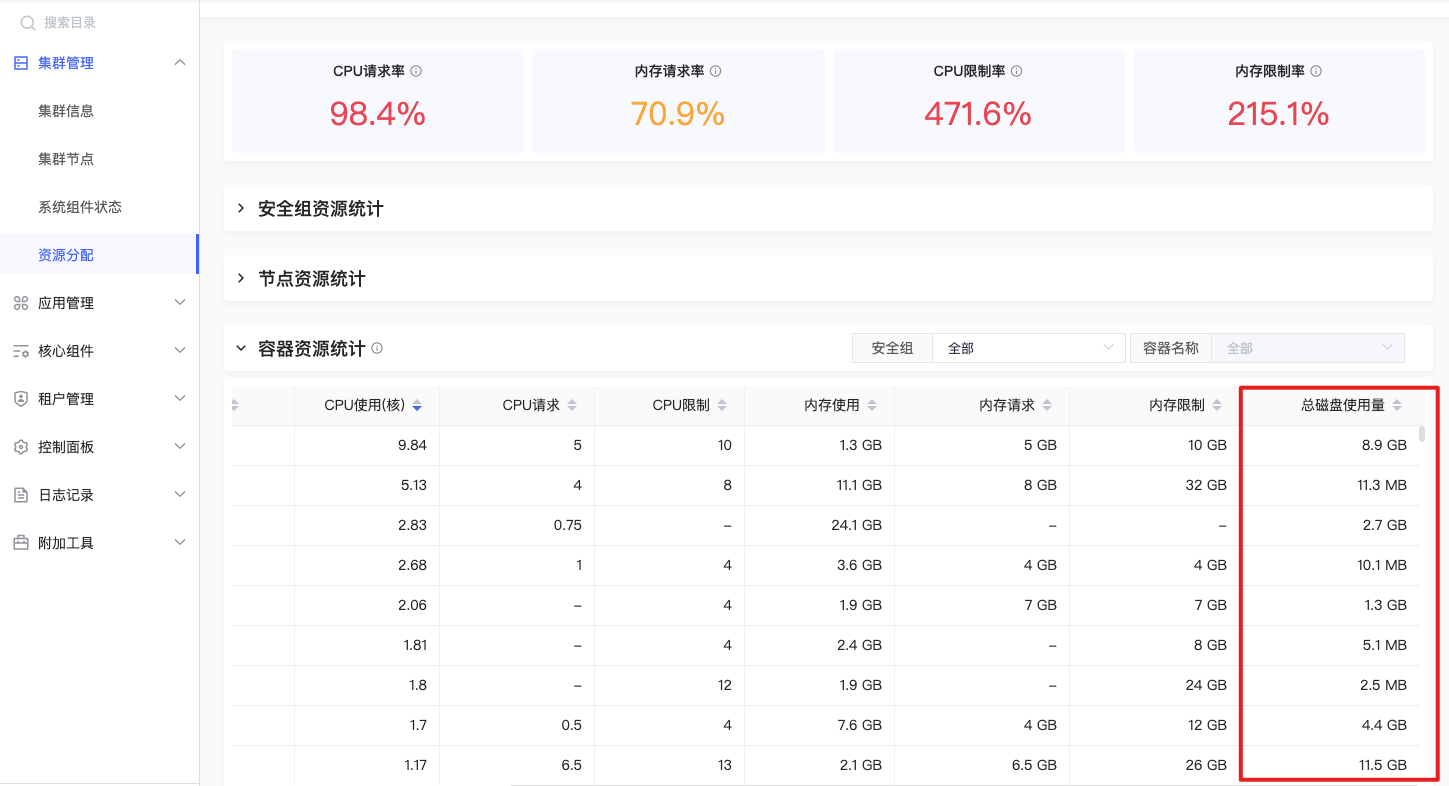
sum(container_fs_usage_bytes{origin_prometheus=~\"$origin_prometheus\",pod=~\"$pod\",container =~\"$container\",container !=\"\",container!=\"POD\",node=~\"^$node$\",namespace=~\"$namespace\"}) by (container,pod,node,namespace) |
数据来源
Prometheus
相关指标
| 指标名称 | 说明 |
|---|---|
| kube_pod_container_resource_limits | Kubernetes 中的指标名称,用于记录Kubernetes集群中每个Pod容器的资源限制。具体来说,它记录了每个容器的CPU和内存限制等信息。 |
公式释义
指定容器磁盘使用量
日志记录
标准输入输日志量
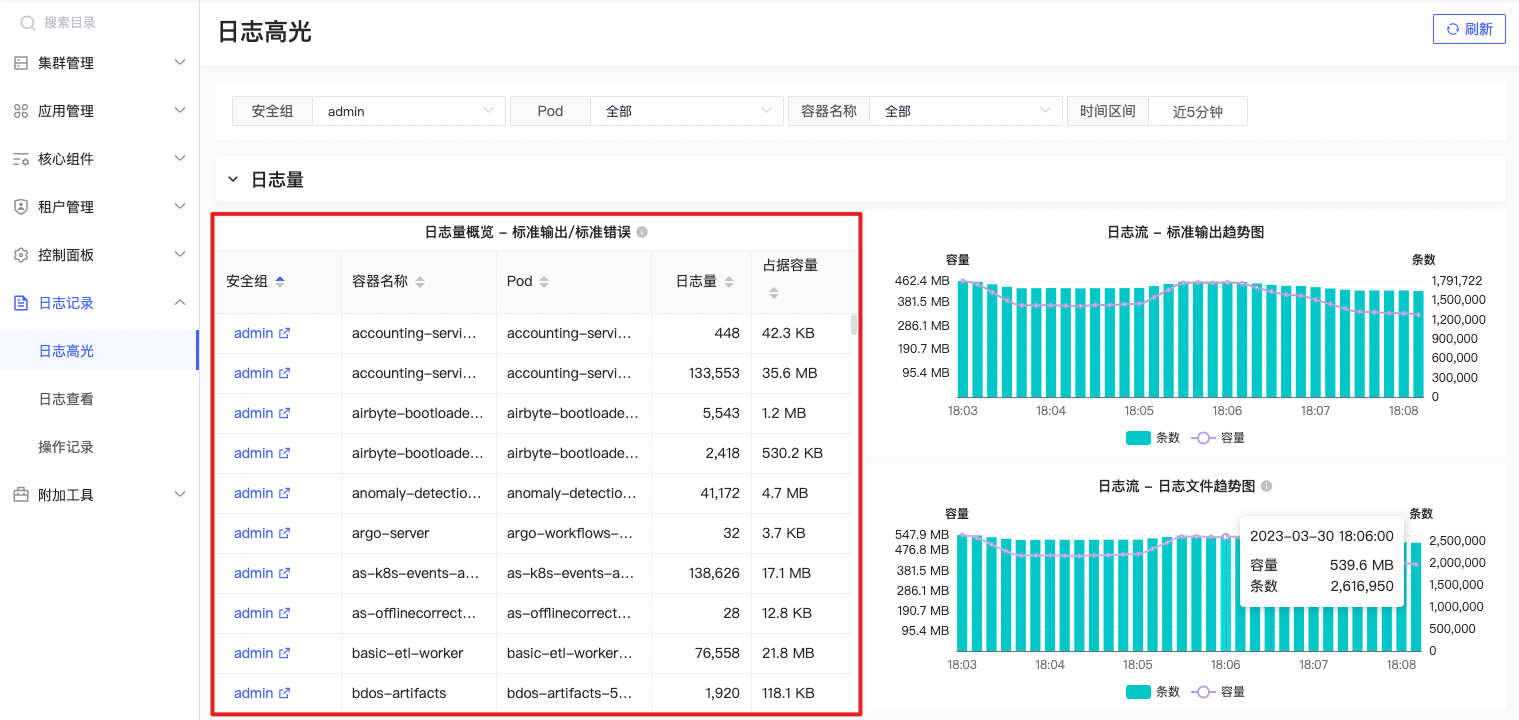
sum by(namespace, container, pod) (count_over_time({namespace=~\"$namespace\", container=~\"$container\", pod=~\"$pod\"} [$__range])) |
数据来源
Loki
公式释义
根据指定的命名空间(namespace)、容器名称(container)和 Pod 名称(pod),统计在指定时间范围($__range)内的标准输入输出日志数量
标准输入输日志容量

sum by(namespace, container, pod) (bytes_over_time({namespace=~\"$namespace\", container=~\"$container\", pod=~\"$pod\"} [$__range])) |
数据来源
Loki
公式释义
指定时间范围内标准输入输出日志大小。
- bytes_over_time是一个Prometheus内置的函数,用于计算时间范围内的指标值总和。
标准输入输出趋势
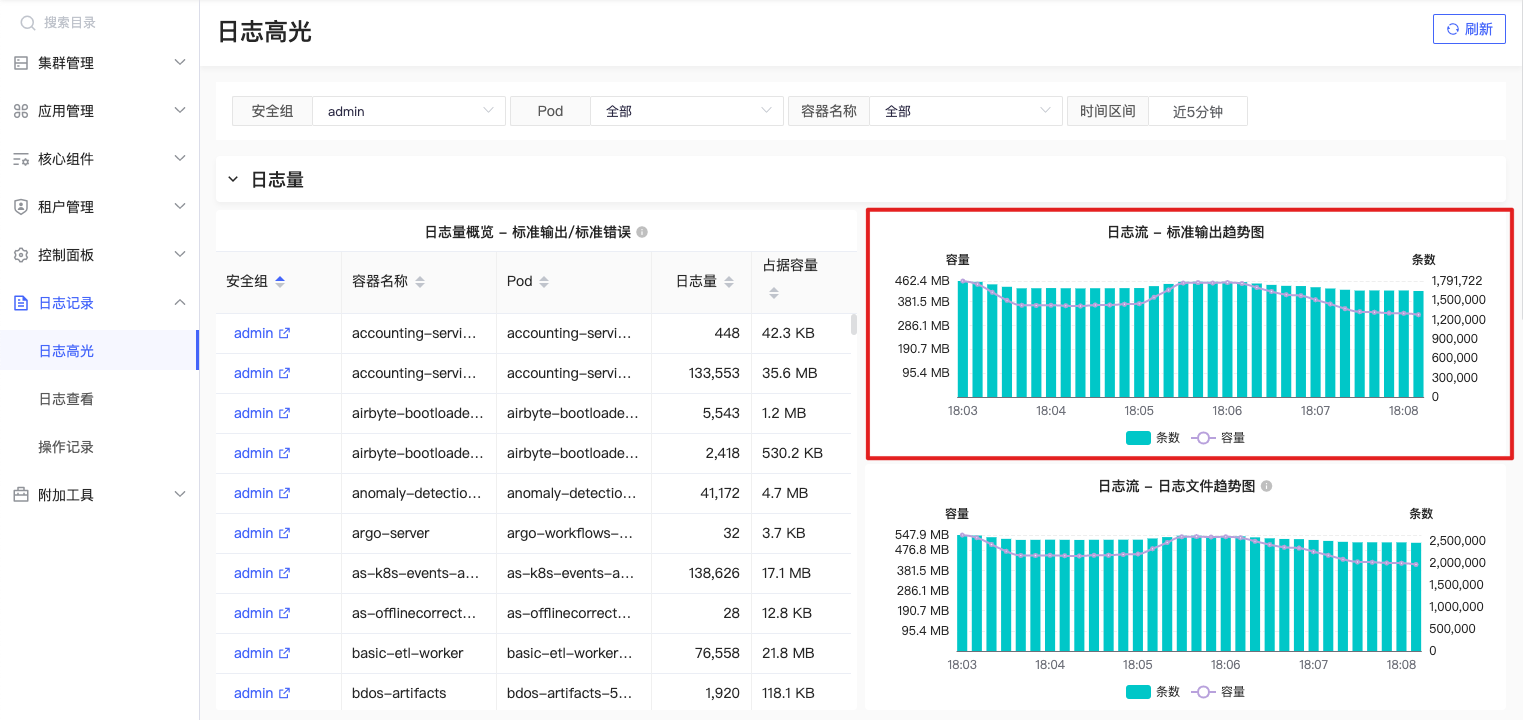
- 日志数量趋势
sum by(namespace, container, pod) (count_over_time({namespace=~\"$namespace\", container=~\"$container\", pod=~\"$pod\"} [$__range])) |
- 日志容量趋势
sum by(namespace, container, pod) (bytes_over_time({namespace=~\"$namespace\", container=~\"$container\", pod=~\"$pod\"} [$__range])) |
数据来源
Loki
公式释义
按照命名空间、应用Pod、容器维度,计算标准输入/错误 在给定时间范围内的每个Pod中的日志数量及容量
日志文件趋势
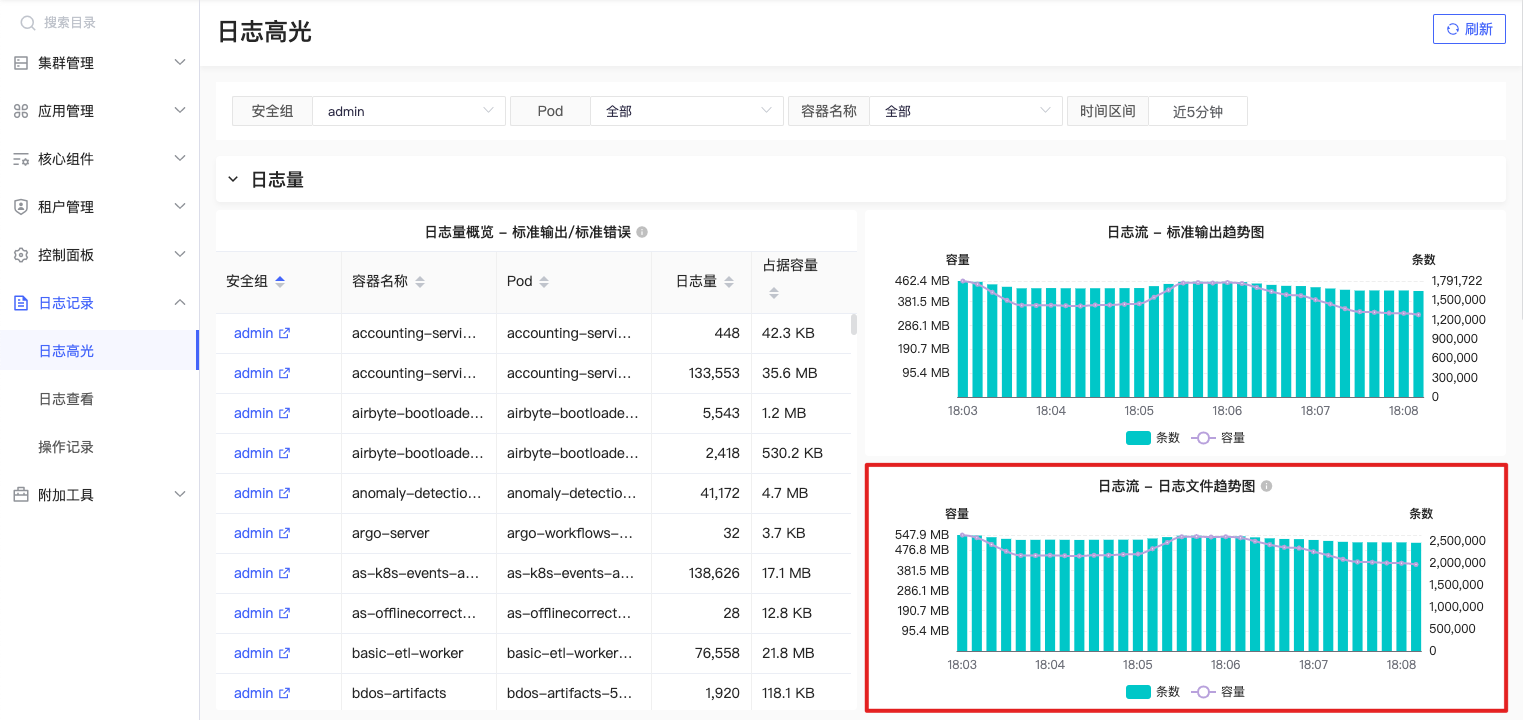
- 日志数量趋势
sum by(namespace, container) (count_over_time({filename =~ `/var/log/$namespace-$container/.+|/var/log/pods/$namespace_$container/.+`} [$__range])) |
- 日志容量趋势
sum by(namespace, container) (bytes_over_time({filename =~ `/var/log/$namespace-$container/.+|/var/log/pods/$namespace_$container/.+`} [$__range])) |
数据来源
Loki
公式释义
按照命名空间、应用Pod、容器维度,计算日志文件在给定时间范围内的每个Pod中的日志数量及容量
错误次数变化趋势
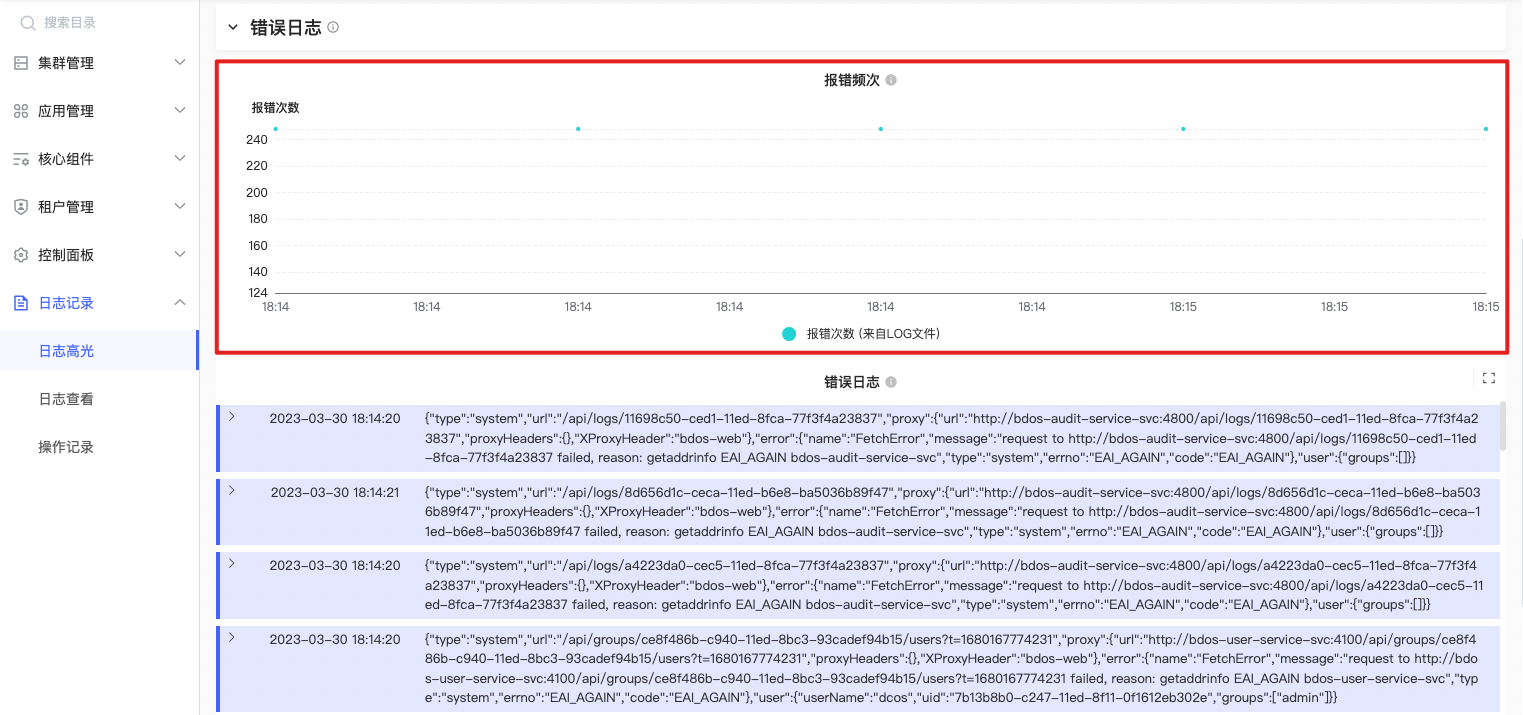
sum by(namespace, container) (count_over_time(\n{filename=~`/var/log/$namespace-$container/error/.+`}\n| pattern \"<_> log - <logContent>\" | line_format \"{{.logContent}}\" [$__interval]\n)) |
数据来源
Loki
公式释义
统计在/var/log/目录下,文件名符合/var/log/$namespace-$container/error/.+正则表达式的日志文件中,包含 “<_>” 的日志行数,并按照namespace和container进行汇总
错误日志内容
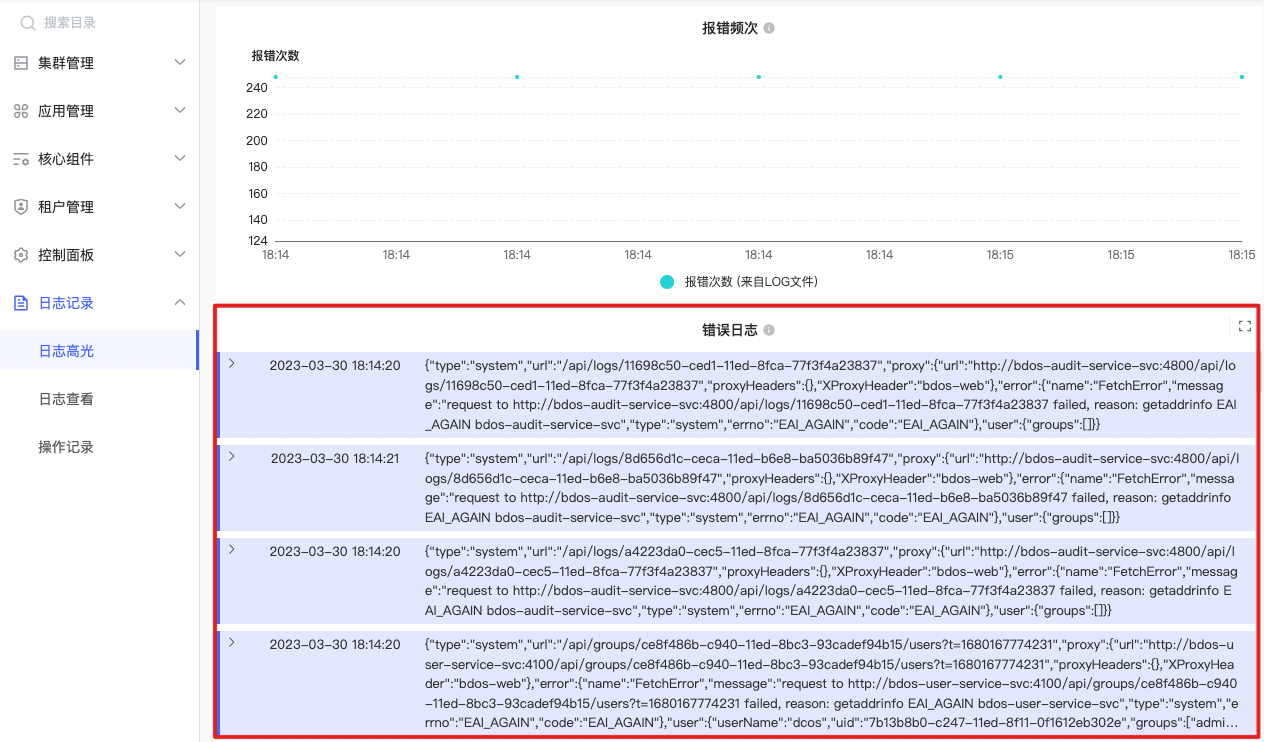
{filename=~`/var/log/$namespace-$container/error/.*`}\n| pattern \"<_> error - <logContent>\"\n| line_format \"{{.logContent}}\"\n| json |
数据来源
Loki
公式释义
指定的命名空间和容器下查找所有的错误日志,并输出日志中包含的 error 字段内容
日志查看

{namespace=~\"$namespace\", container=~\"$container\", pod=~\"$pod\", stream=~\"$stream\"}\n|~ `$keyword`\n |
数据来源
Loki
公式释义
在容器日志中搜索指定的关键字,并返回匹配该关键字的日志行。其中,namespace、container、pod 和 stream 是用于筛选 Kubernetes 中容器日志的标签。