
监控看板
平台组件监控
KDP使用Grafana进行平台组件监控。
Grafana 是一个开源的数据可视化和监控平台,支持多种数据源,包括 Prometheus、Elasticsearch、InfluxDB、Graphite 等等。Grafana 提供了丰富的面板和插件,可以帮助用户实时监控和可视化数据,同时也提供了强大的查询和警报功能。
详细介绍可查看Grafana官方文档:https://grafana.com/docs/grafana/latest/fundamentals/
平台提供的 Grafana 组件监控面板可以应用于以下场景:
- 监控:可以帮助用户实时监控大数据平台的各种指标和数据,包括 CPU、内存、磁盘、网络等等;
- 日志:可以帮助用户可视化大数据平台的日志数据,方便用户进行快速的故障排除和问题定位。
- 数据分析:可以基于已有的看板,帮助用户对大数据平台中的数据进行进一步可视化分析,包括数据挖掘、数据建模等等。
- 性能优化:可以帮助用户对大数据平台的性能进行监控和优化,包括性能测试、性能分析等等。
打开Grafana运维监控平台,使用KDP统一用户单点登录后,可查看KDP系统定制化提供的监控Dashboard。
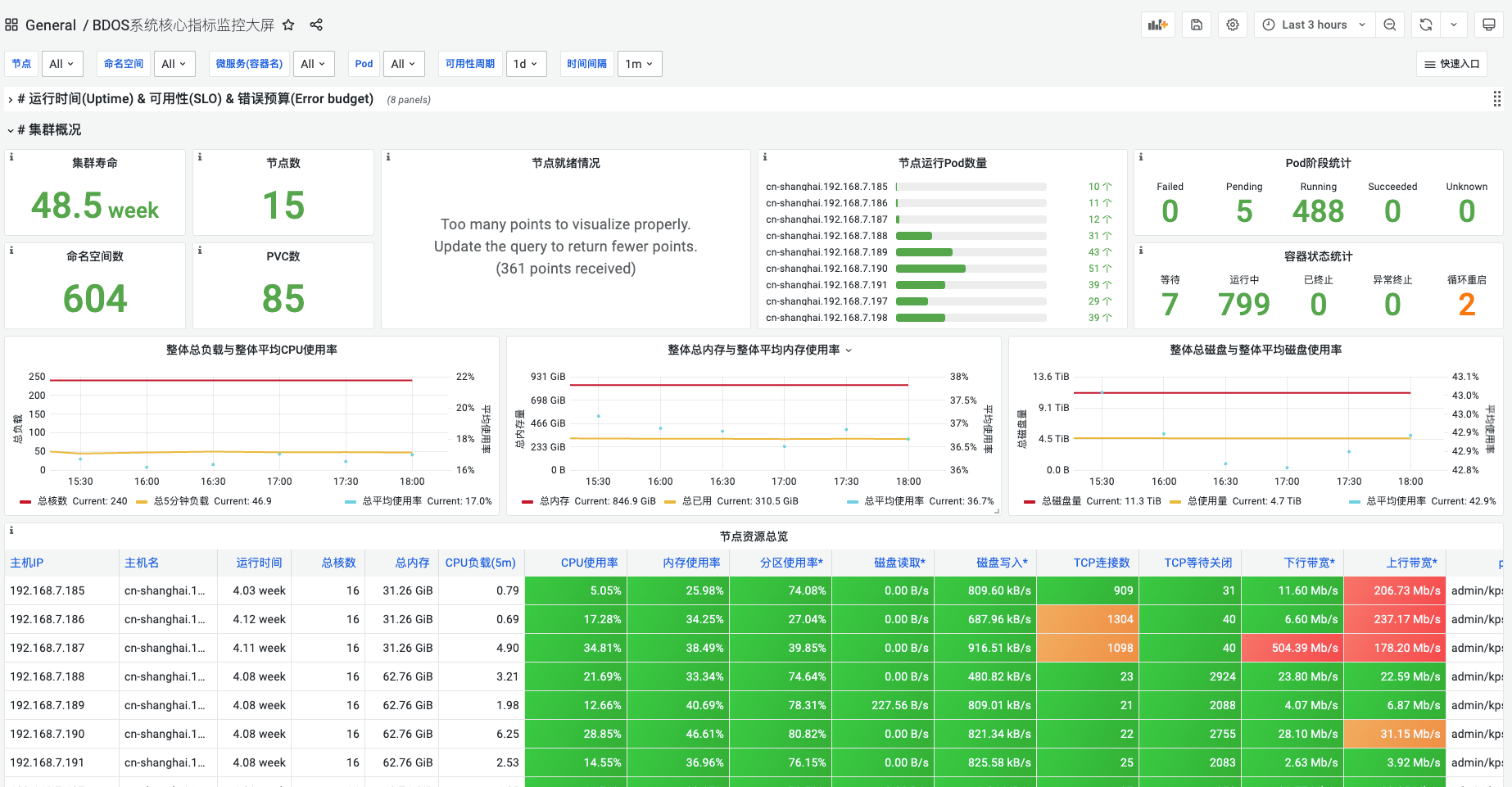
1.BDOS系统核心指标监控大屏
- 运行时间&可用性&错误预算:显示可用性错误预算,一天内集群控制平面可用性、集群控制平面错误预算、Prometheus监控可用性,30天API Server可用性,API Server证书有效期,微服务可用性统计
- 集群概况:显示集群寿命、节点数、命名空间数、PVC数、节点运行Pod数量、整体总负载与整体平均CPU使用率、整体总内存与整体平均内存使用率、节点资源总览等信息
- 资源明细-节点维度:显示节点CPU核数、节点内存信息、节点CPU比列、节点内存比例、节点存储信息、命名空间、网络总览、节点信息明细等信息
- 资源明细-微服务维度:显示微服务资源统计、微服务整体CPU使用率、微服务整体内存使用率、微服务网络带宽
- 资源明细-Pod/节点维度:显示Pod/节点资源明细,包括节点名称、命名空间、容器名、Pod名称、CPU使用率、使用核数、CPU需求、CPU限制、WSS、RSS、内存需求、内存限制及磁盘使用大小
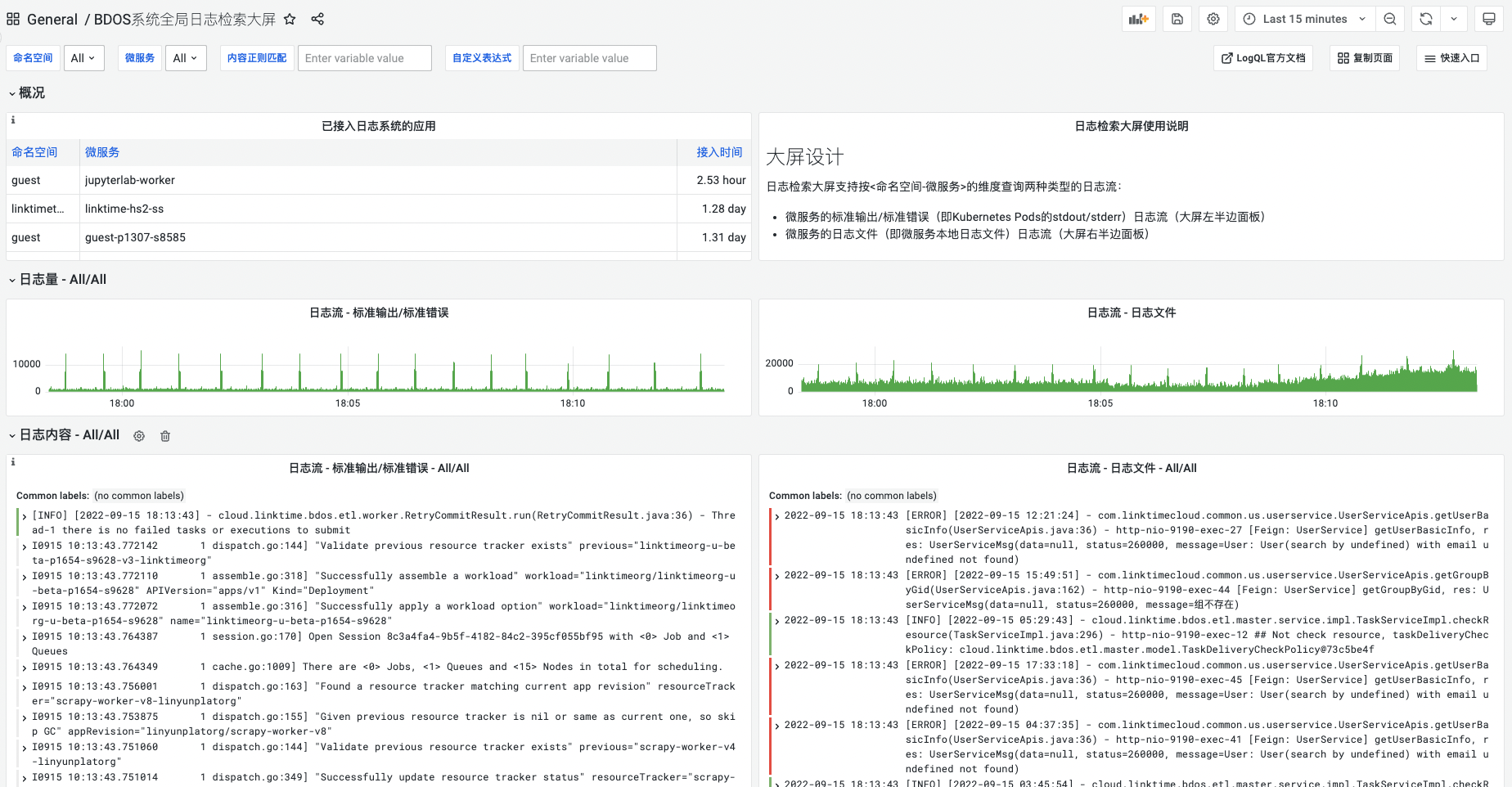
2.BDOS系统全局日志检索大屏
- 概况:显示已接入日志系统的应用列表,展示命名空间、微服务名、接入时间。显示日志检索大屏使用说明
- 筛选
- 支持按命名空间(k8s命名空间)、微服务(应用微服务容器名)两个维度全选及多选筛选日志;支持通过内容正则匹配寻找匹配的日志内容;支持通过LogQL语法为日志查询附加用户自定义表达式;支持修改查询时间区间,默认最近15分钟
- 显示筛选条件下的微服务的标准输出/标准错误日志在筛选时间段内每秒日志量;显示筛选条件下的微服务的本地日志文件在筛选时间段内每秒日志量
- 日志内容:显示筛选条件下的微服务的标准输出/标准错误日志内容;显示筛选条件下的微服务的本地日志文件内容
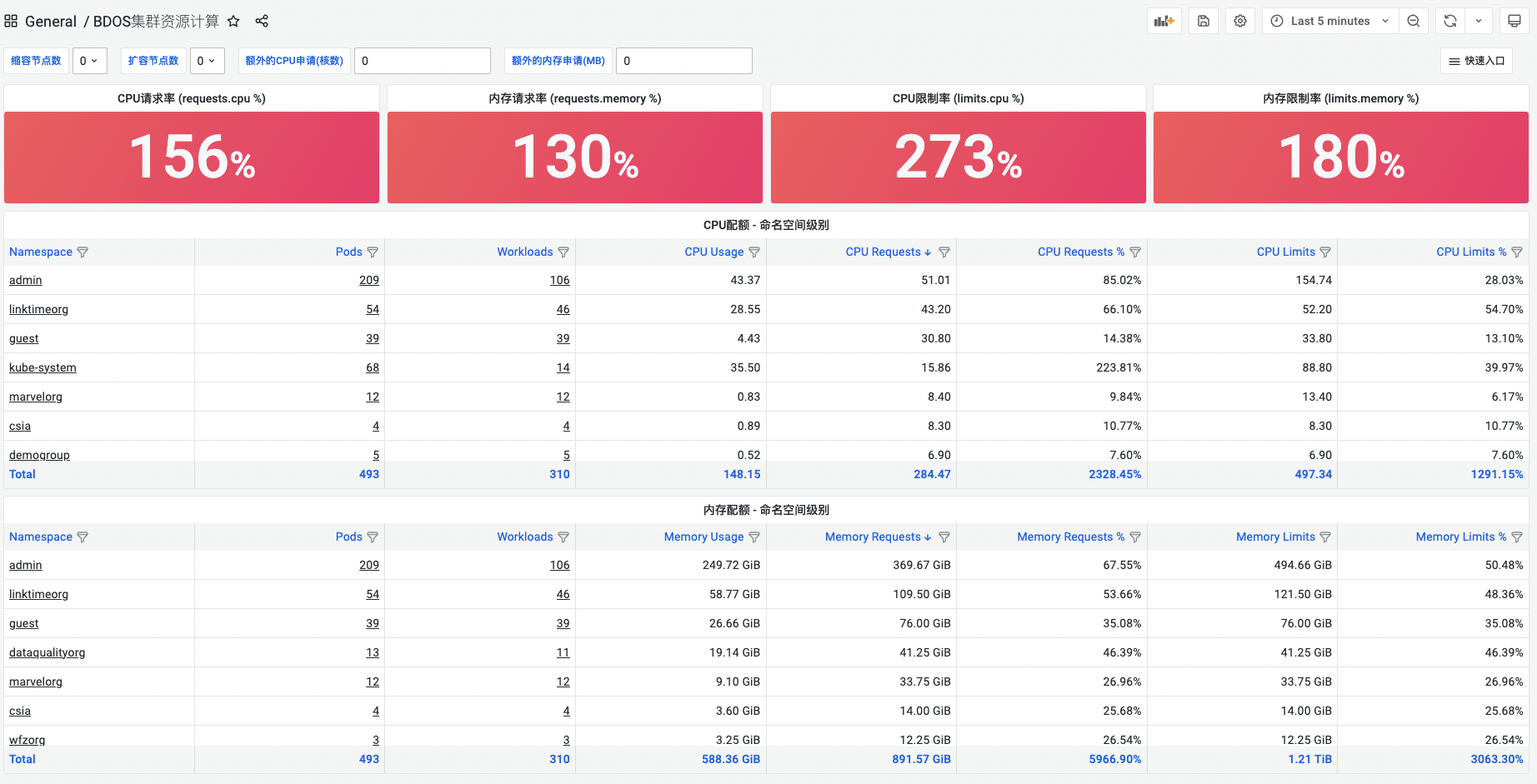
3.BDOS集群资源计算
显示不同缩容节点数、扩容节点数下CPU请求率、内存请求率、CPU限制率、内存限制率;显示不同命名空间下CPU配额;显示不同命名空间内存配额。
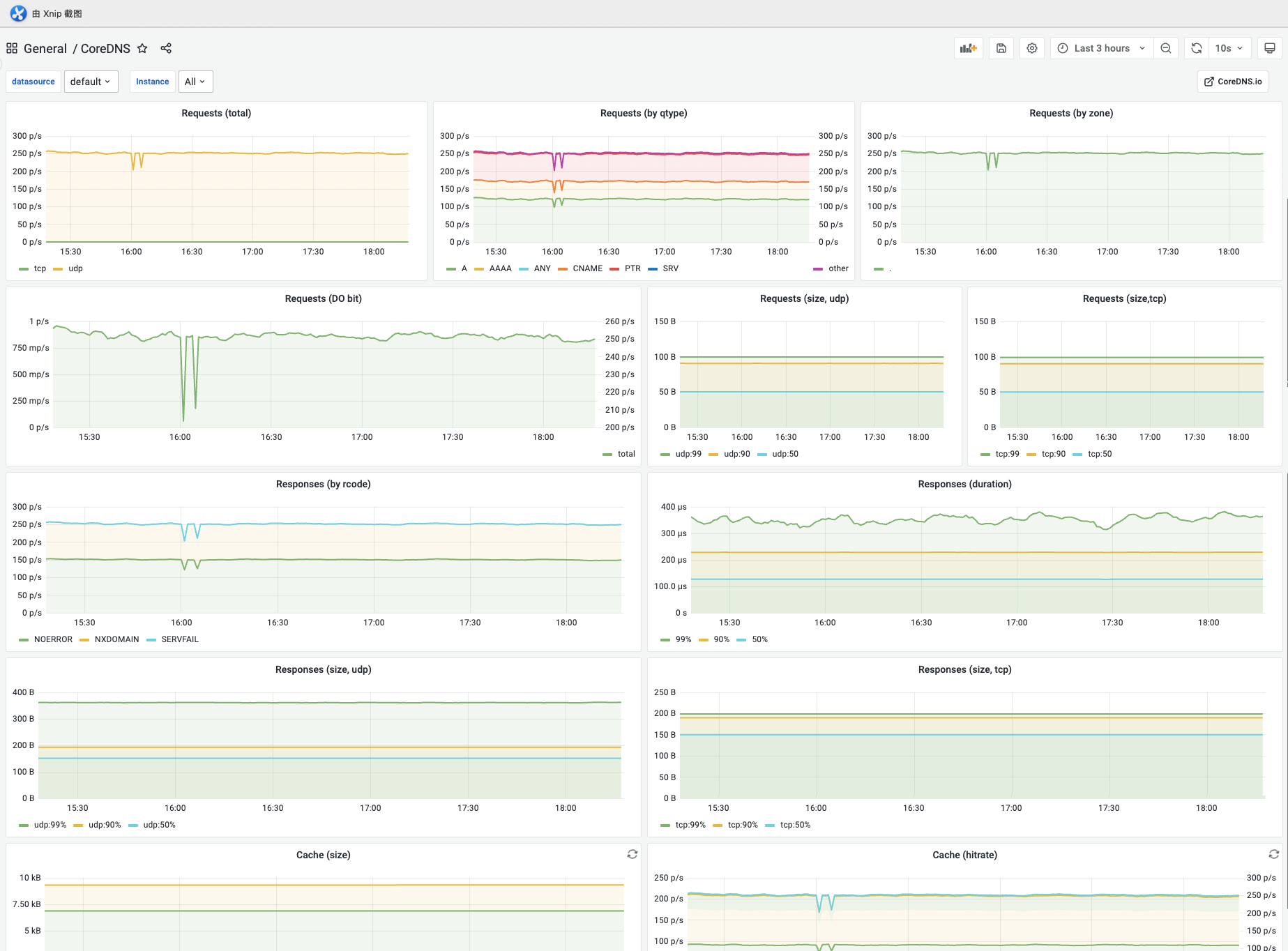
4.CoreDNS
显示Prometheus实例下每秒请求次数、请求大小、每秒响应次数、响应持续时间、响应大小、缓存大小、缓存命中率等。支持选择不同实例,支持选择统计时间范围
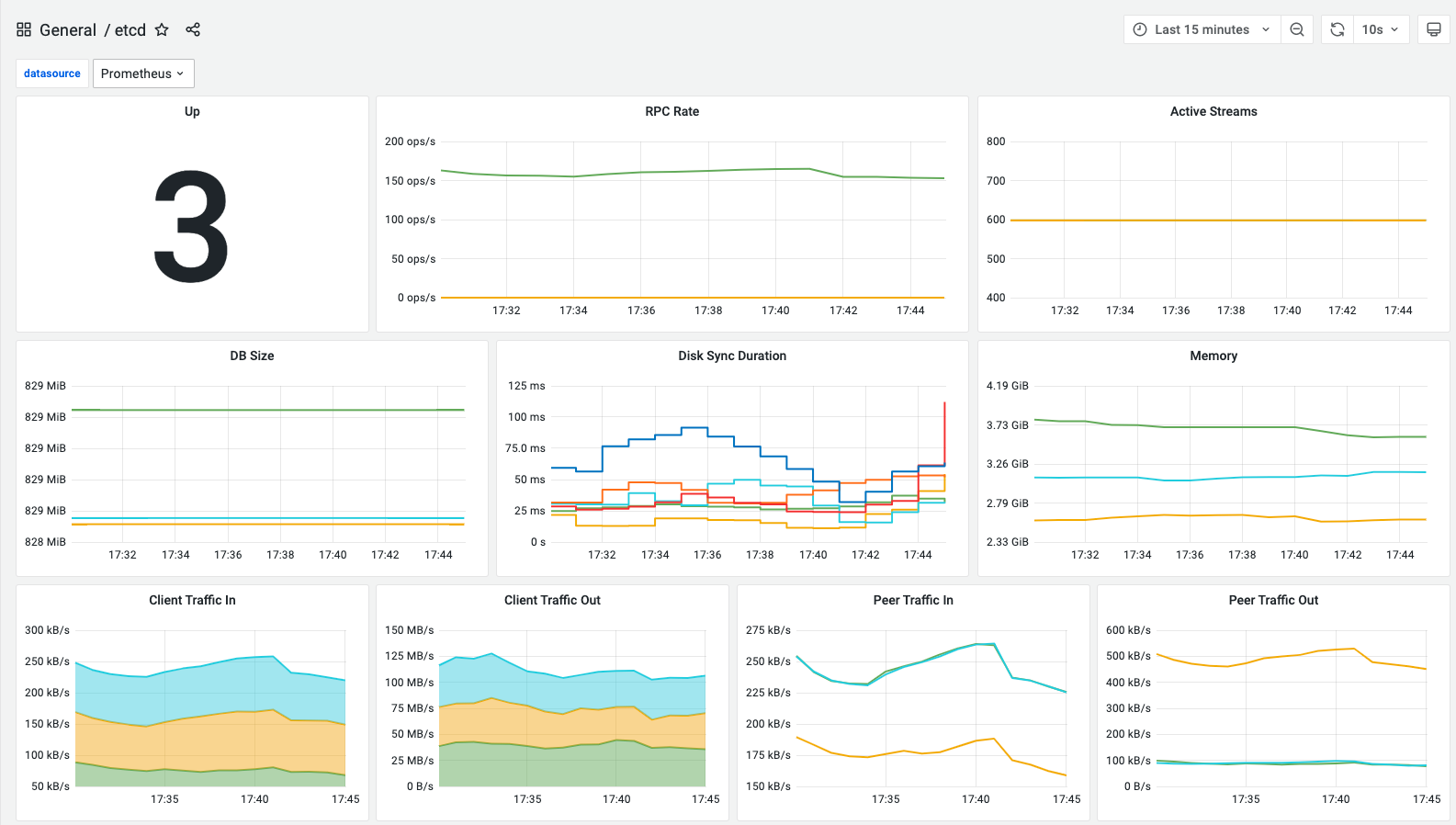
5.etcd
显示集群拥有领导者数量、RPC调用平均数、RPC持续活跃数、MVCC数据大小、磁盘延迟分布直方图、内存占用大小、发送/接收到 grpc 客户端的字节数、发送/接收具有 ID 的对等方的字节数、失败提案总数、领导者变更次数
大数据组件监控
打开Grafana运维监控平台,可查看大数据组件监控Dashboard。
Grafana简介及基本概念详情请查看《Grafana运维管理使用手册》
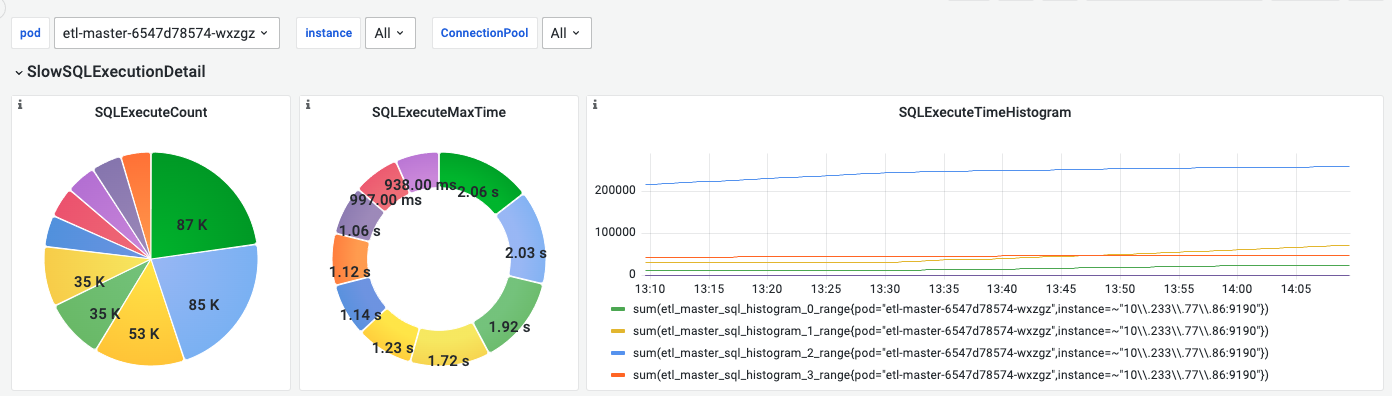
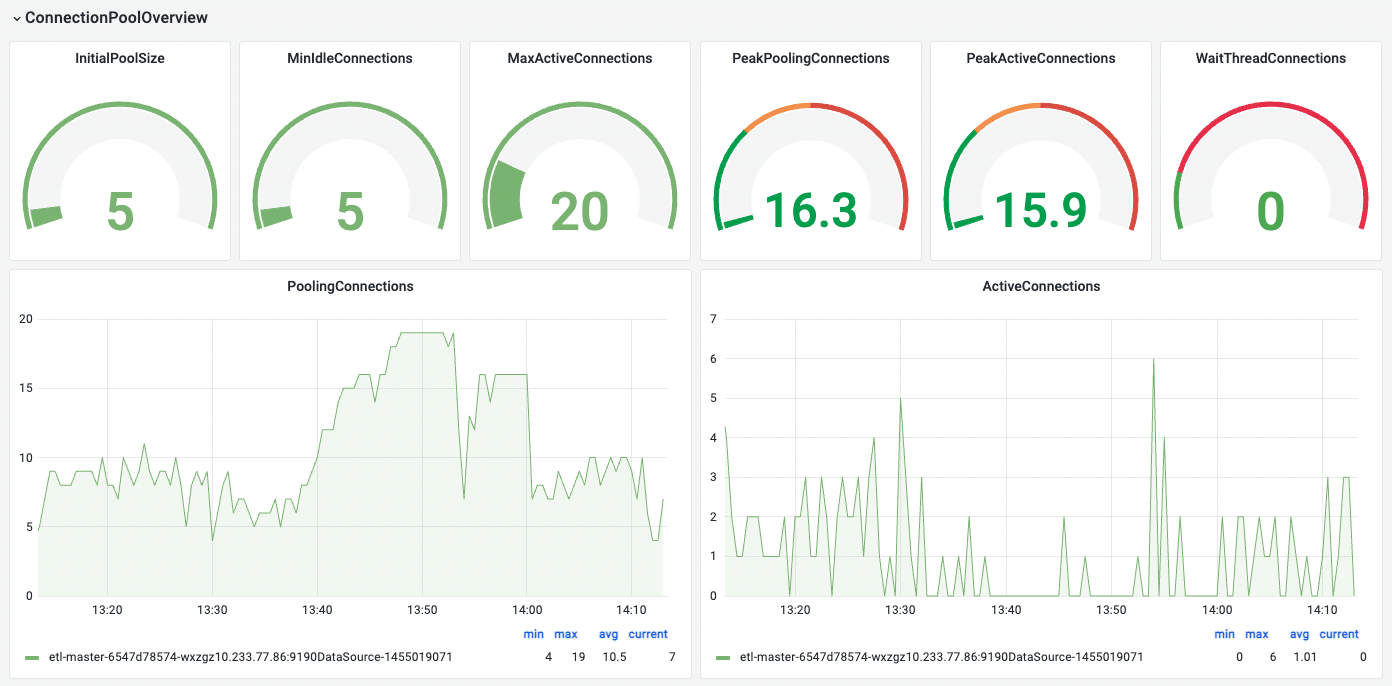
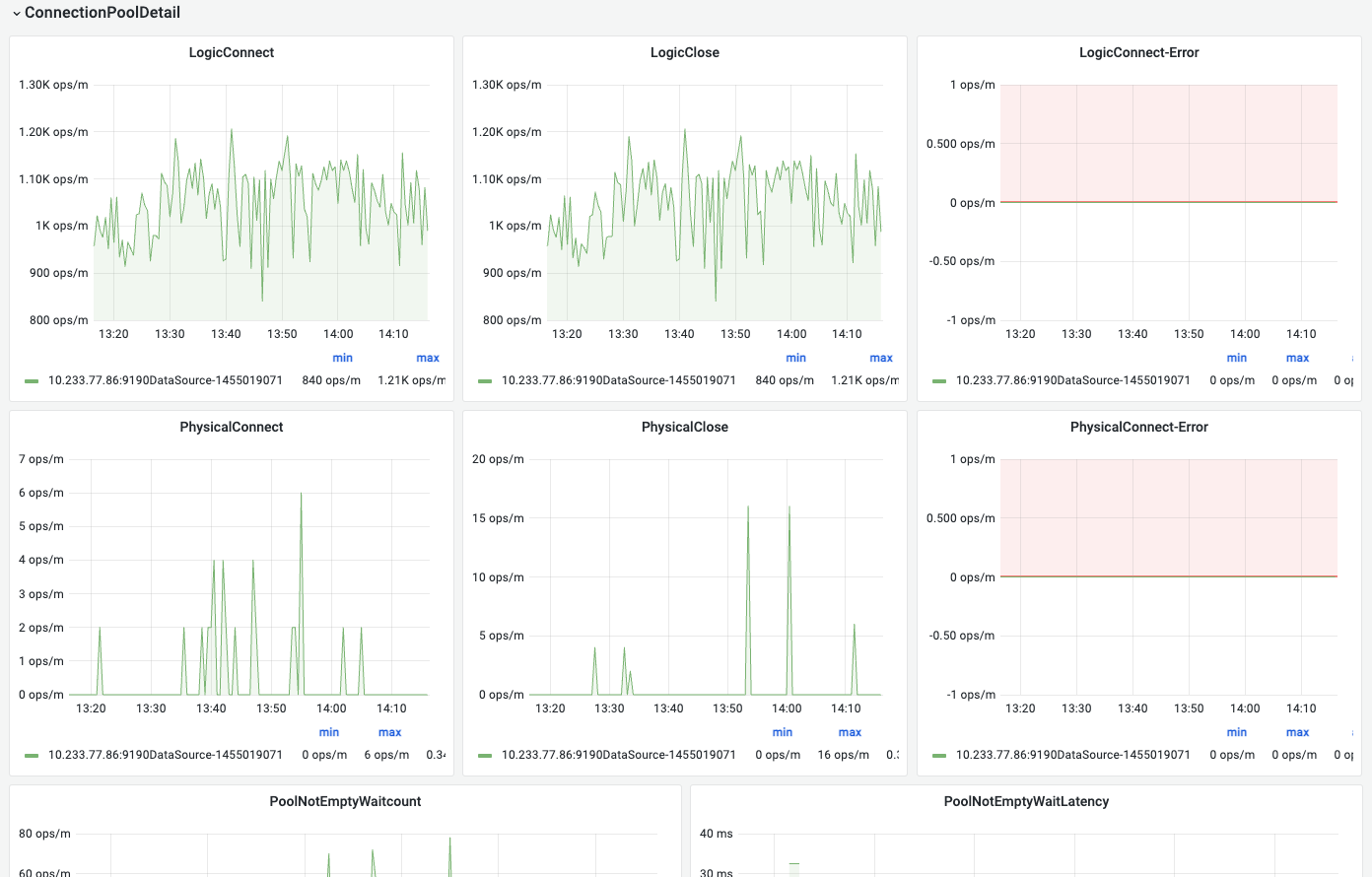
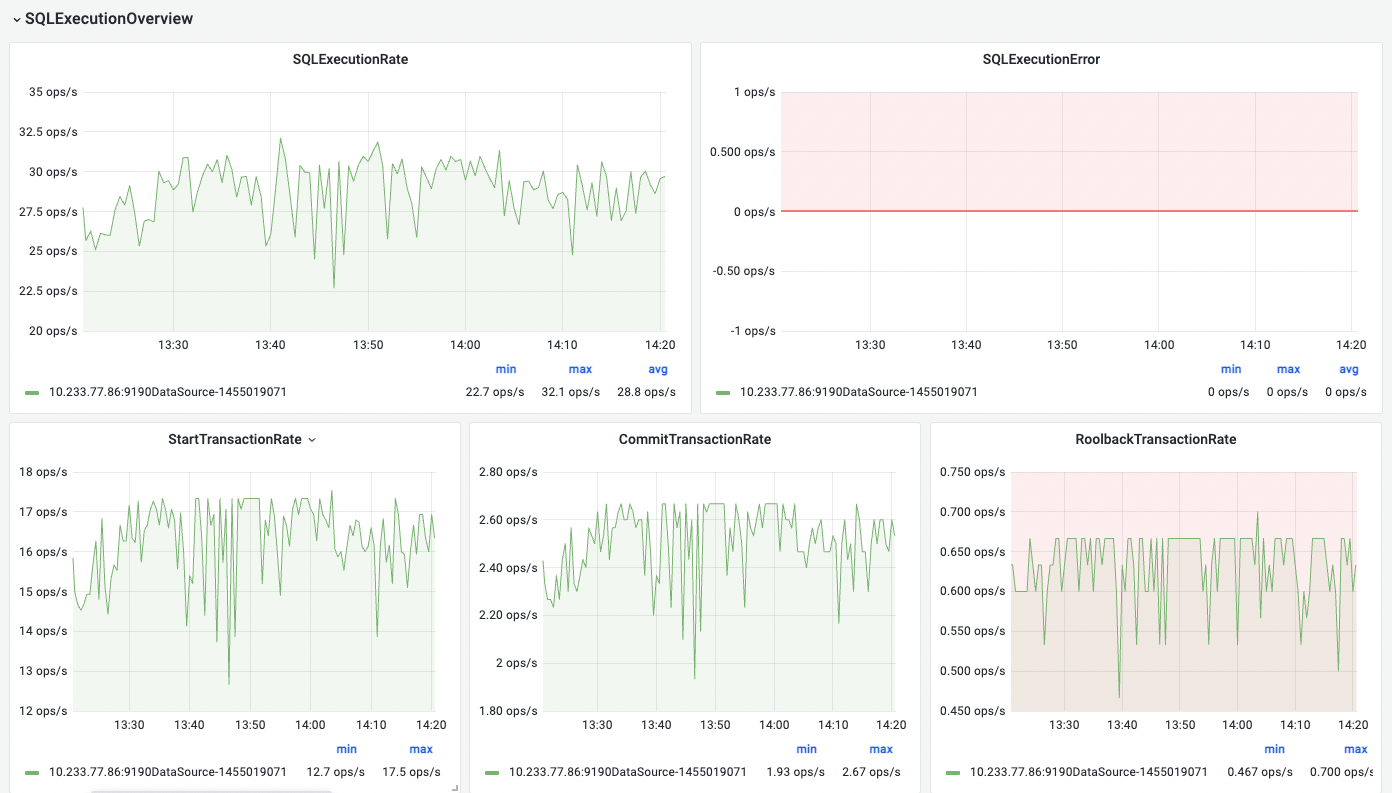
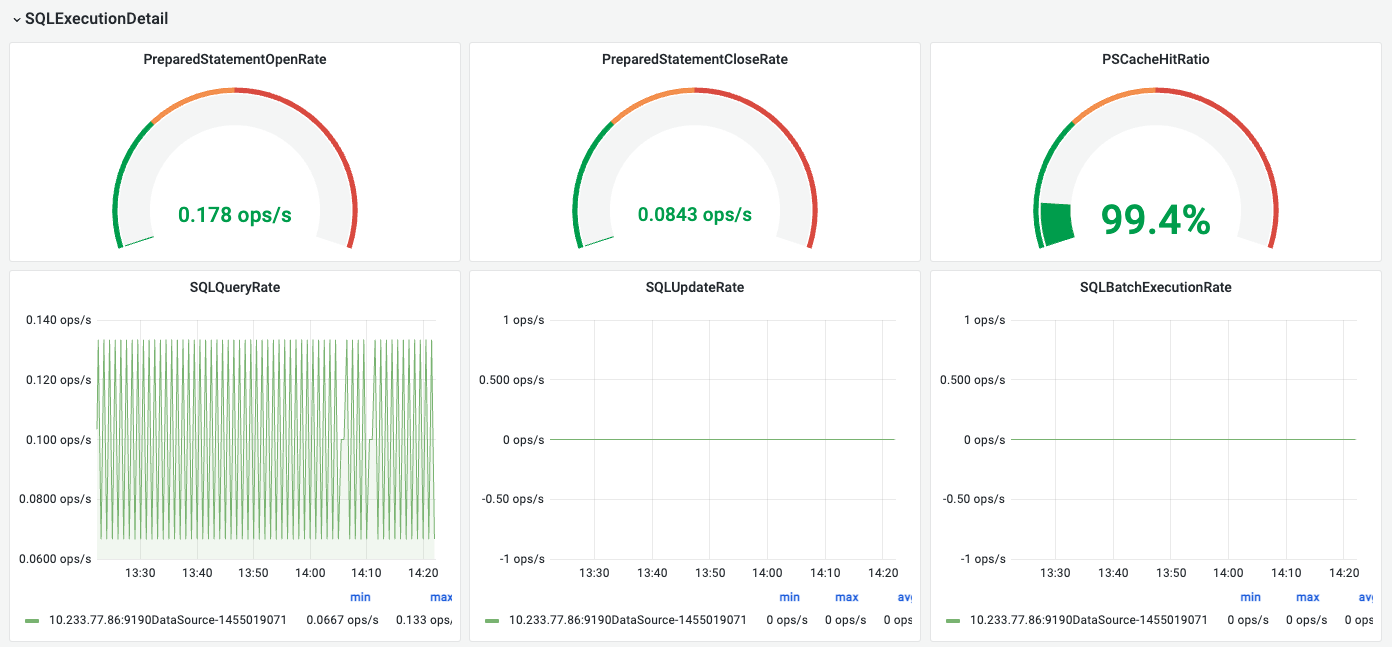
1.FlowMan监控-master看板
显示连接池概览、连接池详情、SQL执行概述、SQL执行详情
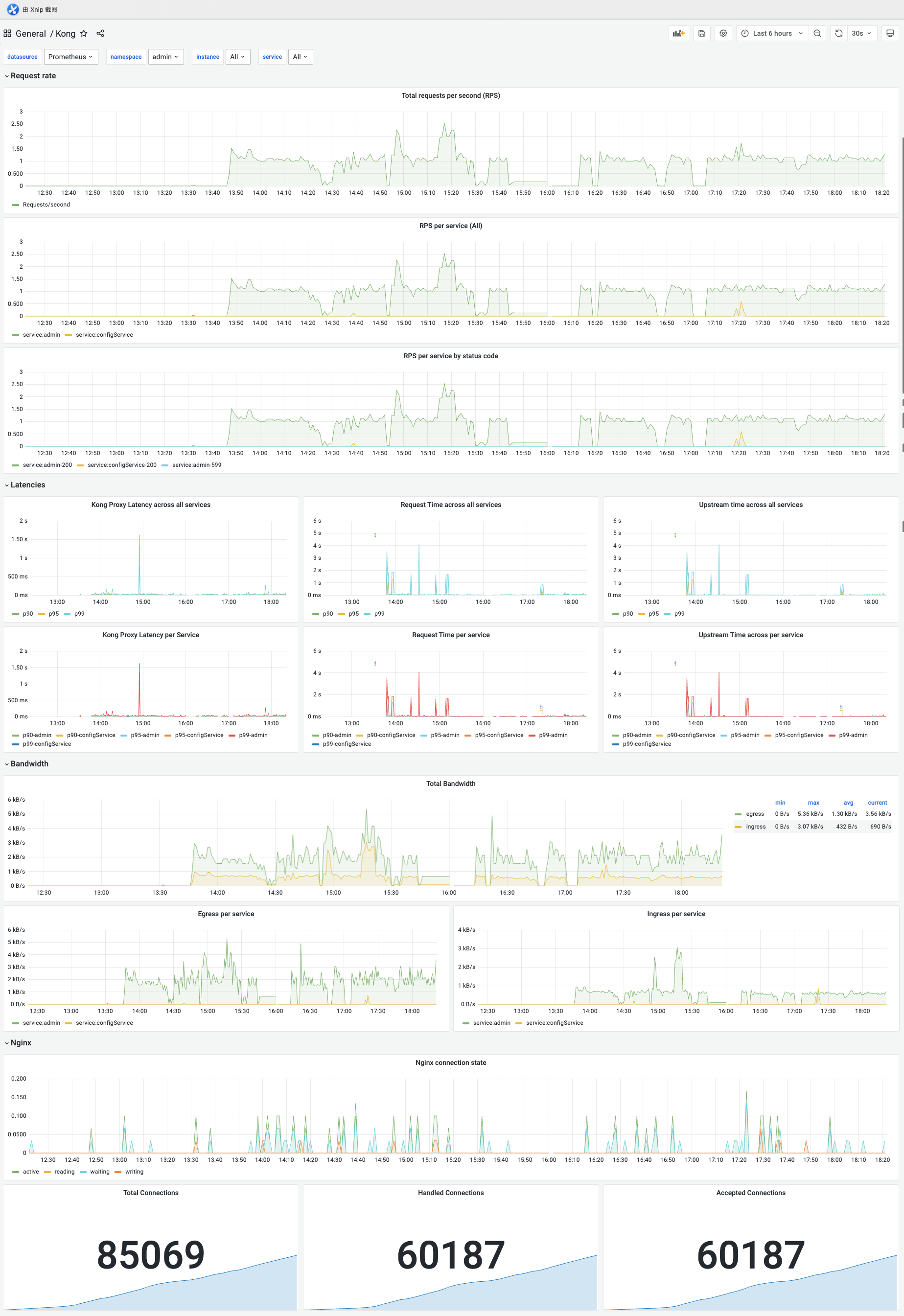
2.DataService监控-kong看板
显示请求速率、影响潜在因素、发送/接收带宽、Nginx连接数
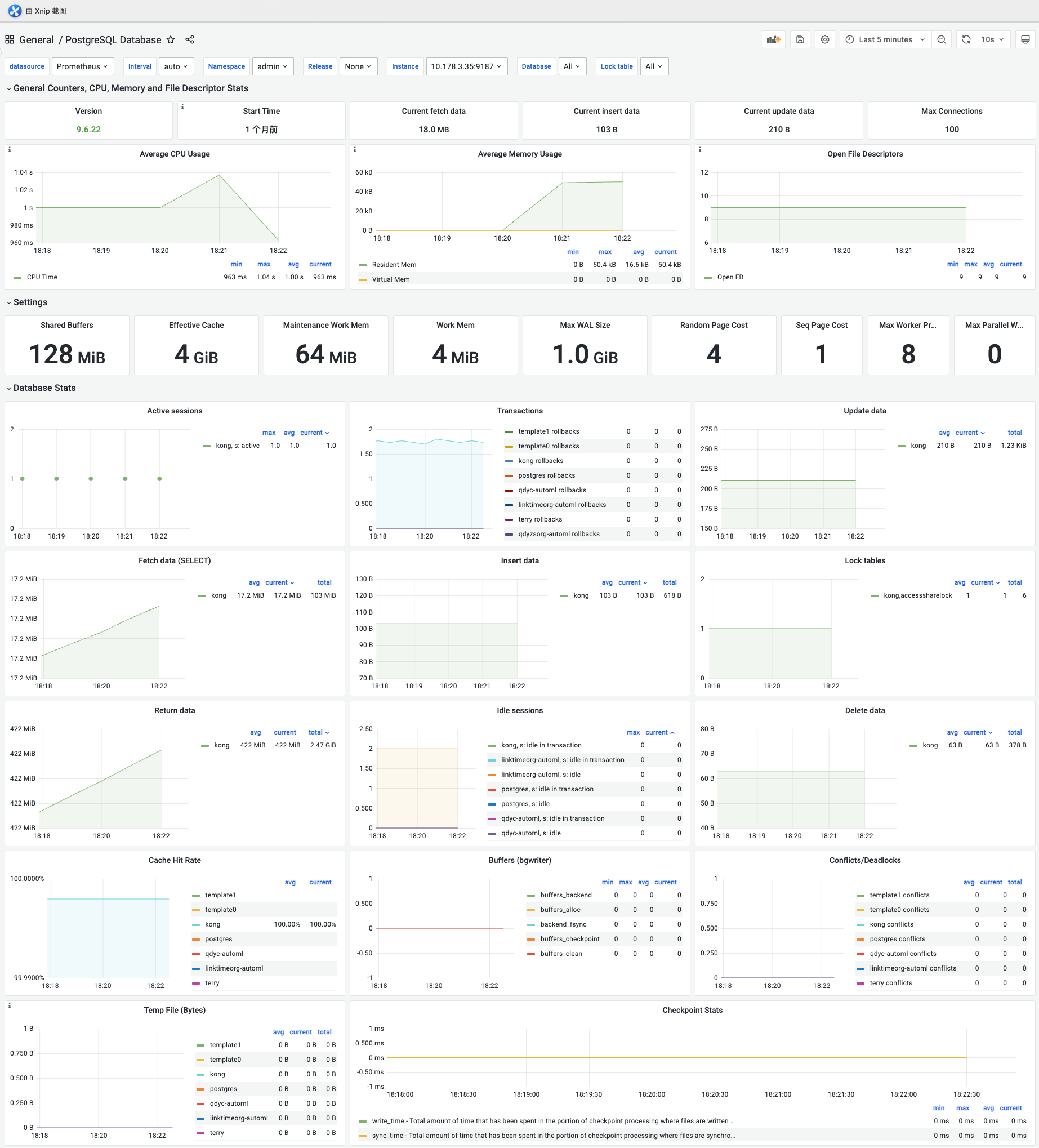
3.DataService监控-pgsql看板
显示版本/数据量/CPU/内存等情况、设置、数据库状态
4.DataService监控-es看板
显示关键性指标、分片、JVM垃圾收集、translog、CPU、内存、缓存等监控数据
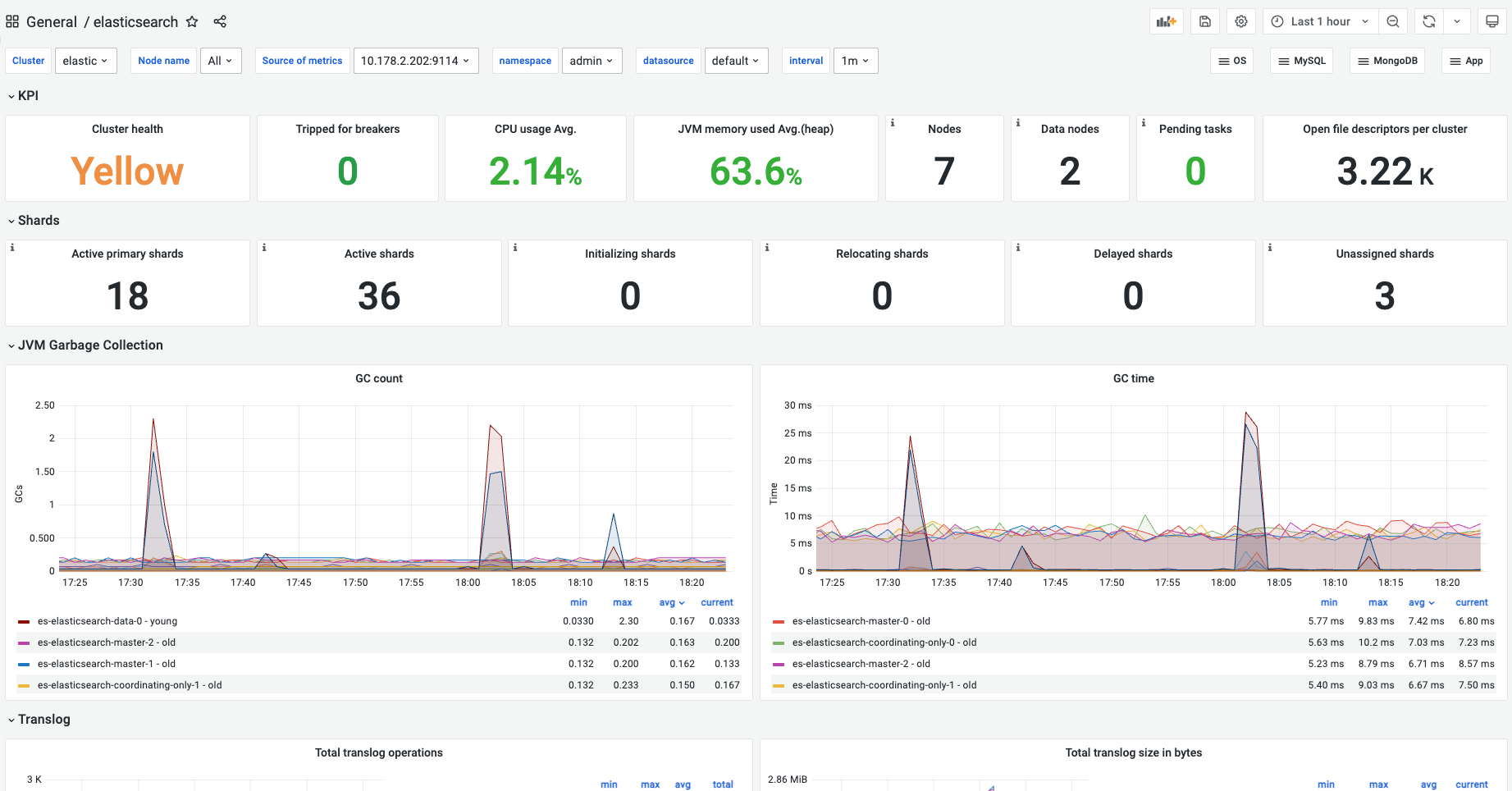
5.httpfs-gateway监控看板
显示httpfs-gateway相关监控数据
System Info
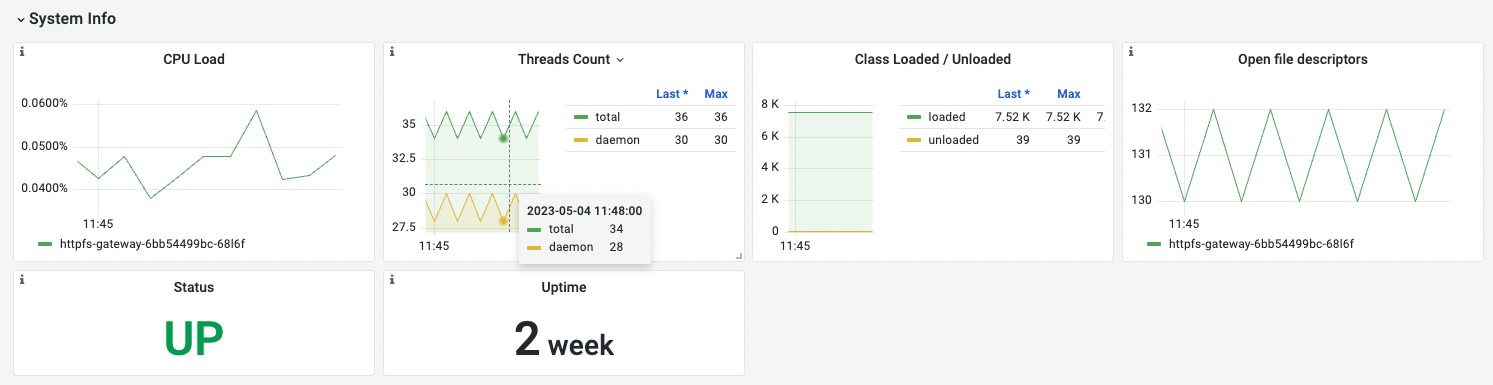
| 名称 | 指标含义 | 场景说明 |
|---|---|---|
| CPU Load | cpu 负载 | 长时间过高会导致服务不稳定,需要排查原因 |
| Threads Count | 线程总数量和守护线程的数量 | 持续增长会导致资源紧张,需要排查原因 |
| Class Loaded / Unloaded | 平均每秒被垃圾回收器回收的对象数 | Class Unloaded 需要排明原因 |
| Open file descriptors | 进程打开的文件描述符数量 | 进程打开了太多文件描述符, 会导致系统资源紧张,进而影响系统的性能和稳定性 |
说明:
- Class Loaded:指当前 JVM 中已经被加载的类的数量,包括应用程序及其依赖的类库等所有已经被加载的类。
- Class Unloaded 指标表示已卸载的类的数量。这个指标可以用于监控应用程序的内存使用情况,以及检测是否存在内存泄漏等问题。
JVM Memory
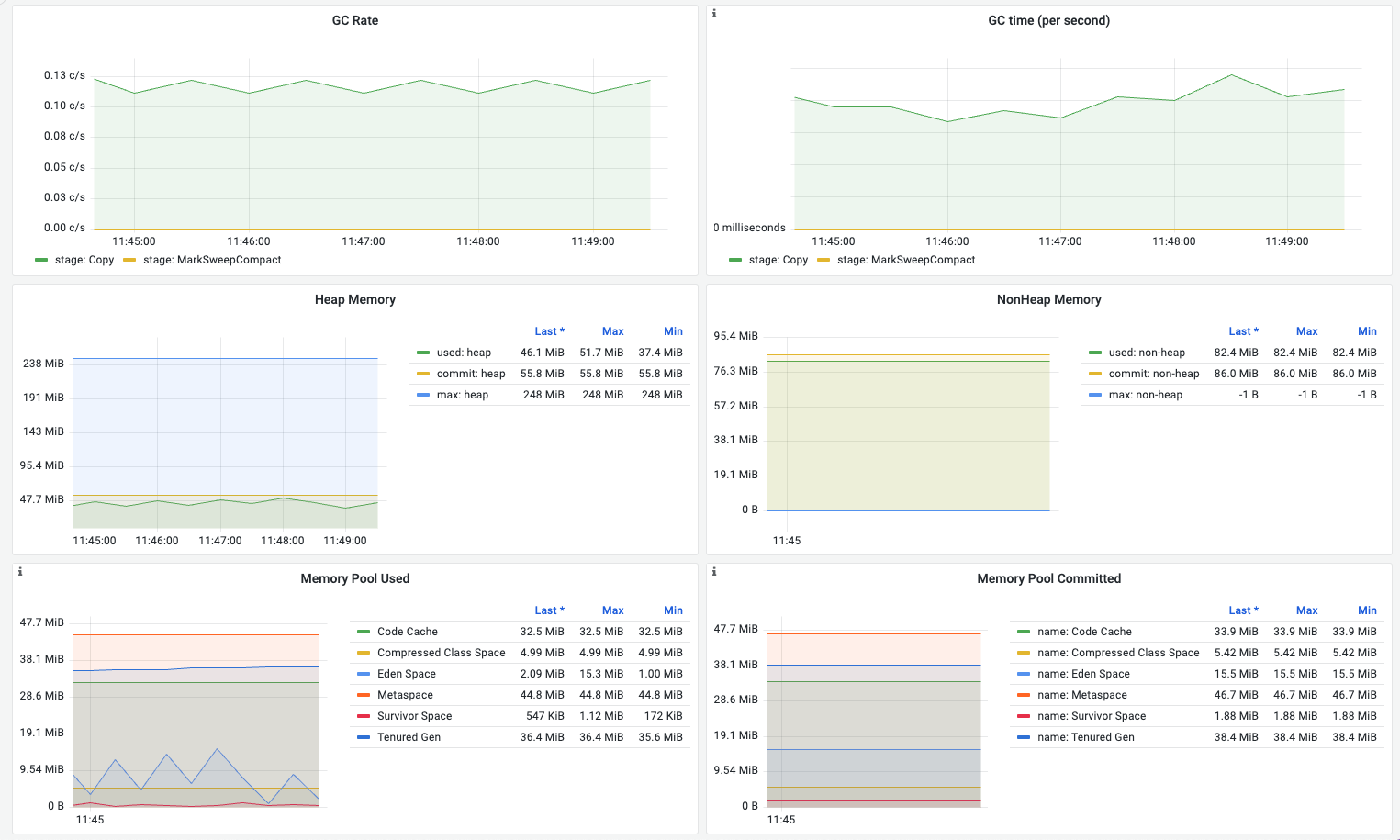
| 名称 | 指标含义 | 场景说明 |
|---|---|---|
| GC Rate | 平均每秒执行GC的次数(copy 和 mark-sweep-compact 阶段) | 频繁的垃圾回收可能会导致应用程序的暂停和延迟 |
| GC time (per second) | 平均每秒执行GC完成的时间花费 | 异常增高需要调整资源配置/jvm参数配置 |
| Heap Memory | 堆内存的使用情况(used/committed/max) | used 持续接近commited(或者max), 内存紧张,影响应用稳定性,可能存在内存泄漏或者资源不足需扩容 |
| NonHeap Memory | 非堆内存的使用情况(used/committed/max) | - |
| Memory Pool Used | 不同区的内存使用量 | 在 Java 中,内存池是一种管理内存的机制,它将 JVM 堆内存划分为多个不同的区域,以支持更有效地管理内存 |
| Memory Pool Committed | 不同区的内存提交量 | - |
注意
- GC time 可以用来衡量垃圾回收器的性能,通常越短越好。在监控和调优 JVM 性能时,GC time 是一个重要的指标,可以用来确定是否需要调整垃圾回收器的参数或者采用其他垃圾回收策略
- Heap Memory 堆内存的使用情况(used/committed/max)
- “used”表示Java虚拟机当前正在使用的内存大小,以字节为单位;
- “committed”表示已经分配给Java虚拟机的内存大小,保证可供使用。随着内存被释放回系统或分配给其他用途,这个值可能会随时间变化。不过,它始终大于等于当前正在使用的内存大小;
- “max”表示可用于内存管理的最大内存大小,但其值可能未定义。可用内存的最大大小也可能随时间变化,但当前正在使用和已分配的内存大小始终在这个限制范围内。
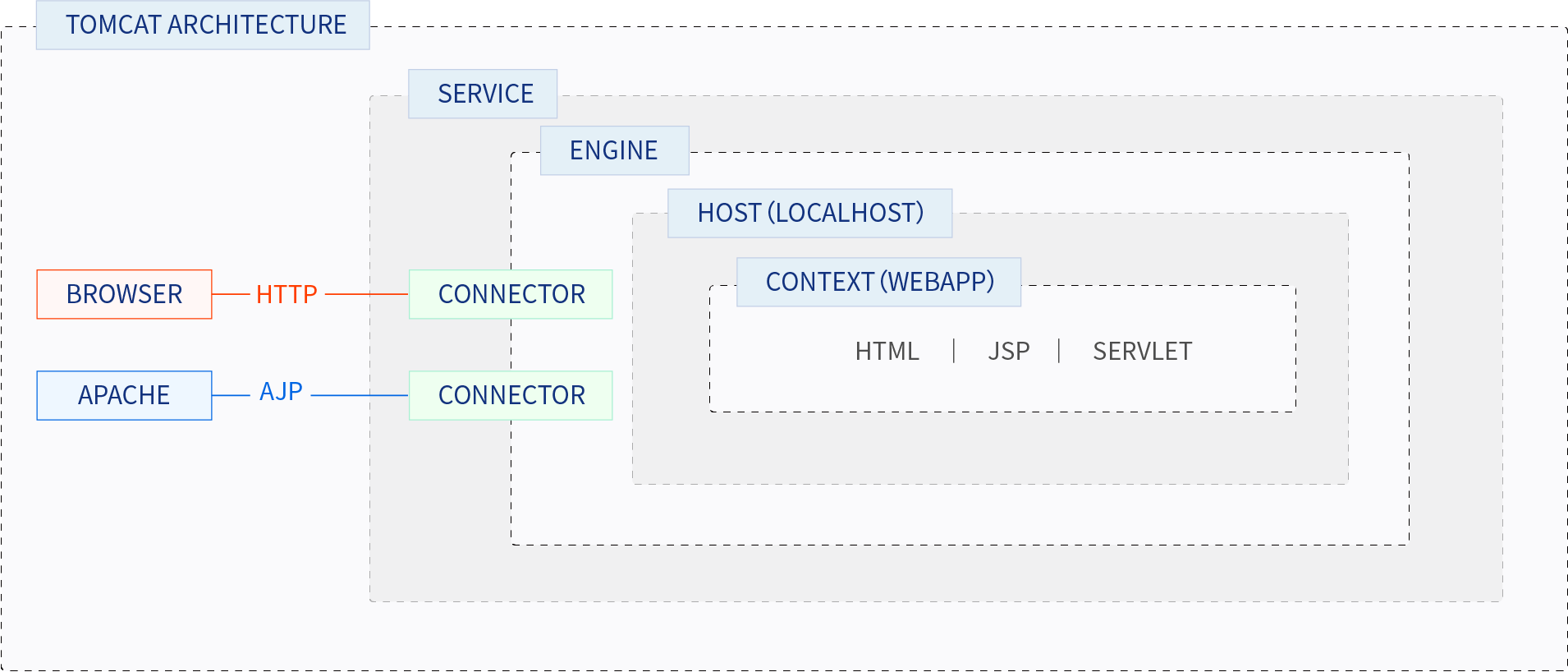
Catalina
Tomcat架构主要由Catalina服务器、连接器、一个或多个服务以及嵌套在服务内部的多个容器组成。这些容器包括引擎,它处理请求并根据引擎的主机返回响应;以及多个上下文,它们是组成Web应用程序的组件,如HTML文件、Java Servlet和JSP页面。
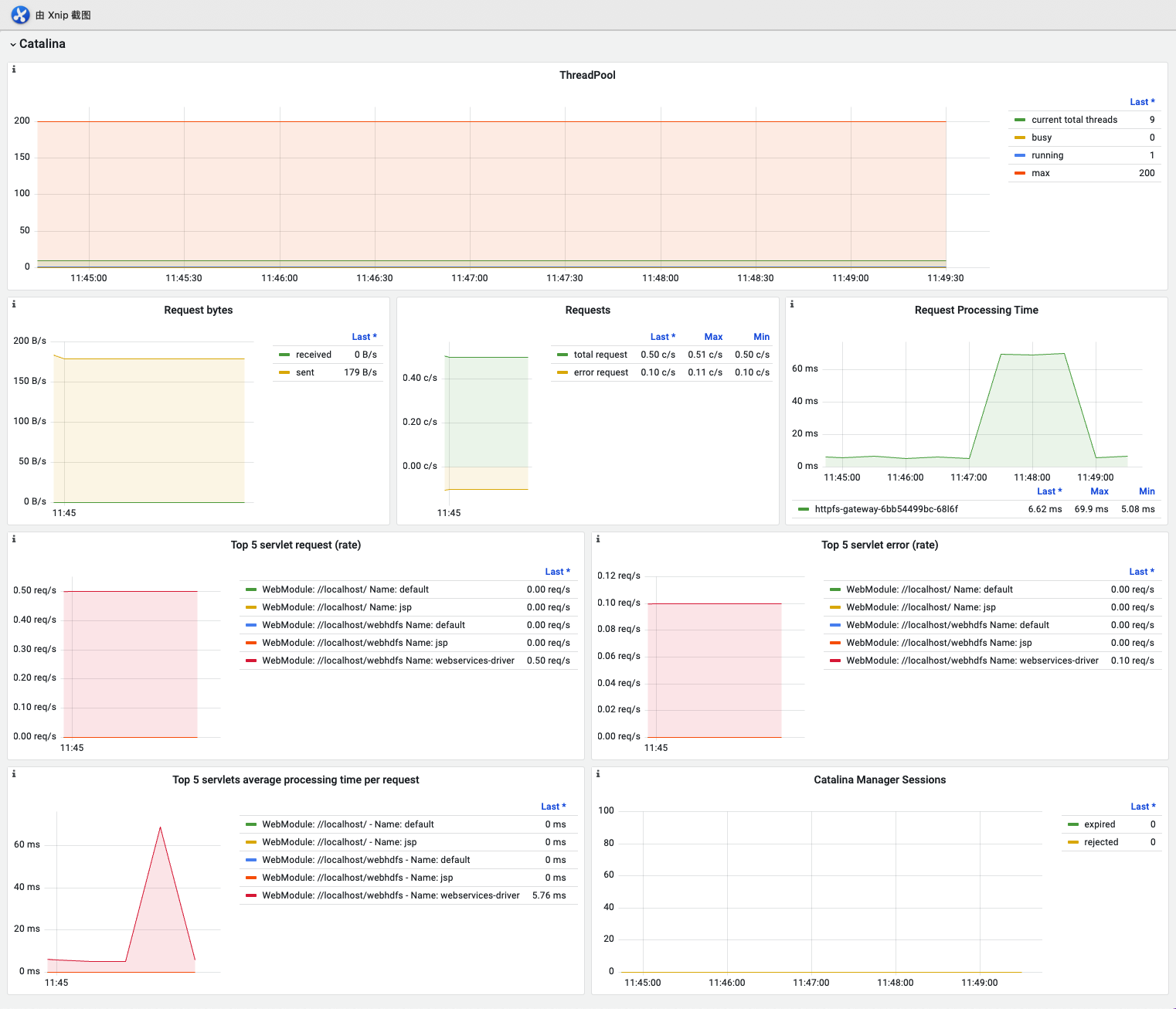
| 名称 | 指标含义 | 场景说明 |
|---|---|---|
| Catalina ThreadPool | busy: 正在处理请求的线程数 running: 运行中的线程数,可能没有在处理请求max: 线程池中最大的线程数current total thread: 当前线程池中的线程数 | 如果 running 数量非常高,但 busy 数量很低,可能意味着线程池中存在空闲线程,但它们却没有被正确地分配给请求, 需要排查total thread 持续高可能需要扩容 |
| Request bytes | 每秒收发流量大小 | 太多的请求会导致资源紧张,影响服务稳定性,可以考虑扩容 |
| Requests | 每秒处理的请求数 | 太多的请求会导致资源紧张,影响服务稳定性,可以考虑扩容 |
| Request Processing Time | 每秒处理请求的耗时 | 请求耗时长时间增大可配告警,同时需排查 |
| Top 5 servlet request (rate) | 每秒请求数前5的接口 | |
| Top 5 servlet error (rate) | 每秒请求数前5的报错接口 | 配告警,同时需排 |
| Top 5 servlets average processing time per request | 耗时前5的接口 | 请求耗时长时间增大可配告警,同时需排查 |
| Catalina Manager Sessions | expire 过期会话的数量,即已经超过会话超时时间而被自动清理的会话数量rejected指的是 Tomcat 中由于会话管理器已满而被拒绝的会话数量。 | expire值较高时,可能需要考虑调整会话超时时间以提高 Tomcat 的性能 rejected值较高时,可能需要考虑增加会话管理器的大小或者优化应用程序代码,以提高 Tomcat 的性能。此外,会话管理器的拒绝行为也可能会影响应用程序的稳定性和用户体验,因此需要及时采取措施解决这个问题。 |
说明
- 线程池是一组预先创建的线程,它们可用于处理多个并发请求。当一个请求到达时,一个线程从池中取出并处理请求。当请求处理完成后,线程将返回线程池,等待下一个请求。通过使用线程池,可以减少线程创建和销毁的开销,从而提高系统的性能和吞吐量。
6.kerberos监控看板
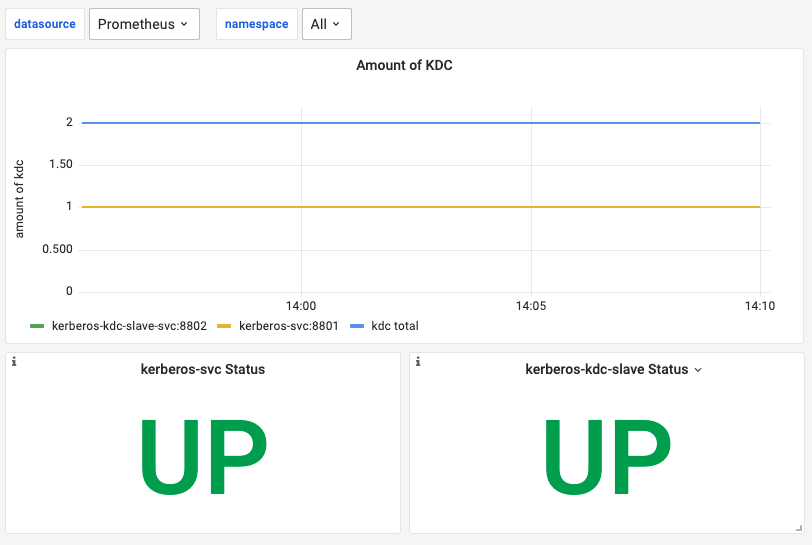
| 名称 | 指标说明 | 补充 |
|---|---|---|
| Amount of KDC | 统计master/slave kerberos 服务的数量 | |
| kerberos-svc Status | 判断 master 是否可用 | 通过是否能完成kinit检测 |
| kerberos-kdc-slave Status | 判断 slave 是否可用 | 通过是否能完成kinit检测 |
异常举例
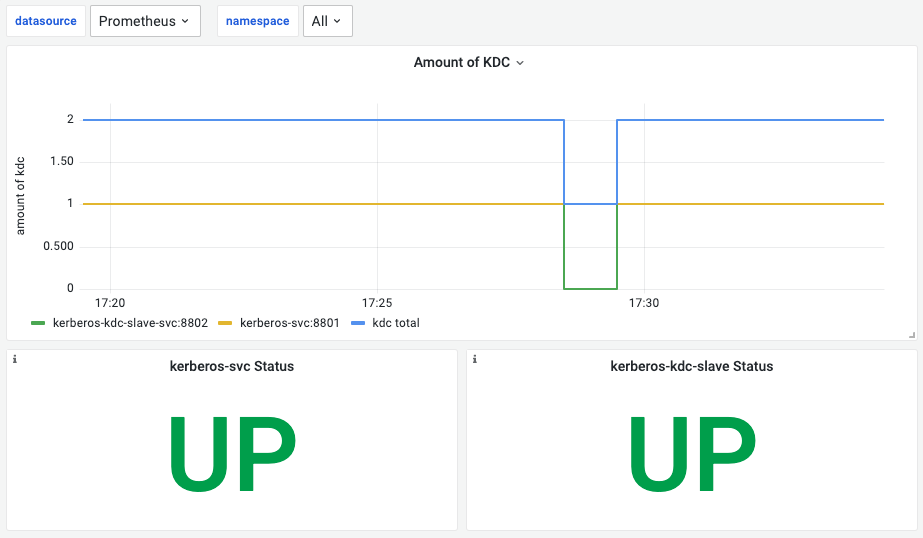
以上 kerberos 看板监控了表明 slave 出现了不可用,master 可用
7.hue监控看板
Basic
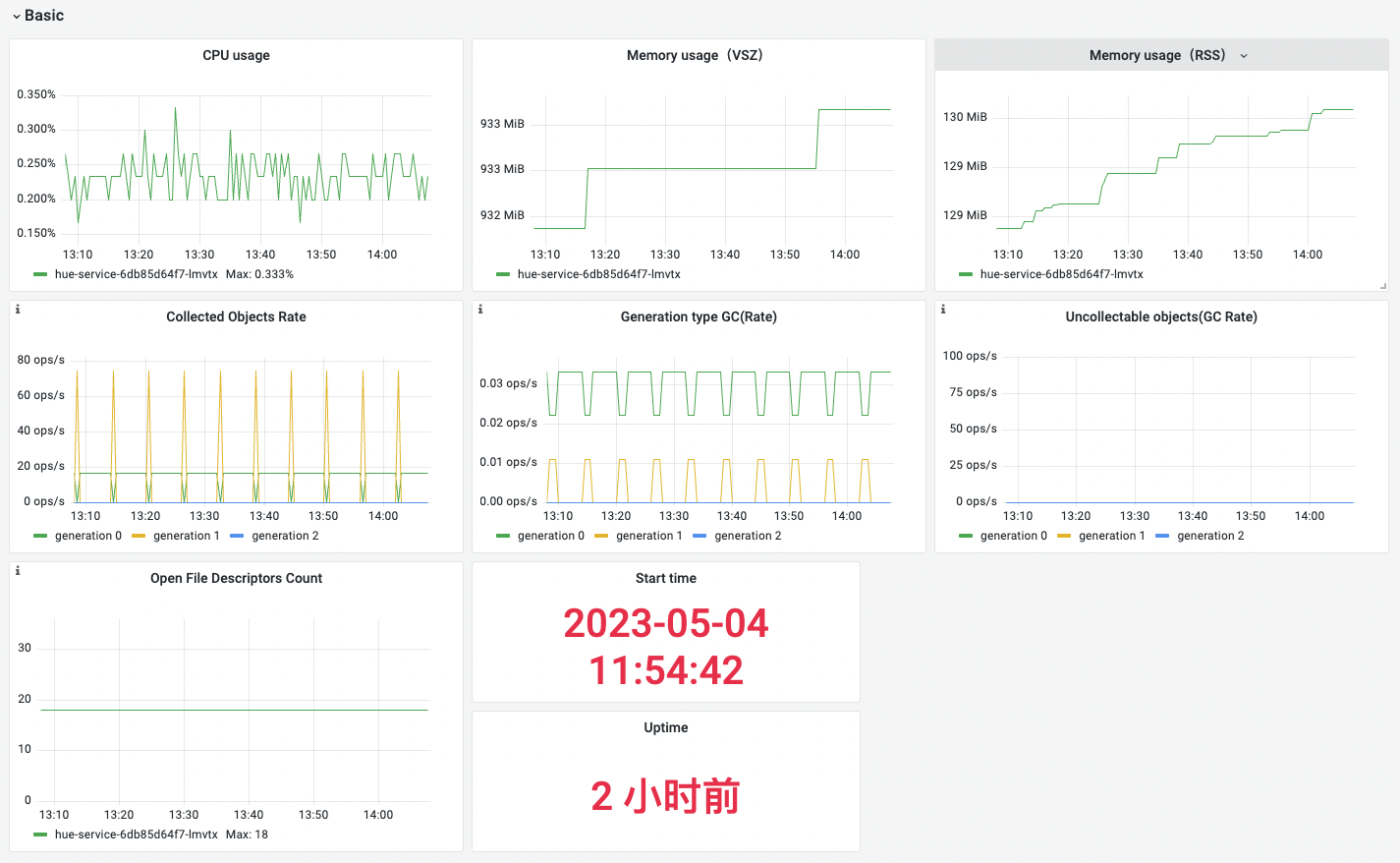
| 名称 | 指标含义 | 场景说明 |
|---|---|---|
| Memory usage(VSZ) | 虚拟内存使用量 | 过高说明存在内存泄漏或内存占用过多,需要进一步进行分析和优化 |
| Memory usage(RSS) | 常驻内存使用量 | 持续增长可能存在内存泄漏 |
| Collected Objects Rate | 平均每秒被垃圾回收器回收的对象数 | 过高说明可能存在内存泄漏 |
| Generation type GC(Rate) | 平均每秒圾回收器触发的次数 | 过高说明可能存在内存泄漏 |
| Uncollectable objects(GC Rate) | 平均每秒未被垃圾回收器回收的对象数 | 应用程序中存在内存泄漏或循环引用等问题 |
| Open File Descriptors Count | 进程打开的文件描述符数量 | 进程打开了太多文件描述符, 会导致系统资源紧张,进而影响系统的性能和稳定性 |
Hue
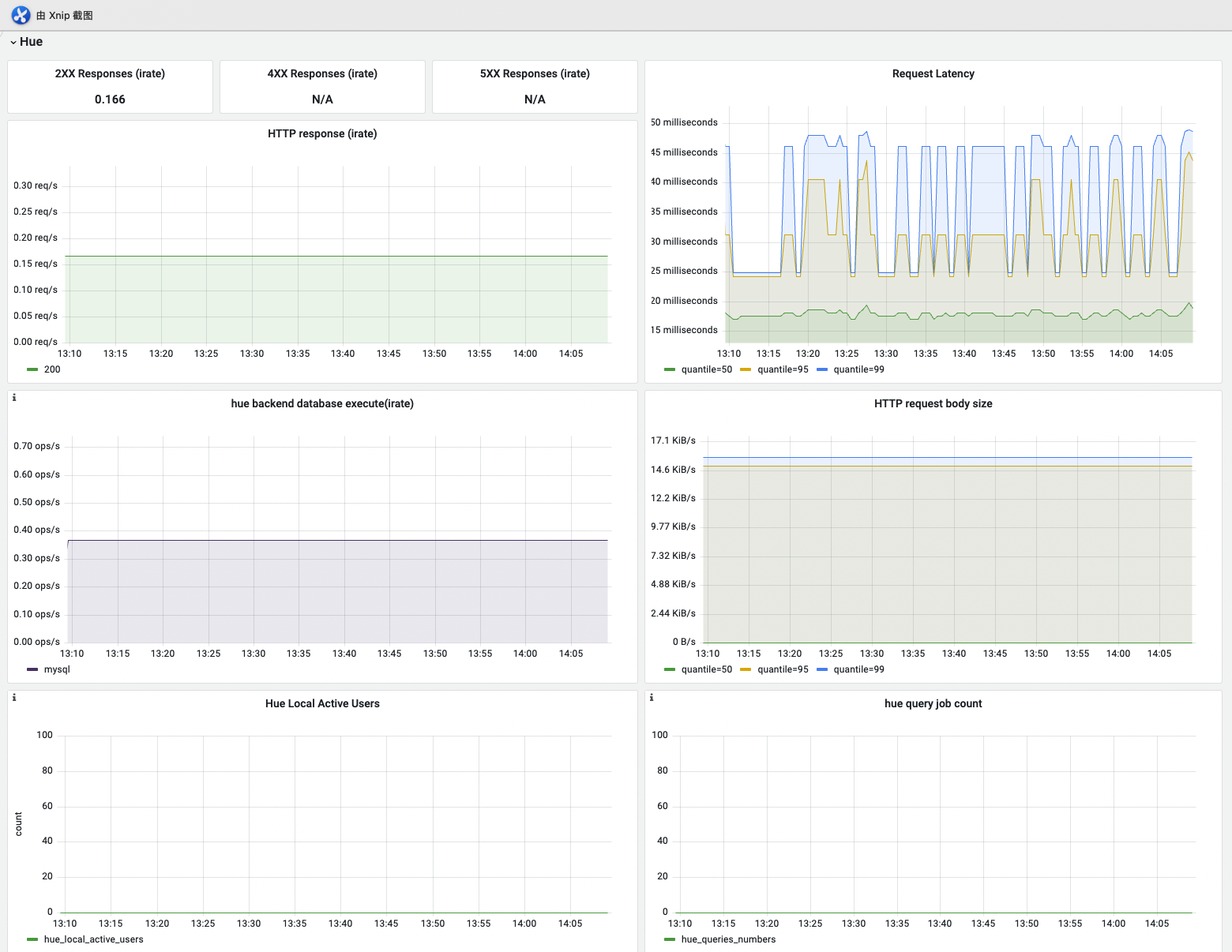
| 名称 | 指标含义 | 场景说明 |
|---|---|---|
| HTTP response (irate) | 平均每秒http响应次数 | 判断是否服务请求压力大,是否需要增加资源 |
| Request Latency | http响应延迟时间,包括p99/95/50 | 系统资源紧张, 网络异常可能导致服务的响应时间变长;也可能是依赖的httpfs-gateway, hs2 服务耗时较长,需要排查 |
| hue backend database execute(irate) | 平均每秒的数据库操作次数 | 判断系统负载是否过大 |
| HTTP request body size | 平均每秒htttp响应的body size | 判断系统负载是否过大 |
| Hue Local Active Users | 当前活跃hue用户数量 | 可辅助判断负载过高是否由于使用用户太多 |
| hue query job count | hue用户提交运行的查询数量 | 可辅助判断负载过高原因 |
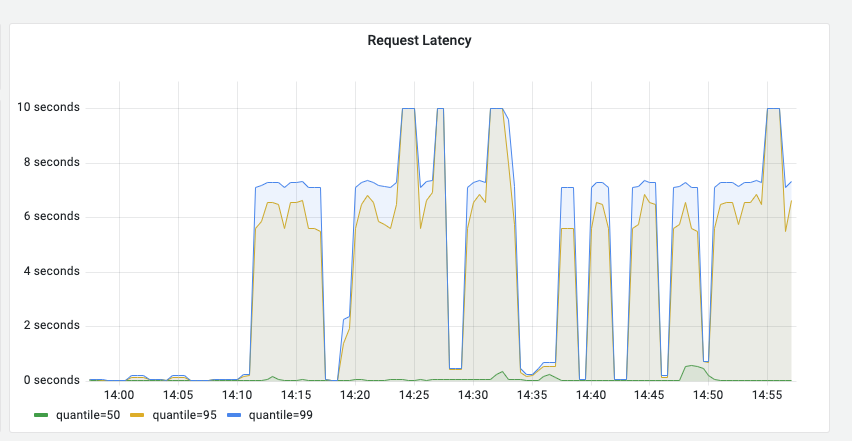
异常举例
当httpfs-gateway 请求比较慢的时候,会导致请求时延增加,如下:
8.Kafka监控看板
Kafka Cluste - Kafka集群状态概览
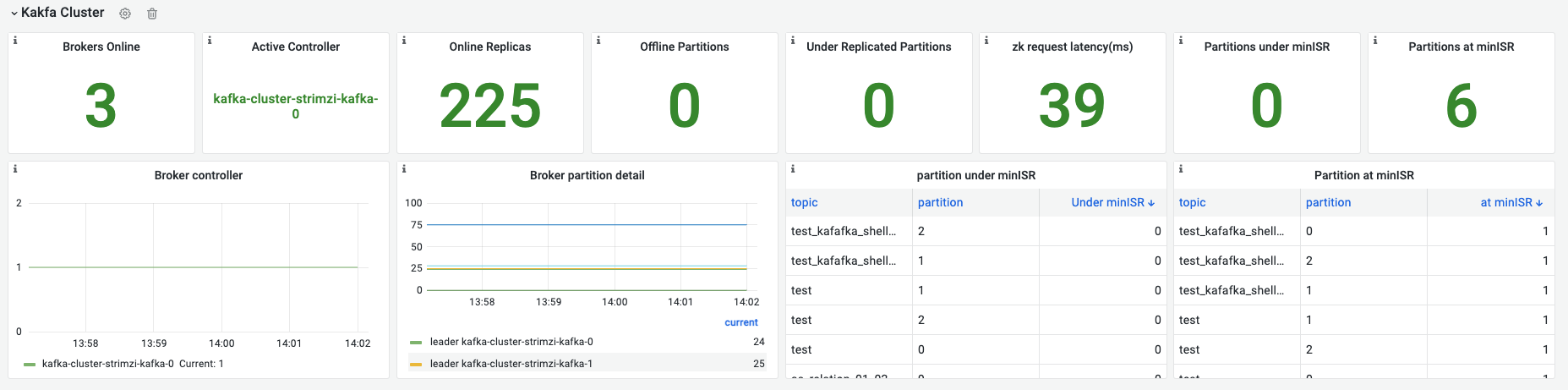
此模块为了快速识别kafka健康状态,初步指引问题方向
- 正常运行
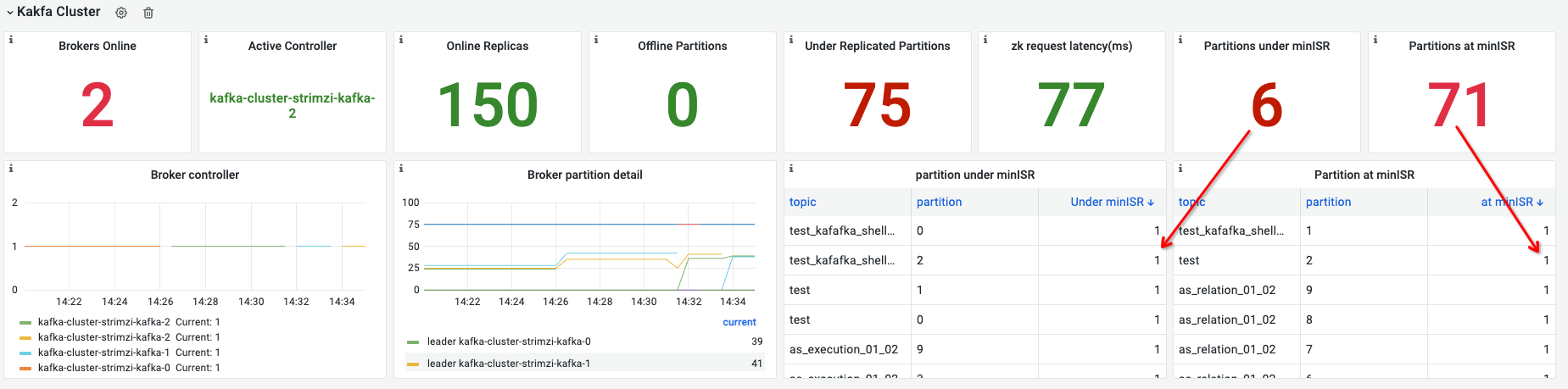
- 异常情况
- 有broker重启,当broker全部异常时拿不到数据。下图是手动重启controller时的情况,kafka会重新选出controler,与上一张图对应有个有6个3副本的partition由于broker 0重启变得不可用,一般情况下:单节点异常导致的 under minISR <= 集群正常时的 at minISR 。
说明:Prometheus采集间隔是30s为避免告警过于敏感,设置异常时间为60s至少两个采样允许自动恢复
| 名称 | 指标含义 | 场景举例 | panel说明 | 指标告警说明 |
|---|---|---|---|---|
| Brokers Online | kafka集群当前正常运行的broker数据 | 确认broker是否健康:管理员在知道所查看kafka节点数的情况下确认是否有broker异常 | metrics中没有broker total值,所以当前只做了broker小于2会变红 | 有broker down需要告警实现:云平台有pod重启的告警,不需要额外做 |
| Active Controller | 显示当前controller。集群无Controller时会展示N/A。 | 用于确认集群的controler节点,便于后续运维操作。 | 一般都有且仅有一个controller,大部分数据不在replicas同步的情况都和Controller的异常有关 | =0 需要告警实现:持续60s告警,一般切换Controller很快(秒级) |
| Online Replicas | 所有topic的replicas副本总数 | 可能上升(topic创建)和下降(topic删除),正常运行时维持稳定 | ||
| Under Replicated Partitions | Partition的副本更不上leader已经掉出了ISR | 用于辅助确定Topic健康状态:用于监控Partition的健康情况 | 正常时为0,不为0常见于broker重启或是网络波动、磁盘写满引起replicas同步失败 | 大于0需要告警实现:持续60s告警,一般为kafka重启导致,需要关注topic不可用情况 |
| zk request latency | zk访问时延 | 主要是确认访问zk是否有问题,如果时延很大或数据为空都为异常情况,需要检查kafka与zk的连接情况 | 另外做zk的告警 | |
| Offine Partition Count | 无法访问的partiton | |||
| Partitions at minumum ISR | 正好处于最小同步副本数的Partiton数量 | 用于辅助确定Topic健康状态::如果有broker down会出现Partition not work进而导致topic不能使用,辅助保证kafka的高可用状态 | 理想状态为0,处于较高值时需要注意 | |
| Partitions under minumum ISR | 小于最小同步副本数的Partiton数量 | 出现>0时partition所属topic不能正常使用 | >0需要告警实现:持续60s告警,一般为kafka重启导致,需要关注topic不可用情况 | |
| Controller Info | controller历史变化趋势 | 确认kafka controller是否发生了变化 | ||
| Broker partition detail | 说明broker上partition副本分布情况 | leader – 用于确定在kafka上leader是否分布均匀online – 用于确认kafka中数据是否分布均匀offline - 用于定位在replicas不同步时是那个broker的问题 | 一般情况3节点的partition leader基本一致一般情况3节点的offline基本一致一般不会有offline的partition,出现即表示kafka有问题 | |
| Partition under minISR | 小于最小同步副本数的partiton详情,under minISR列为1代表改topic partition处于”under minISR”的状态 | 获知异常partition详情,出现该情况说明partition中的副本间数据同步异常,需要排查情况 | 正常时为列表中的under minISR列的值都为 | |
| Partition at minISR | 处于最小同步副本数的partiton详情,at minISR列为1代表改topic partition处于”at minISR”的状态 | 获知有高可用风险的partition详情,一般要求partition replicas > minISR保证一定冗余以达到更高的可用性 | at minISR值为1不影响使用,但会有服务高可用方面的风险问题理想情况 at minISR 列都为0,如果有1需要考虑调整topic配置 | - |
Kafka topic
对topic信息进行展示,用与判断topic是否存在、数据大小、数据均衡性、消费者数量。帮助做“生产-消费”流程的优化。
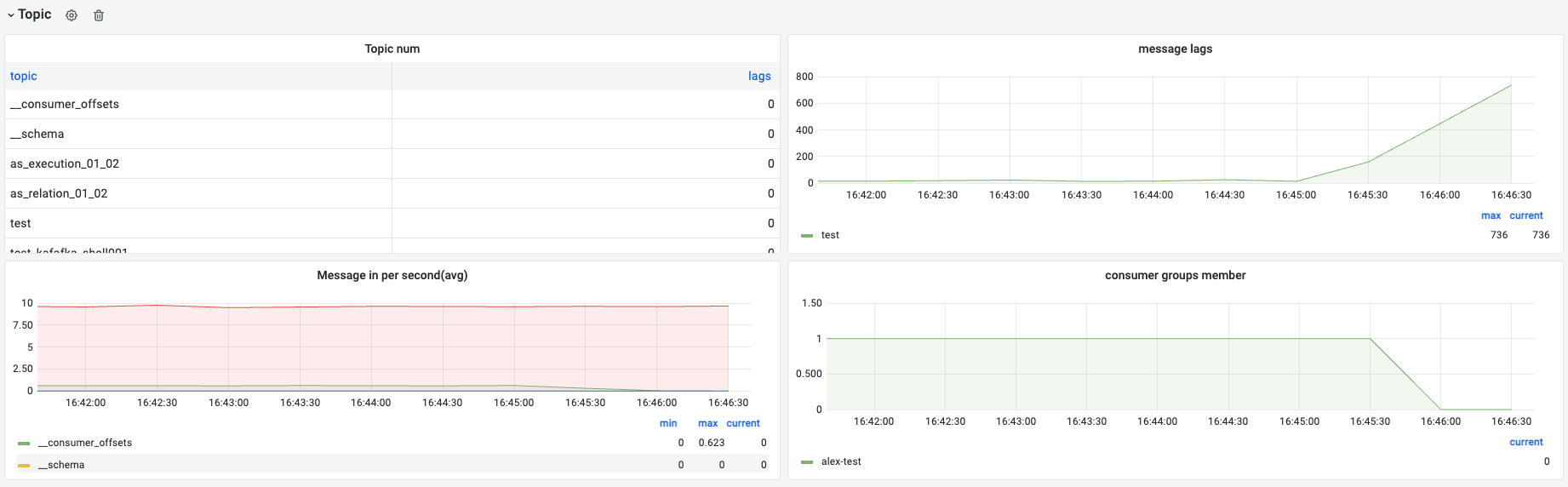
下图场景为启动了一个生产者向“test”这个topic每发送一条数据sleep 100ms,在alex-test这个消费组下启动了一个消费者消费一段时间后停止。可以看到topic qps接近10条/s、消费者停掉后message lags明显上升。broker数据均衡,partition数据均衡。
| 名称 | 指标含义 | 场景举例 | 补充 | 指标情况说明 |
|---|---|---|---|---|
| Topics | topic数量变化 | kafka集群全部topics数量应该有一个合理规划,避免一个kafka有太多不同业务的topics,否则会非常难做运维管理 | ||
| Message lags | topic消息积压情况 | 确认是否有消息积压,如果一直上涨说明消费者处理有问题 | 一般在消息量较大连续发送的情况下,消费会有一定积压,这个和指标采集的间隔有关。正常情况不会一直上涨,有升有降稳定在一个较小的近0值附近依赖kafka exporter | |
| message in per seconds(avg) | topic每秒新增消息平均值 | 使用中topic流量确认 | 依赖kafka exporter | 【可选】考虑是否做一个消息流量过大的告警,需要根据业务实际情况定。比如 > 100,000 per seconds时告警 |
| consumer groups member | 消费组基本信息与消费组中的成员数量 | 确认消费组是否有成员消费者,一般是用于合理规划同消费组的消费者数量:1. partition replicas为消费者数量的整数倍 | 需要保证:消费者数量 <= partition replicas数量,否则会有空闲的消费者,特别是在flink这种流式处理引擎中避免因为消费者设置的数量过的而导致资源浪费依赖kafka exporter | |
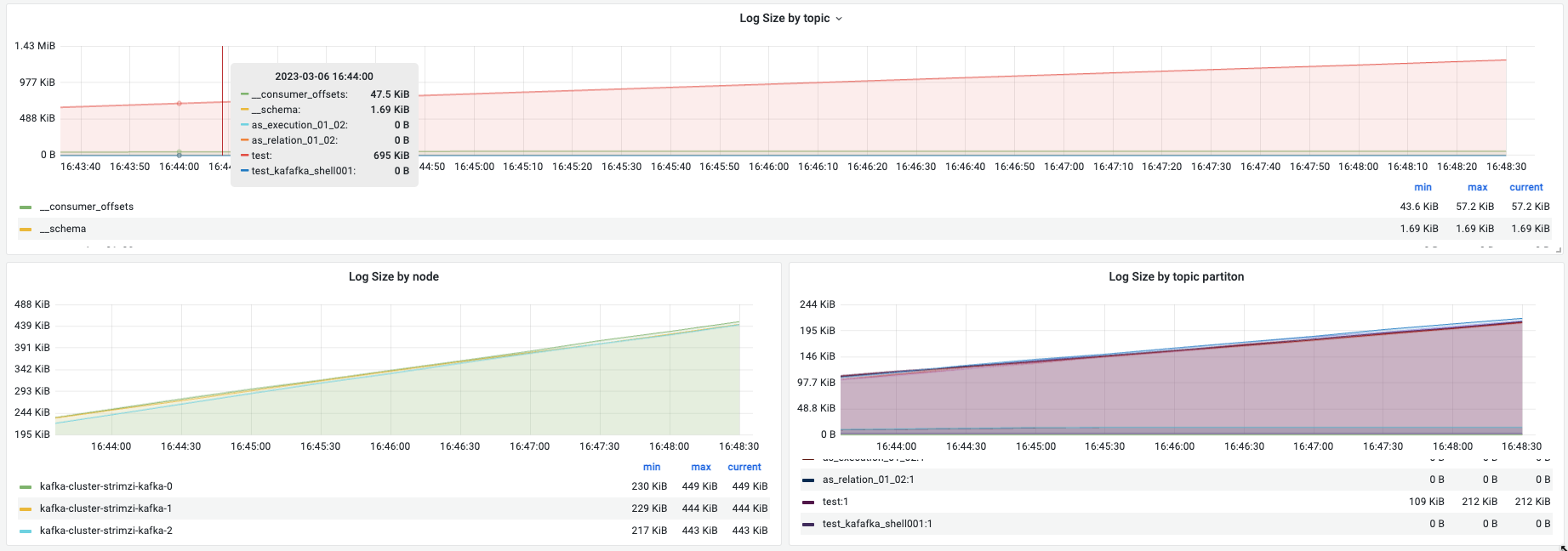
| log size by topic | topic的数量大小 | 对比不同topic占用存储大小,一般和topic流量相关。如果有topic的流量明显比其他的大(数量级差异)可以根据存储考虑要不要拆分kafka。 | ||
| log size by node | 每个broker的数据大小 | 用于确认broker上的数据量 | 应该设置告警,可用空间 < 30%实现:持续10s–本质是出现就告警 | |
| log size by partition | 单个partition 的数据大小 | 一般是在同一个topic下进行比较,确认是否存在数据倾斜。有一个很典型的场景是用户将message key设置成了string “null”导致数据全都写入一个partition | 一般情况下partition的数据是均衡的 | - |
Node
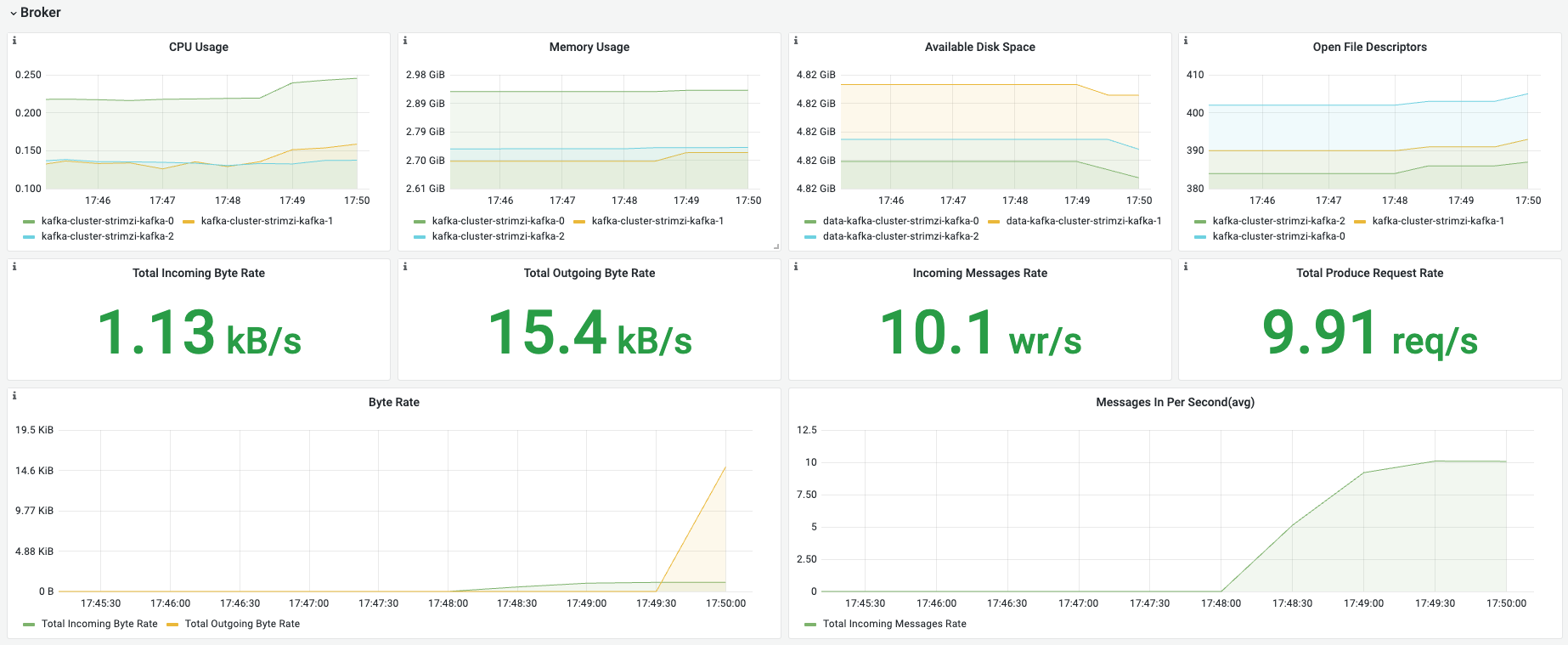
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| CPU Usage | broker CPU使用量,单位C | 确认broker节点负载情况 |
| Memory Usage | broker内存使用量 | 确认broker内存负载情况 |
| Available Disk Space | 可用磁盘空间,或kubelet挂载进来的volume可用空间 | 确认磁盘空间大小 |
| Open File Descriptors | 文件描述符使用情况 | 可能客户场景下系统会有文件描述符最大大小限制 |
| Total Incoming Byte Rate | 每秒写入数据大小 | 避免流量过大,影响k8s node上其他业务 |
| Total Outgoing Byte Rate | 每秒consumer读取数据大小 | 避免流量过大,影响k8s node上其他业务 |
| Incoming Messages Rate | 每秒写入数据条数 | 大致估算写入流量是否匹配 |
| Total Produce Request Rate | 每秒producer的请求数 | 一次请求可以写入一批数据 |
| Byte Rate | 每秒写入、读取数据大小变化趋势 | 观察写入、读取的数量波动情况,以确认流量波峰波谷 |
| Messages In Per Second(avg) | 每秒消息数 | 观察消息了波峰波谷,变化大小。 |
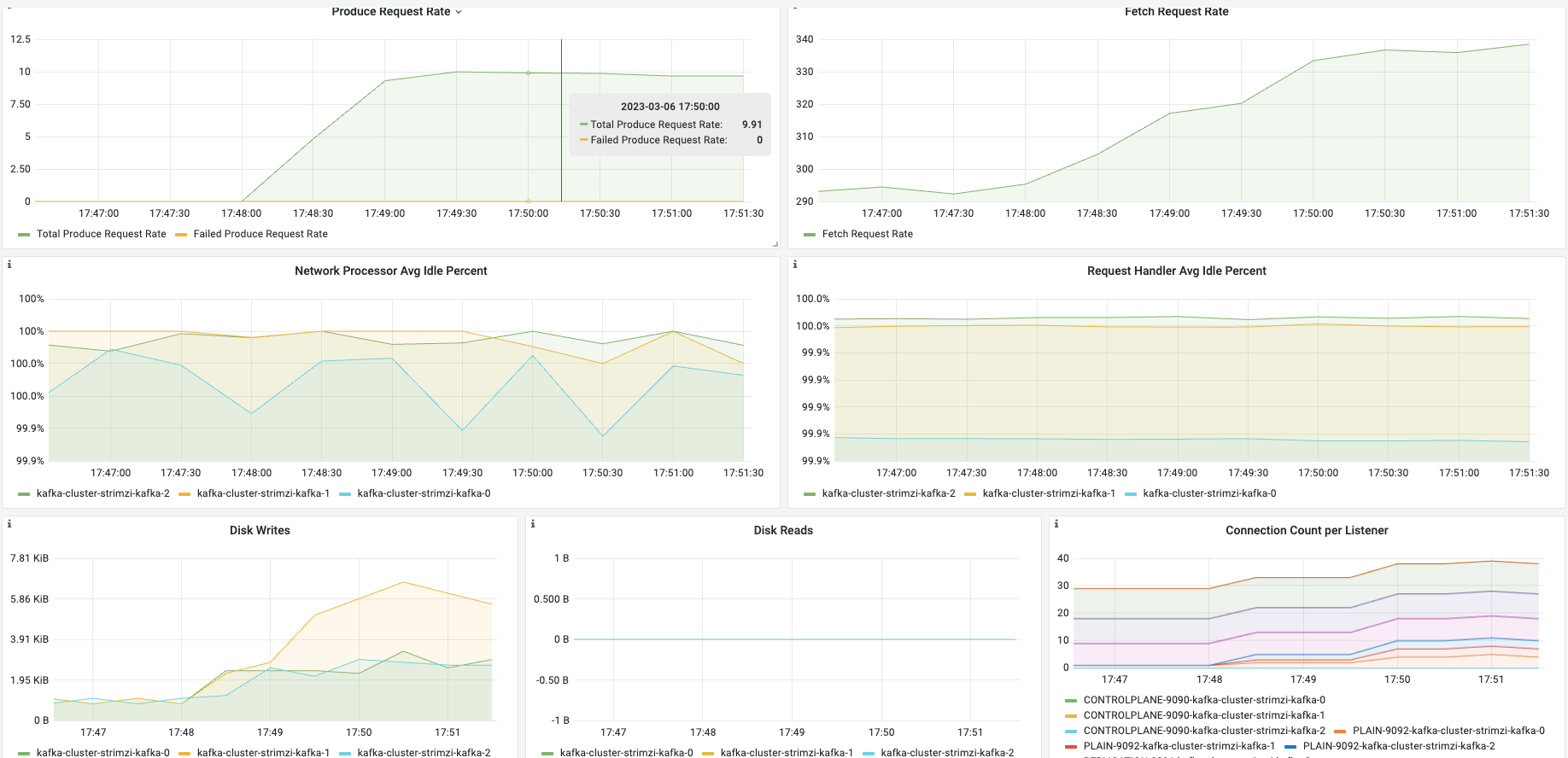
| Produce Request Rate | 生产者请求数量 | |
| Fetch Request Rate | 消费者数据获取请求数量 | |
| Network Processor Avg Idle Percent | Network Processor闲时占比 | 用户在生产消费流量大是观察是否是kafka服务瓶颈 |
| Request Handler Avg Idle Percent | Request Handler闲时占比 | 用户在生产消费流量大是观察是否是kafka服务瓶颈 |
| Disk Writes | 磁盘写入大小变化趋势 | 确认磁盘写入情况 |
| Disk Reads | 磁盘读取大小变化趋势 | 确认磁盘读取情况,若使用内存数据磁盘读为0 |
| Connection Count per Listener | kafka各监听端口的连接数 | 一般消费者连接PLAIN-90929091为集群内部replicas使用避免相互影响 |
JVM
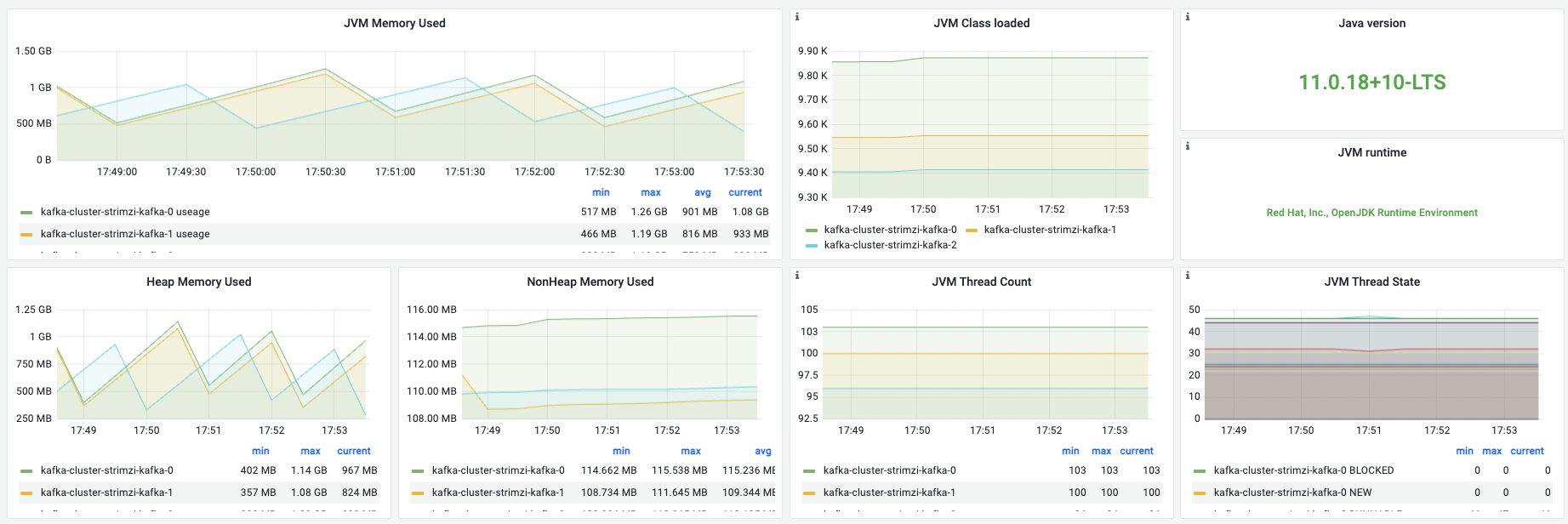
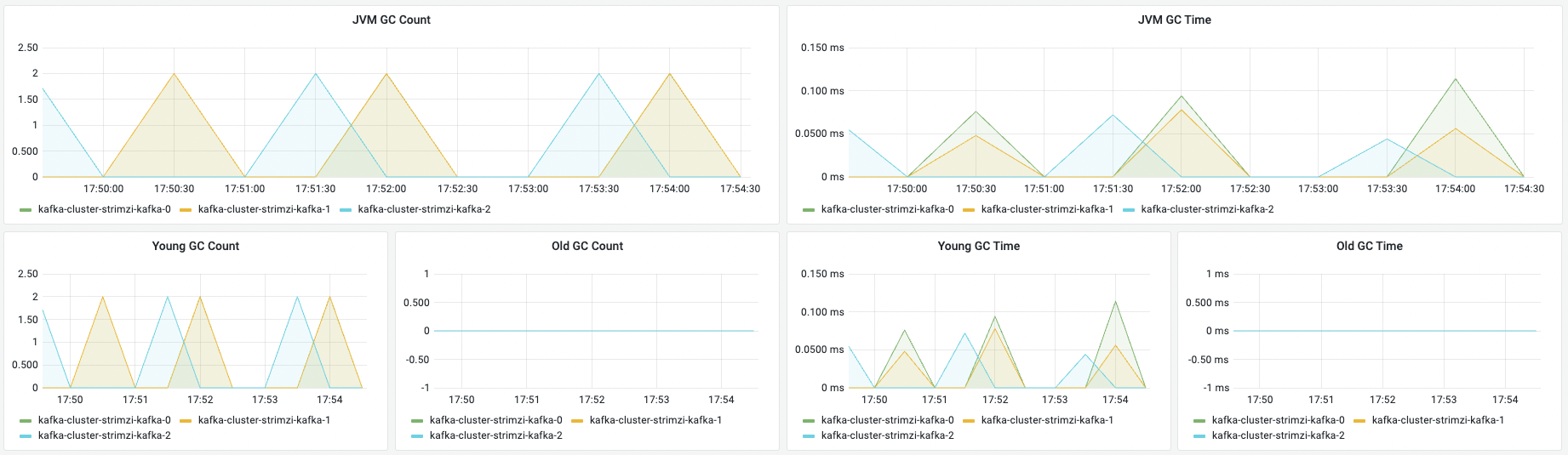
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| JVM Memory Used | JVM内存使用情况,指堆与非堆中的数据大小 | 总的内存使用大小,用户在容器运行内存范围内确认可用空间。 |
| JVM Class loaded | 加载的Class数量 | |
| Java version | java版本信息 | 不同java版本的特性需要额外关注 |
| JVM runtime | vendor与runtime | 确认是否为开源版本 |
| Heap Memory Used | 堆内存 | 该部分为jvm调优核心关注点 |
| NonHeap Memory Used | 非堆内存 | 大部分jvm程序的OOM若不是内存泄露,一般就与非堆使用有关。特别是以netty为底层通信框架的 |
| JVM Thread Count | 线程数 | |
| JVM Thread State | 不同线程状态的线程数 | 协助排查是否有过的线程挂起 |
| JVM GC Count | GC总数 | |
| JVM GC Time | GC总耗时 | |
| Young GC Count | young gc次数 | 一般情况下young gc用与确认是否过于频繁是否需要调大比例 |
| Old GC Count | old generation的GC次数 | 一般相对较少,如果GC频繁需要去人程序问题还是资源问题 |
| Young GC Time | young GC耗时情况 | |
| Old GC Time | old generation的GC耗时情况 | - |
9.Kafka connect监控看板
Overview
确认kafka connect整体状态。Faild Connectors 不为0则异常,需要进行排查处理。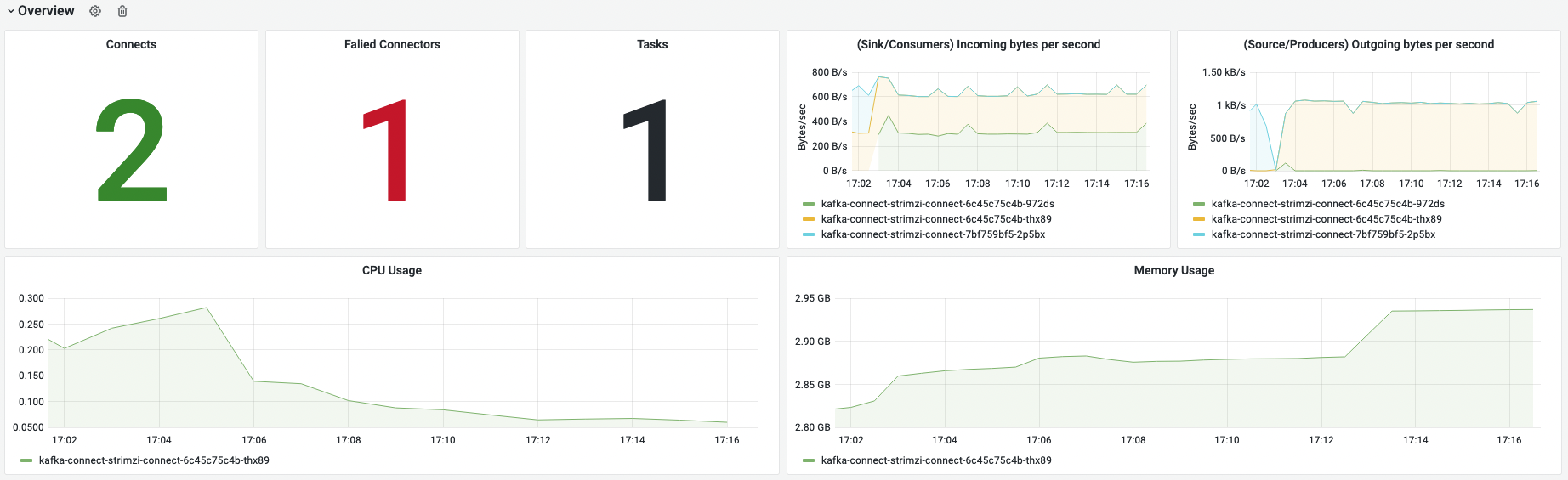
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| Connects | kafka connect实例pod数量 | 主要是确认是否几个connect存活 |
| Failde Connectors | 失败的connector | 要注意处理失败的connect |
| Tasks | 启动的任务数量 | 任务数量要与connetor合计的task数量对应,否则要查看是否有任务没有资源启动 |
| (Sink/Consumers) Incoming bytes per second | connect每秒读kafka的数据量 | 要注意流量大小,如果关注到过大需要查看kafka运行情况是否正常 |
| (Source/Producers) Outgoing bytes per second | connect每秒写kafka的数据量 | 要注意流量大小,如果关注到过大需要查看kafka运行情况是否正常 |
| CPU Usage | CPU使用量 | 确认connect pod CPU负载情况 |
| Memory Usage | 内存使用量 | 确认connect pod CPU内存负载情况 |
Connector
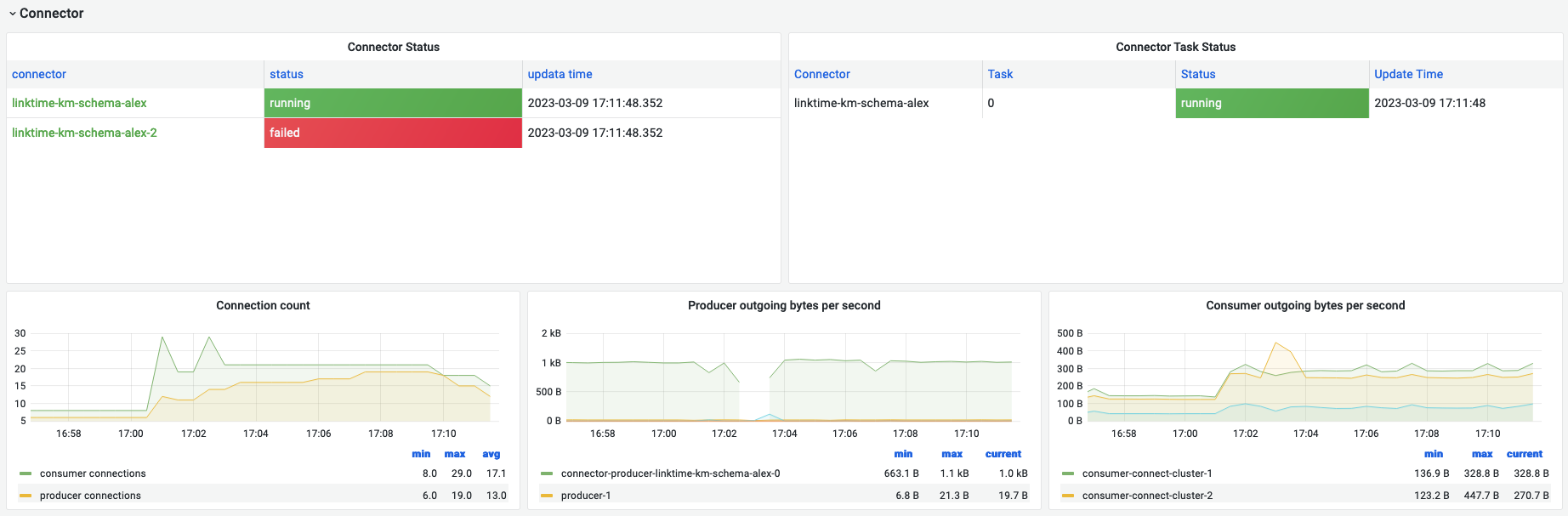
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| Connector status | connector状态情况 | 一眼查看各个任务的状态 |
| Connect task status | 任务状态 | 一眼查看启动task的状态,可能有pending |
| connection count | kakfa connect启动的kafka生产者、消费者数量 | 关注生产者、消费者是否与任务匹配,是否与设定的数量匹配 |
| Producer outgoing bytes per second | connector写kafka每秒数据流量 | 各个生产者数量流量 |
| Consumer outgoing bytes per second | connector读kafka每秒数据流量 | 各个消费者数据流量 |
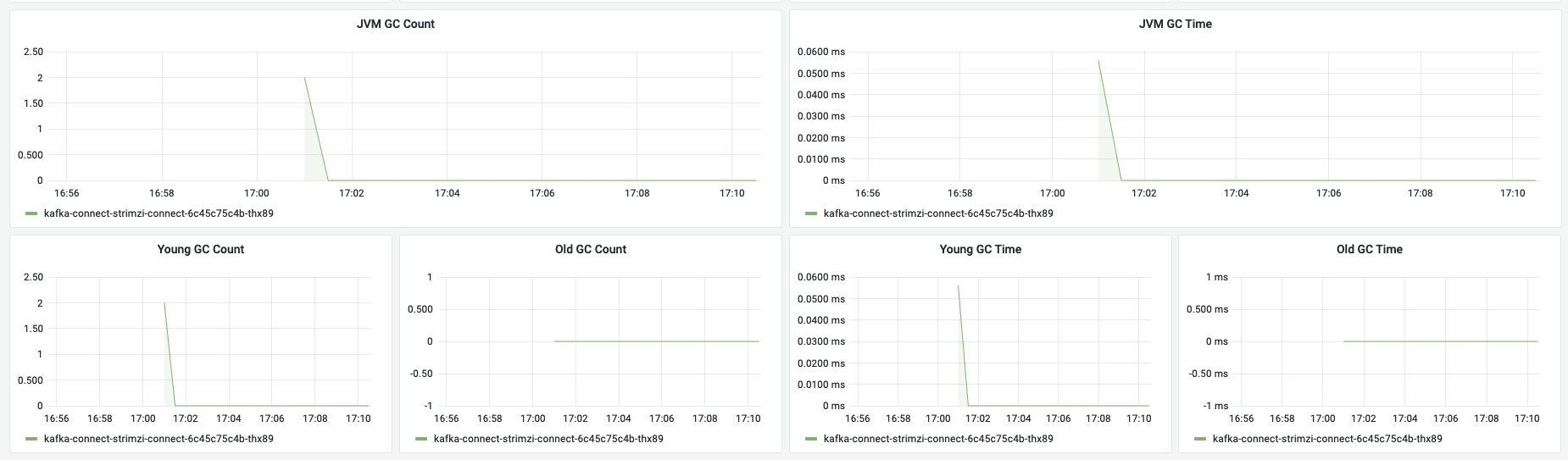
JVM
与Kafka监控看板中展示指标一致。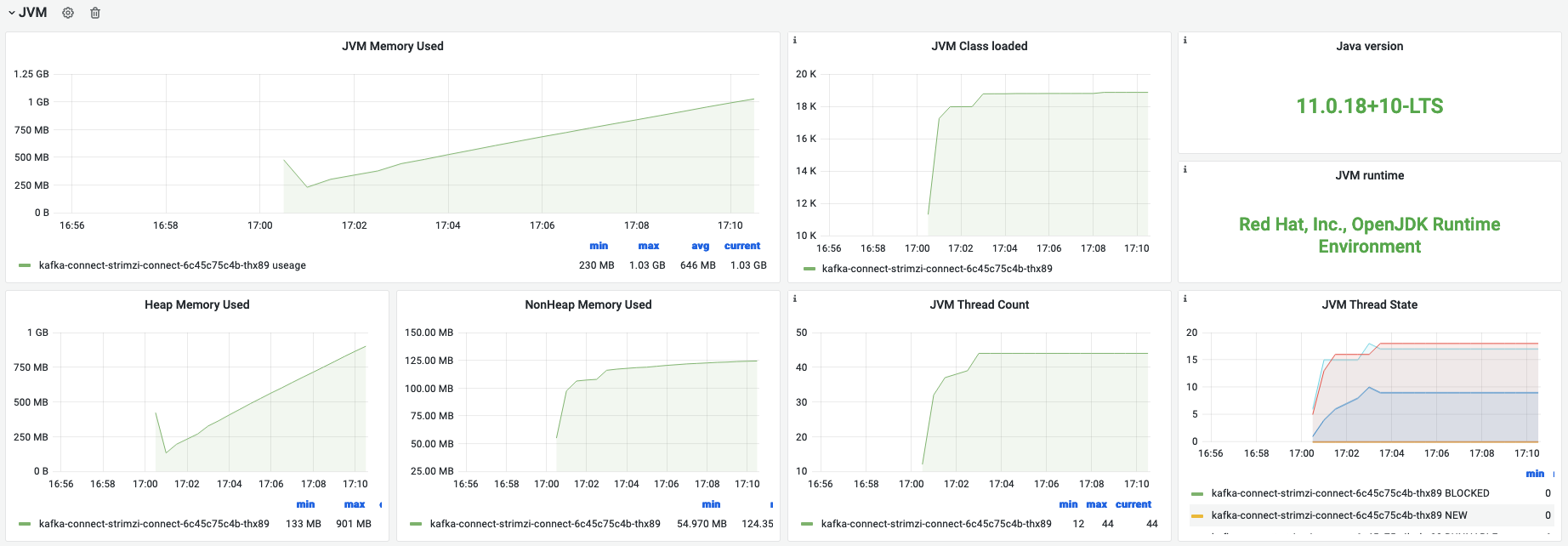
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| JVM Memory Used | JVM内存使用情况,指堆与非堆中的数据大小 | 总的内存使用大小,用户在容器运行内存范围内确认可用空间。 |
| JVM Class loaded | 加载的Class数量 | |
| Java version | java版本信息 | 不同java版本的特性需要额外关注 |
| JVM runtime | vendor与runtime | 确认是否为开源版本 |
| Heap Memory Used | 堆内存 | 该部分为jvm调优核心关注点 |
| NonHeap Memory Used | 非堆内存 | 大部分jvm程序的OOM若不是内存泄露,一般就与非堆使用有关。特别是以netty为底层通信框架的 |
| JVM Thread Count | 线程数 | |
| JVM Thread State | 不同线程状态的线程数 | 协助排查是否有过的线程挂起 |
| JVM GC Count | GC总数 | |
| JVM GC Time | GC总耗时 | |
| Young GC Count | young gc次数 | 一般情况下young gc用与确认是否过于频繁是否需要调大比例 |
| Old GC Count | old generation的GC次数 | 一般相对较少,如果GC频繁需要去人程序问题还是资源问题 |
| Young GC Time | young GC耗时情况 | |
| Old GC Time | old generation的GC耗时情况 | - |
10.Hive-hms监控看板
hms service info
hms service信息,包含实例个数,数据库信息,open connections和资源使用情况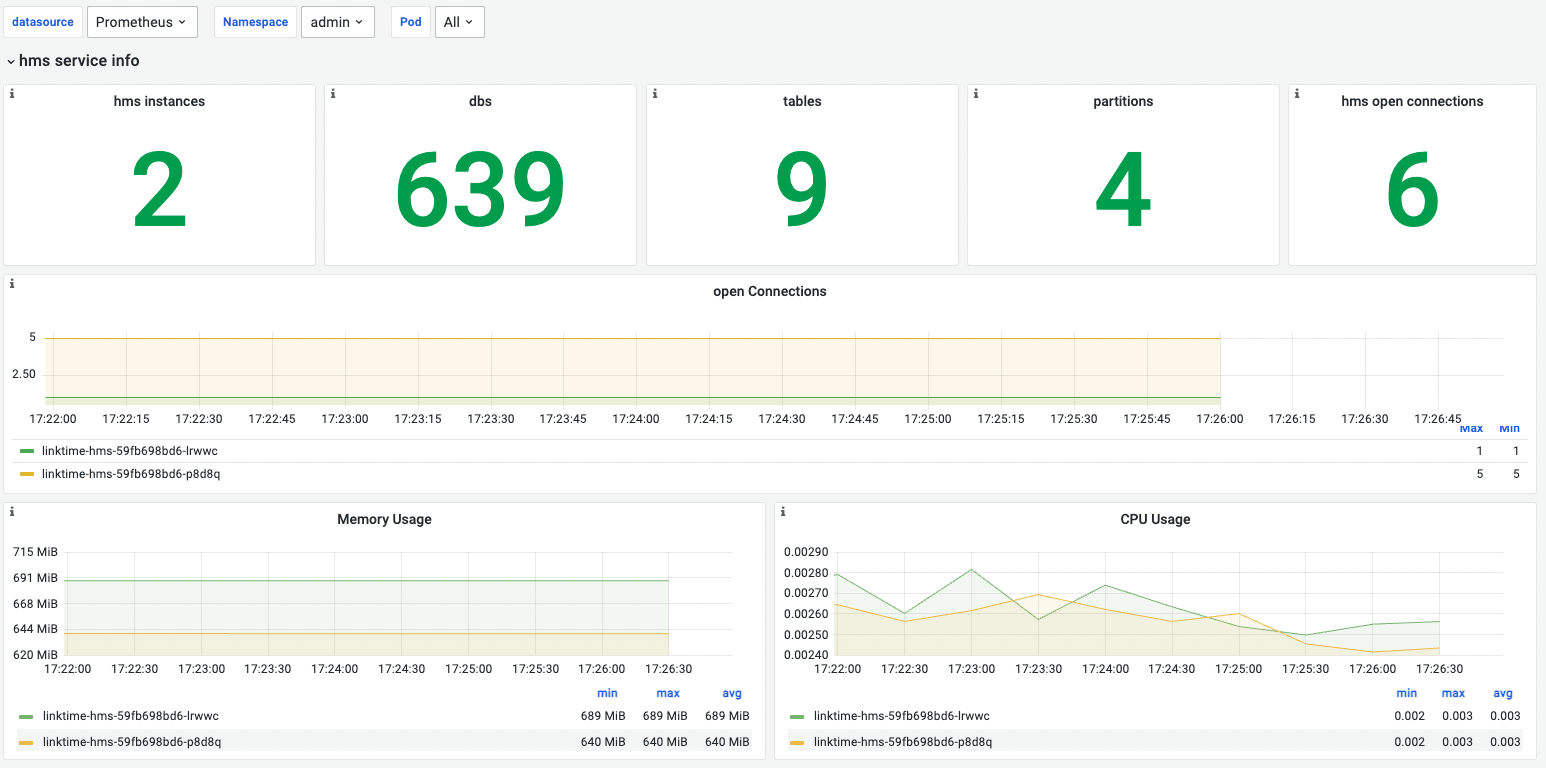
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| hms instances | hms当前实例个数 | 如果为0,表示hms当前不可用 |
| dbs | hms服务数据库的数量 | |
| tables | hms服务表的数量 | |
| partitions | hms服务分区的数量 | |
| current total open connections | hms当前所有实例打开的连接数总和 | |
| open connections | hms不同实例打开的连接数情况 | 用户通过在hms中执行hive脚本或者通过jdbc直接连接hms时,会创建一个连接;退出hive脚本或者jdbc connecttion.close()则会关闭连接 |
| Memory Usage | hms服务不同实例内存使用情况 | 当内存使用超过limit的90%即报警,否则会OOM |
| CPU Usage | hms服务不同实例CPU使用情况 | - |
hms databases info
hms数据库的情况,包含:数据库,表和分区的个数。

通过该看板,用于排查hms是否在做与数据库相关的操作:
total dbs,hms 数据库的变化情况;
total tables,hms 表的变化情况;
total partitions,hms 分区的变化情况;
hms datanucleus
hms数据库连接池情况。
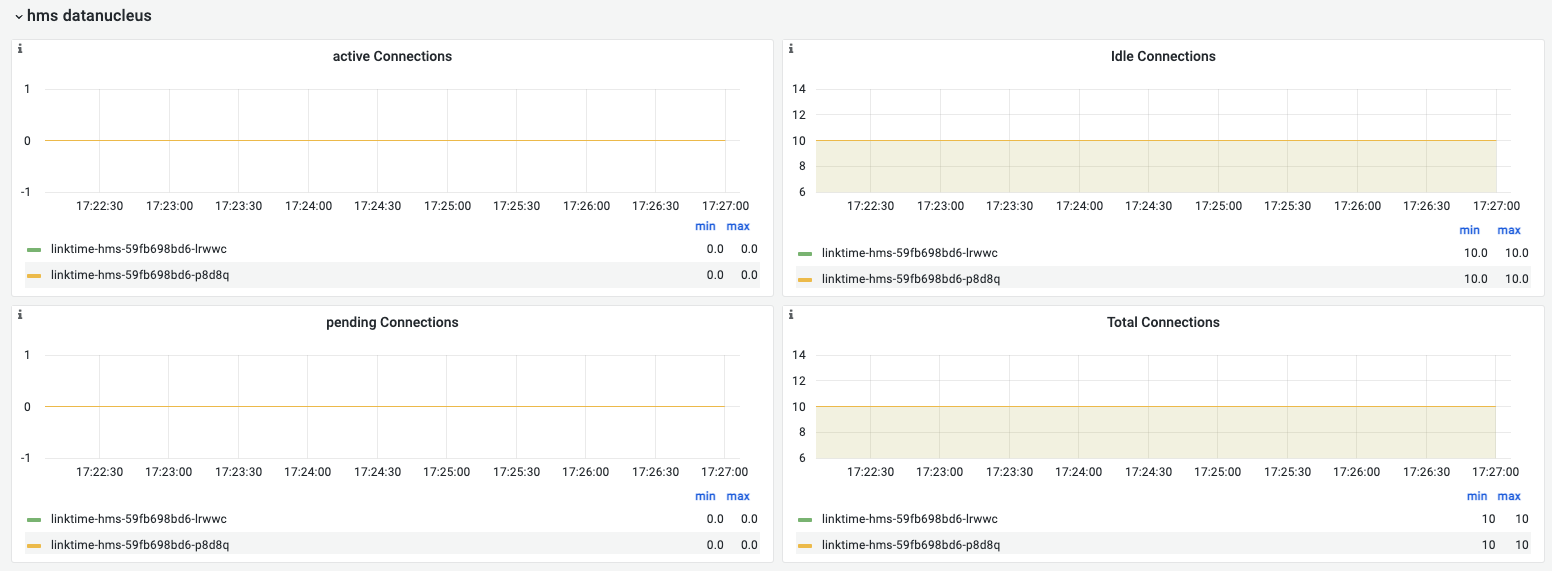
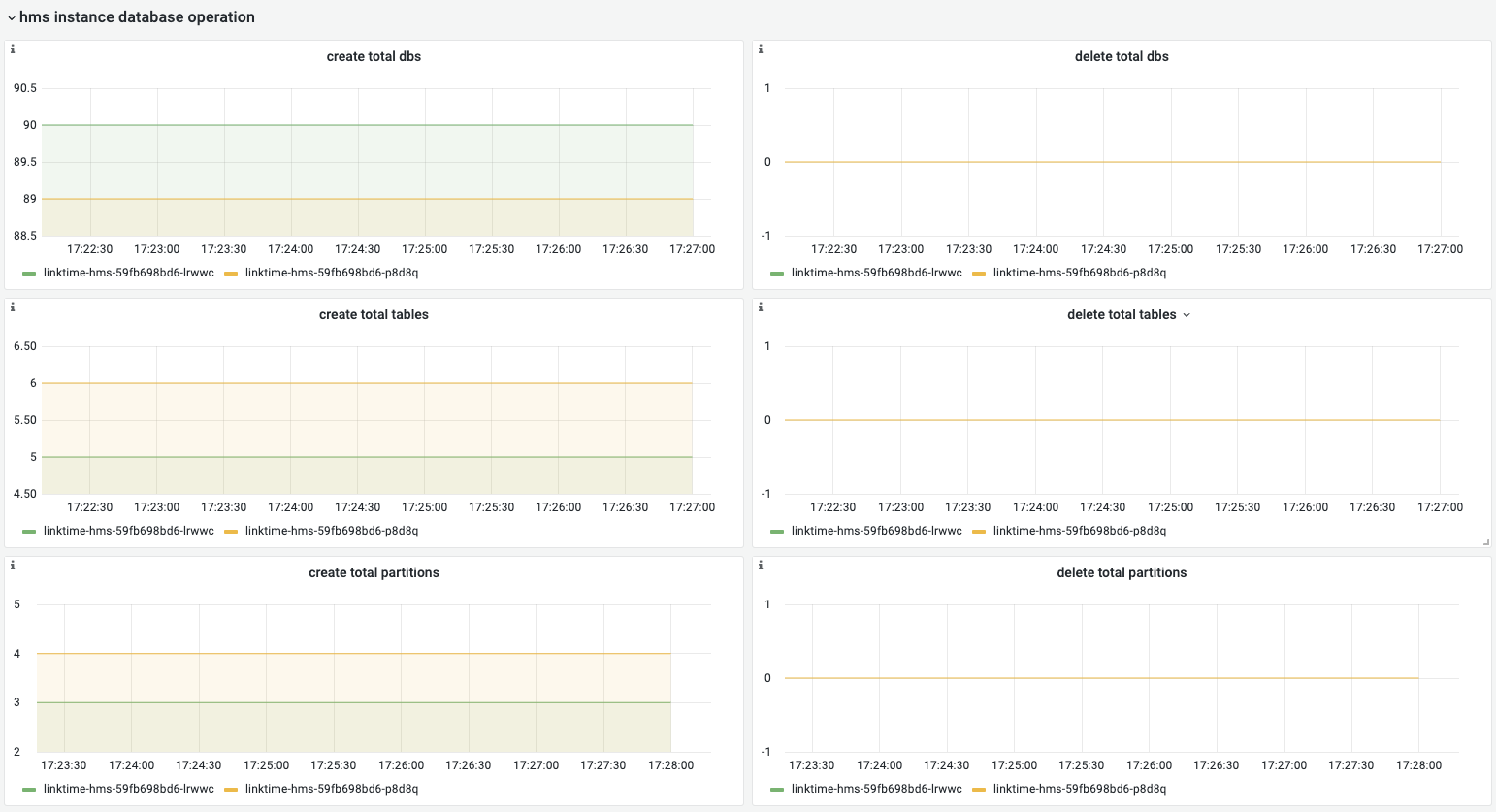
hms instance database operation
hms数据库变更操作,包含数据库/表/分区的创建和删除信息,通过该看板可以明确hms对数据库的具体操作。
container resource info
容器资源使用情况,包括内存使用量、CPU使用量、磁盘使用量变化趋势。

JVM
11.Hive-hs2监控看板
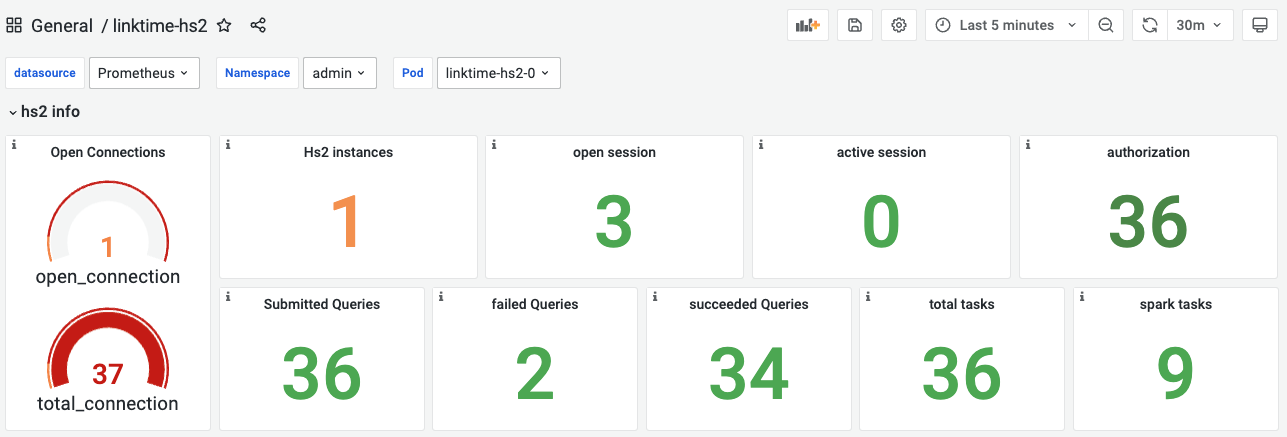
hs2 info
通过hs2信息模块,用户可快速识别hs2整体运行情况。
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| open_connectios | hs2当前正在使用的连接数 | 通过beeline连接hs2时,提示连接成功里,则会open 一个连接,当退出beeline时,则会关闭这个连接 |
| total_connections | hs2从服务启动到当前时间为止累计的连接数 | |
| hs2 instances | hs2实例个数 | hs2服务有多少个实例 |
| open session | hs2当前所有实例创建的session数 | 通过beeline与hs2建立连接时,会open 一个session,如果beeline不退出,达到空闲 session超时时间时,session会关闭;另外在beeline退出时,该session也会关闭 |
| active session | hs2当前所有实例正在使用的session数 | 与hs2建立连接后,在sql执行期间,该session是active状态,sql执行完成,session则是空闲状态 |
| authorization | hs2服务开启认证后,客户端认证次数 | hs2服务开启认证后,客户端认证次数,比如用户先kinit再使用beeline连接hs2时,就会做一次认证 |
| max_avg_open_session_time | 最大创建session时间 | 压测时,随着hs2的负载增加,open_session所用的时间越来越长,从而导致该值增加 |
| submitted queries | hs2服务提交查询数 | |
| failed queries | hs2服务失败查询数 | |
| succeeded queries | hs2服务成功查询数 | |
| total tasks | hs2服务task的总数 | |
| spark tasks | hs2服务spark task数 | - |
说明:
- 一个SQL可以拆分成很多种task,比如copyTask,DDLTask,SparkTask,explainTask等;total task是所有task的总和;
- hive执行引擎使用spark,当执行带有聚合,join等操作时,会生成spark task
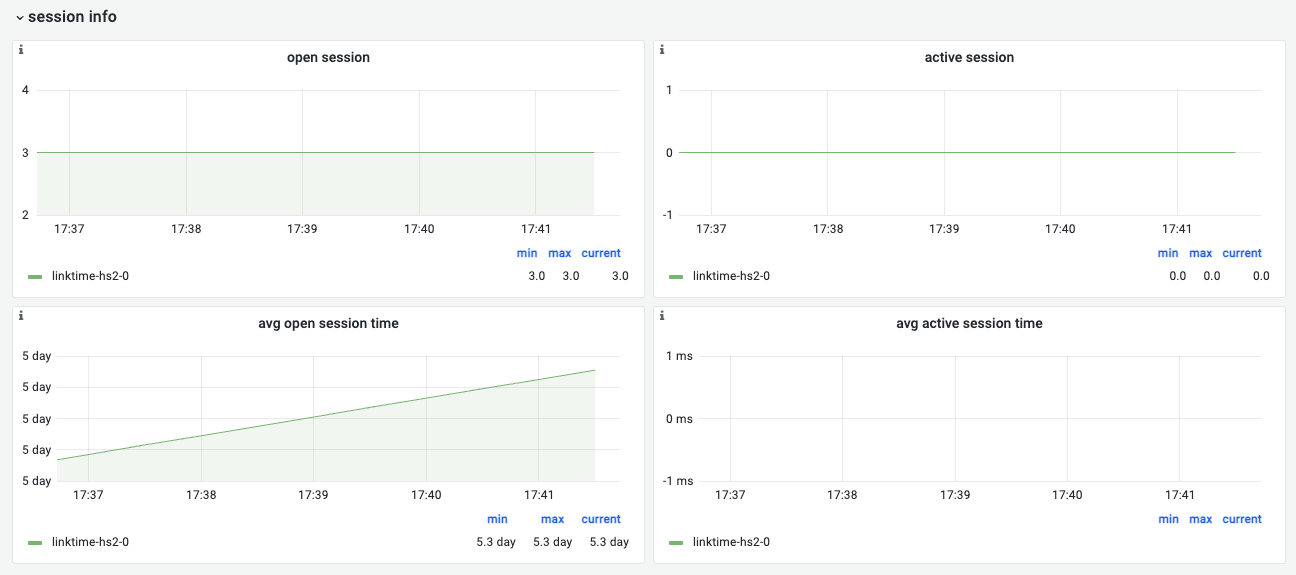
session info
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| open session | hs2各实例创建的session数 | 通过beeline与hs2建立连接时,会open 一个session,如果beeline不退出,达到空闲 session超时时间时,session会关闭;另外在beeline退出时,该session也会关闭 |
| active session | hs2各实例正在使用的session数 | 与hs2建立连接后,在sql执行期间,该session是active状态,sql执行完成,session则是空闲状态 |
| avg open session time | 创建session的平均时间 | 压测时,随着服务负载的增加,该值也会逐渐增加 |
| avg active session time | session 活跃的平均时间 | 可以辅助评估sql的执行时间,如果都是长时间任务,则值会增加,如果短时间任务多,则会下降 |
Queries
查询情况
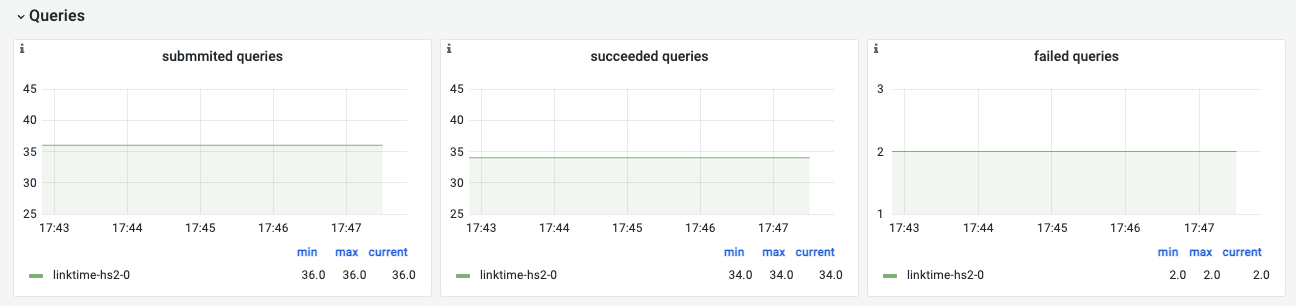
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| submitted queries | 提交的查询数量 | 提交的查询数量 |
| succeeded queries | 成功的查询数量 | 成功的查询数量 |
| failed queries | 失败的查询数量 | 如果在某一段时间内,失败查询数量不断上升,则需要关注是否是语法错误,作业资源设置不合理等,导致查询失败 |
Task
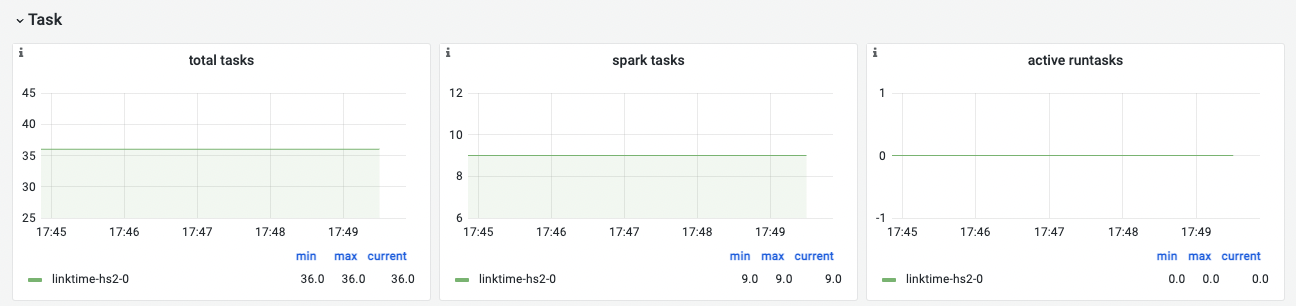
| total tasks | 总任务数 | |
|---|---|---|
| spark tasks | spark任务数 | |
| 名称 | 指标说明 | 场景说明 |
| active runtask | 正在运行的任务数 | 确认hive的并发任务数量 |
说明:hive执行引擎使用spark,当执行带有聚合,join等操作时,会生成spark task
Spark job
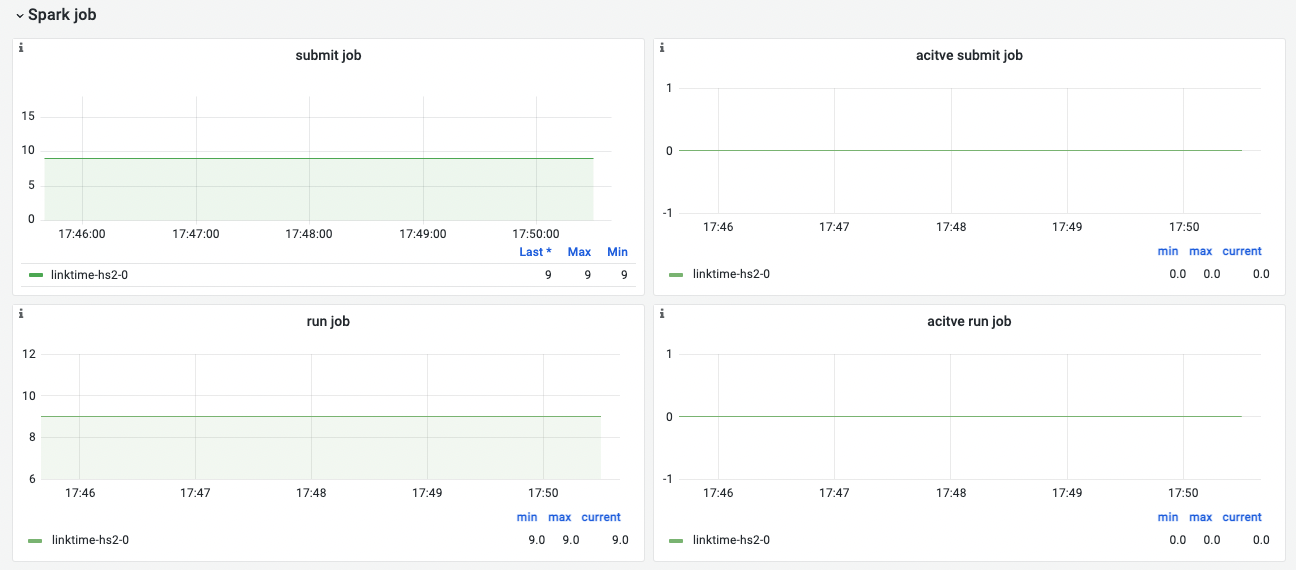
| 名称 | 指标说明 |
|---|---|
| submit job | 提交spark job总量 |
| active submit job | 正在提交spark job数量 |
| run job | 运行的spark job总量 |
| active run job | 正在运行的spark job数量 |
partition retrieving

| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| partition_retrieving | 检索分区总量 | 比如查询hive分区表中的数据,该值就会增加 |
| active partition_retrieving | 当前正在检索的分区数量 | - |
container resource info
容器资源使用情况,包括内存使用量、CPU使用量、磁盘使用量趋势。
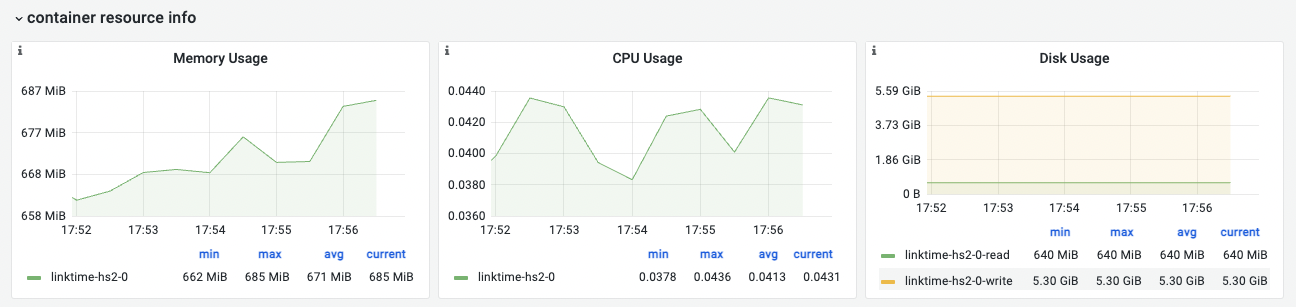
JVM
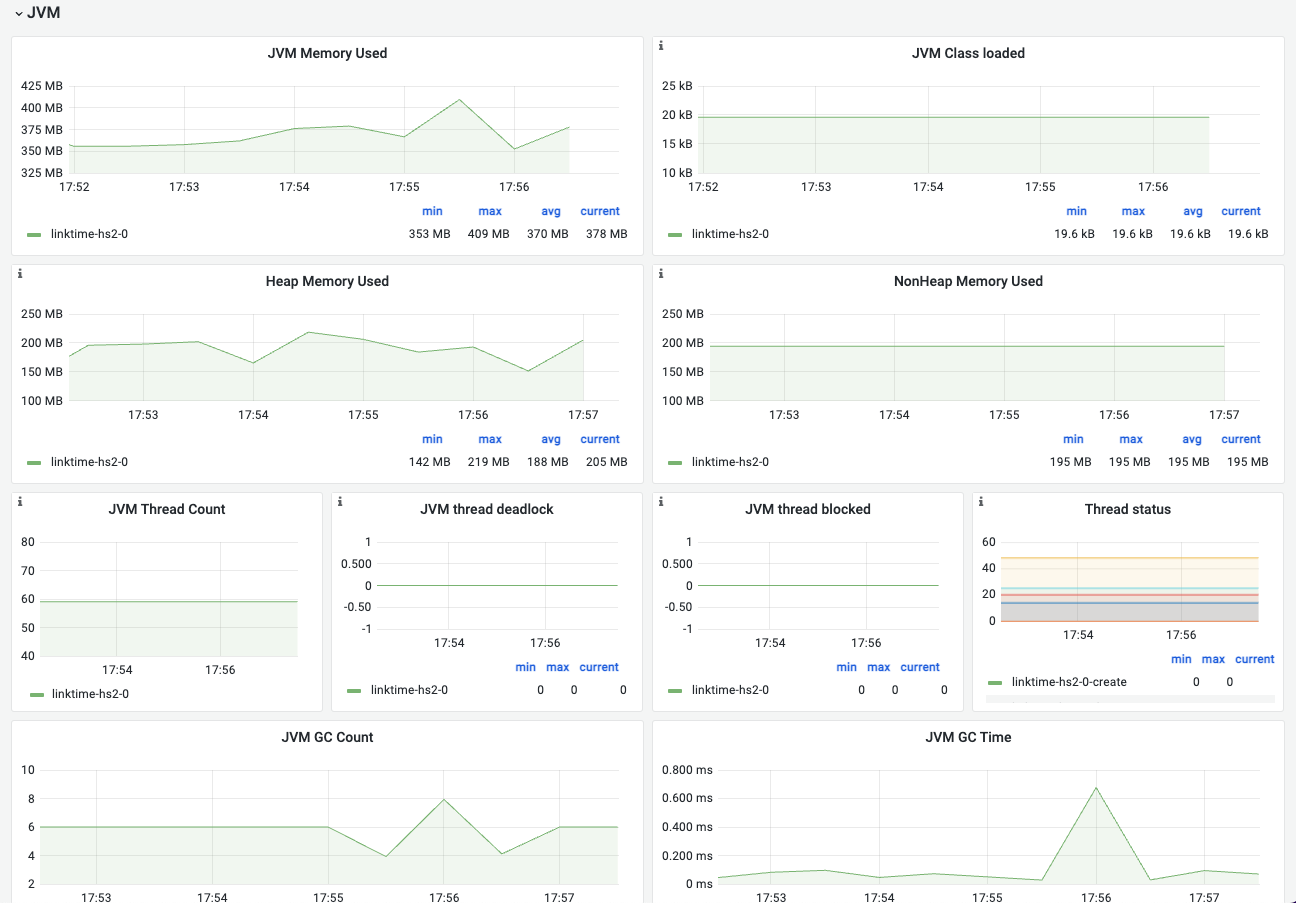
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| JVM Memory Used | JVM内存使用情况,指堆与非堆中的数据大小 | 总的内存使用大小,用户在容器运行内存范围内确认可用空间。 |
| JVM Class loaded | 加载的Class数量 | |
| Java version | java版本信息 | 不同java版本的特性需要额外关注 |
| JVM runtime | vendor与runtime | 确认是否为开源版本 |
| Heap Memory Used | 堆内存 | 该部分为jvm调优核心关注点 |
| NonHeap Memory Used | 非堆内存 | 大部分jvm程序的OOM若不是内存泄露,一般就与非堆使用有关。特别是以netty为底层通信框架的 |
| JVM Thread Count | 线程数 | |
| JVM Thread State | 不同线程状态的线程数 | 协助排查是否有过的线程挂起 |
| JVM GC Count | GC总数 | |
| JVM GC Time | GC总耗时 | |
| Young GC Count | young gc次数 | 一般情况下young gc用与确认是否过于频繁是否需要调大比例 |
| Old GC Count | old generation的GC次数 | 一般相对较少,如果GC频繁需要去人程序问题还是资源问题 |
| Young GC Time | young GC耗时情况 | |
| Old GC Time | old generation的GC耗时情况 | - |
11.HDFS监控看板
overview总览
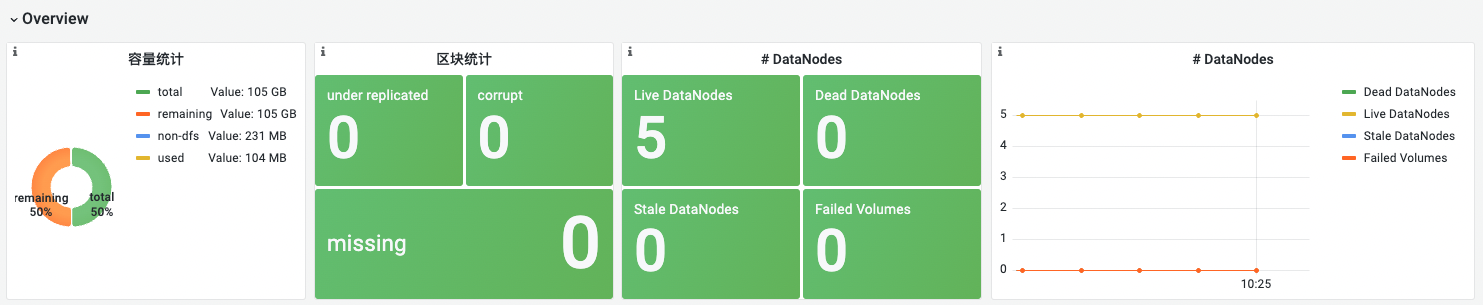
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| 容量统计 | 统计datanode的:总容量、已使用容量、剩余容量、非hdfs使用的容量 | 剩余容量不足需要及时告警 |
| 区块统计 | corrupt: HDFS中损坏的数据块数量。数据块可以由于各种原因而损坏,例如硬件故障或网络错误。通常namenode会进行修复,监控这个指标可以及时检测到数据损坏的情况,以便在必要时人工介入处理; under replicated: 表示已经被复制到少于规定副本数量的数据块数量。这个指标的值为0,表示所有的数据块都已经复制到足够的节点上; missing: HDFS中缺失的数据块数量。当节点失效或出现其他问题时,可能会导致数据块丢失。这些丢失的数据块需要被恢复以确保数据的可靠性和完整性 |
这三个指标正常情况应该均显示0。corrupt会自愈,而missing不会,missing需要告警,需要排查修复 |
| DataNodes | Live DataNodes : live 的 DN 数量应该和部署的数量一致,不相等需要排查; Stale DataNodes : 默认情况下NN没有接收到DN的心跳超过30s ,DN会被标记为 “stale” 状态; Dead DataNodes : DN 保持 “stale” 状态10分钟之后会标记为 “dead”; Failed Volumes : 故障卷的数量,dfs.datanode.failed.volumes.tolerated 默认是0,volumes 故障会导致DN下线 |
节点数量不符合预期都需要告警,都是比较严重的问题 |
NameNode - DFS
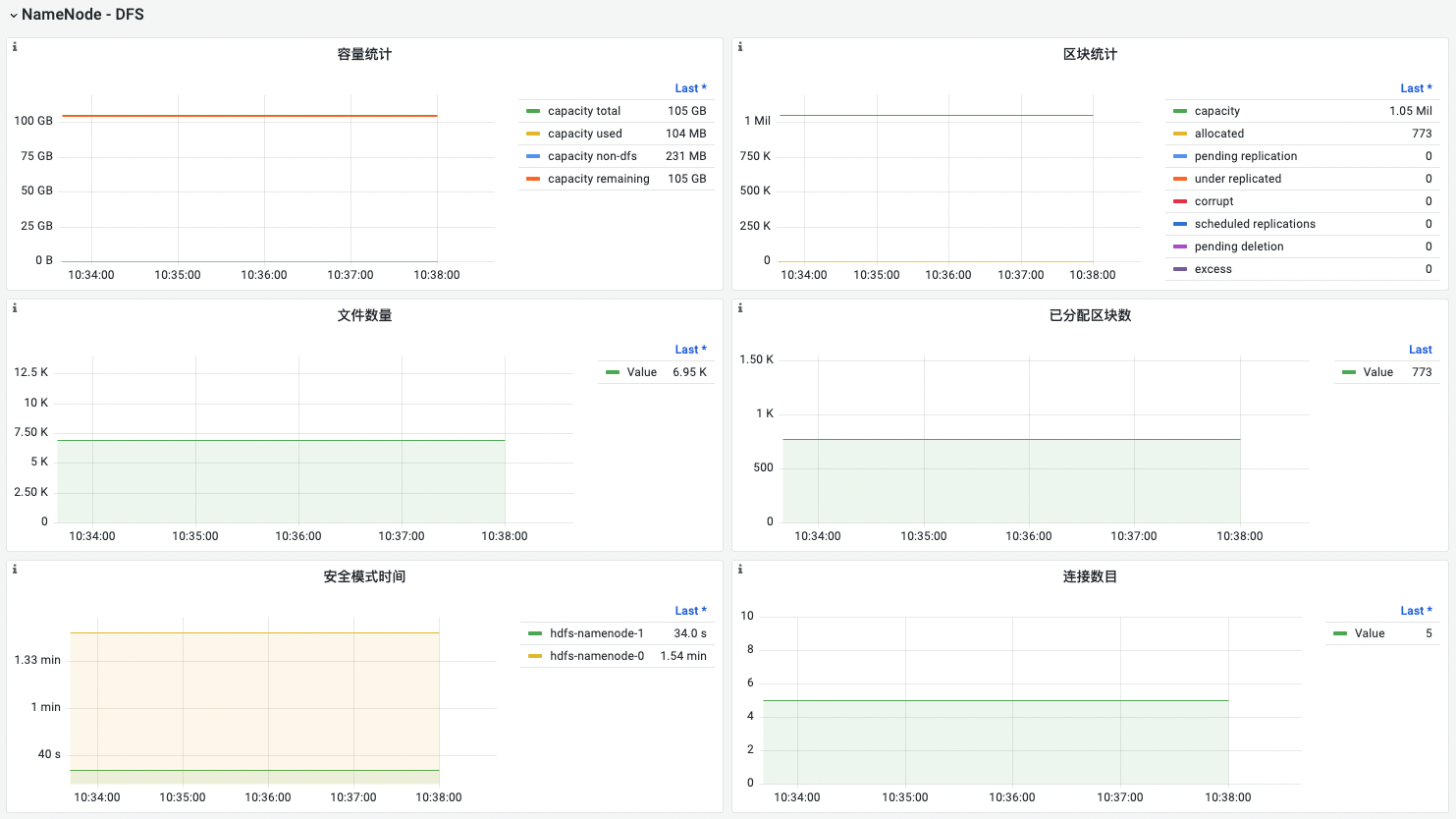
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| 名称 | 指标说明 | 场景说明 |
| 容量统计 | 统计datanode的:总容量已使用容量剩余容量非hdfs使用的容量 | 剩余容量不足需要及时告警 |
| 区块统计 | capacity: 可创建block数量; total: 表示HDFS中当前的数据块总数。通过监控这个指标,可以了解HDFS集群中存储的数据量,以及在数据量增加时是否需要扩展HDFS的容量; pending replication: 表示需要在数据节点之间复制的数据块数量,但尚未完成复制操作。这个指标的值应该始终保持在一个较低的水平,以确保数据可用性; under replicated: 表示已经被复制到少于规定副本数量的数据块数量。这个指标的值为0,表示所有的数据块都已经复制到足够的节点上; corrupt: HDFS中损坏的数据块数量。数据块可以由于各种原因而损坏,例如硬件故障或网络错误。通常namenode会进行修复,监控这个指标可以及时检测到数据损坏的情况,以便在必要时人工介入处理; scheduled replication: 已经在复制队列中的block数量; pending deletion: 表示待删除的数据块数量。这个指标的值为0,表示所有需要删除的数据块都已经被成功删除; excess: 多余的block数量。表示block的副本数量超出了设定值,通常不太影响,系统会自动删除多余block; missing: HDFS中缺失的数据块数量。当节点失效或出现其他问题时,可能会导致数据块丢失。这些丢失的数据块需要被恢复以确保数据的可靠性和完整性; postponed mis-replicated: 表示由于某些原因而需要延迟复制的数据块数量。在HDFS中,由于各种原因(例如网络故障或节点故障),数据块的复制可能需要被延迟 |
pending 持续增长或者过大,需要排除原因; corrupt 不为0,通常会自愈,需要排除原因,需要手动修复excess 不影响,不应该太多; under replicated: 需要排除原因,手动处理,保证数据的稳定可用; missing 需要告警,可能是data node 下线了或者其他原因,需要排查修复。 |
| 文件数量 | hdfs 上的文件和文件夹的数量 | 依据文件的数量合理配置NN的内存配置。 |
| 已分配区块数 | 区块统计 中的 total | |
| 安全模式时间 | 从FSNameSystem启动到退出安全模式的时间 | 如果安全模式时间过长,可能意味着系统中存在严重的数据块问题,需要进行修复或替换。此外,这个指标还可以帮助管理员优化系统的运行方式,以减少安全模式的时间并提高文件系统的可用性。 |
| 连接数目 | 客户端连接数 | 连接数过多,或者持续增加会影响读写,需排查 |
说明:
- 在HDFS中,任何Block、文件或者目录在内存中均以对象的形式存储,每个对象约占150Byte,如果一个文件用一个block, 那就是300Byte, 副本3,差不多就是1k
- 安全模式是 Hadoop HDFS 中的一种保护模式,它在 NameNode 启动或重启期间自动激活。当 NameNode 处于安全模式时,文件系统处于只读状态,无法写入或修改数据块,但可以读取数据。此时,NameNode 会检查所有数据块的完整性,以确保它们在存储期间没有出现任何问题。在正常情况下,一旦 NameNode 完成了所有数据块的检查,它就会自动退出安全模式并将文件系统设置为可写状态。然而,如果有数据块出现问题,NameNode 将继续保持在安全模式下,并等待管理员对问题进行修复。
DataNode - DFS
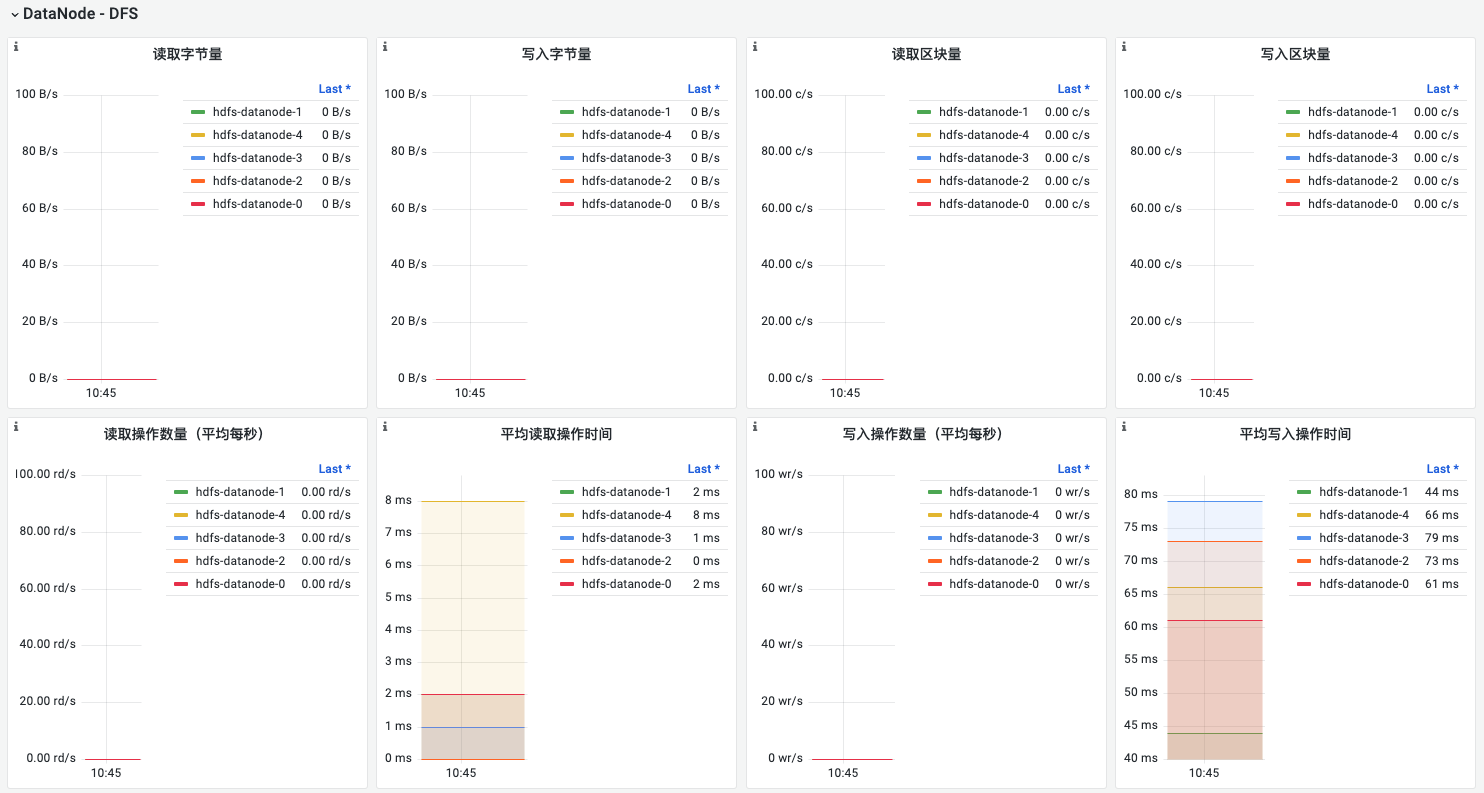
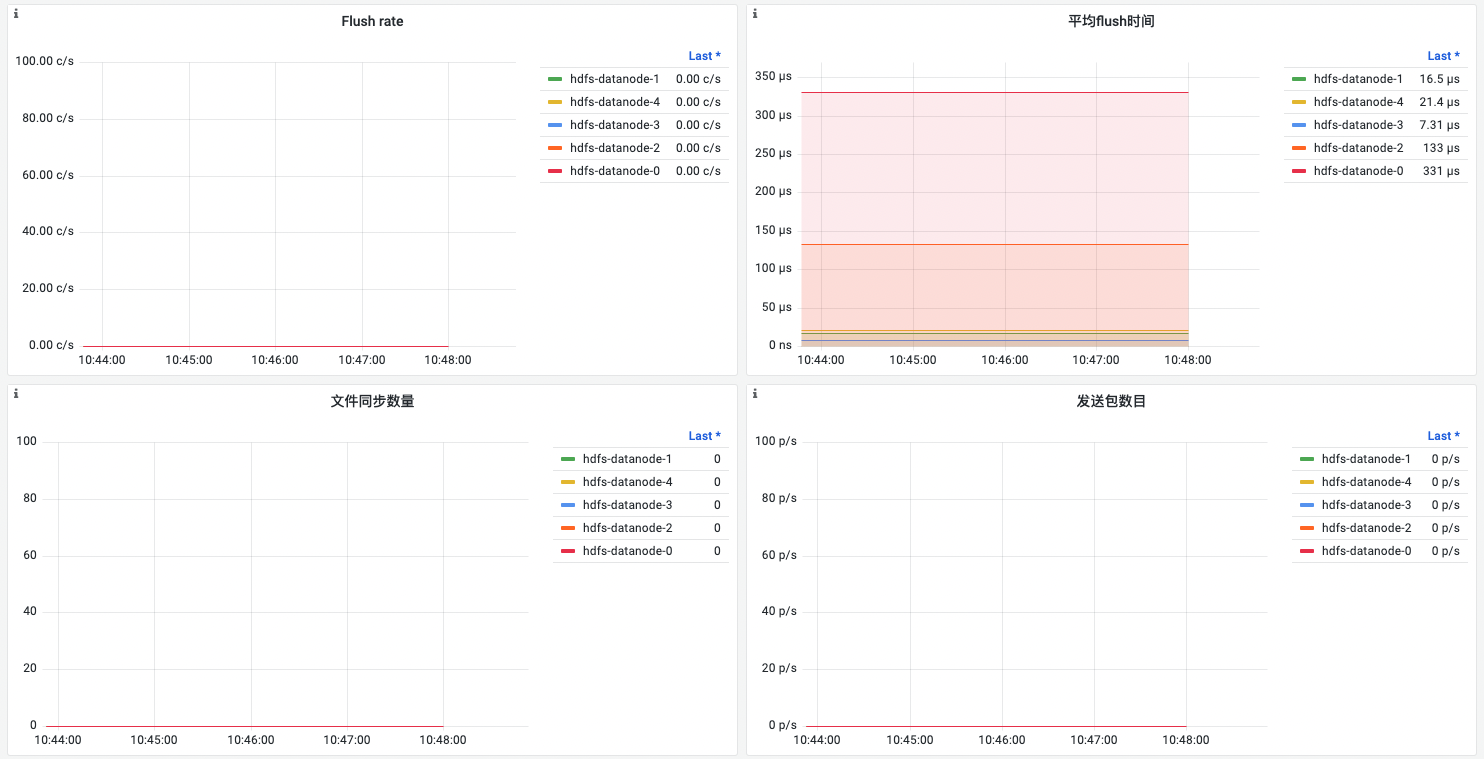
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| 读取字节量 | 各datanode平均每秒读取的字节数 | 借助异常高流量,协助定位问题 |
| 写入字节量 | 各datanode平均每秒写入的字节数 | |
| 读取区块量 | 各datanode平均每秒读取的区块数(block) | |
| 写入区块量 | 各datanode平均每秒写入的区块数(block) | |
| 读取操作数量(平均每秒) | 各datanode每秒的读操作数 | 耗时增加需要排查网络或者磁盘问题 |
| 平均读取操作时间 | 各datanode读操作的平均耗时 | |
| 写入操作数量(平均每秒) | 各datanode每秒的读操作数 | 耗时增加需要排查网络或者磁盘问题 |
| 平均写入操作时间 | 各datanode写操作的平均耗时 | |
| Flush rate | 各datanode 每秒平均flush 操作的次数 | Flush 操作会导致磁盘的额外 I/O 操作,频繁flush可能会影响应用程序的性能 |
| 平均flush时间 | 各datanode flush 操作的平均耗时 | flush 时间越少越好, 较长的时间说明写磁盘性能较差 |
| 文件同步数量 | 各datanode 当前正在进行的文件同步(file sync)操作的数量 | 指标的值很高,说明数据节点当前正在进行大量的文件同步操作,可能是由于写入请求过于频繁或节点磁盘性能不足导致。如果该指标的值一直很高,可能会影响数据节点的性能和稳定性。因此,管理员需要监控该指标并根据需要采取相应的措施,如优化写入策略、扩展节点硬件等来解决性能问题。 |
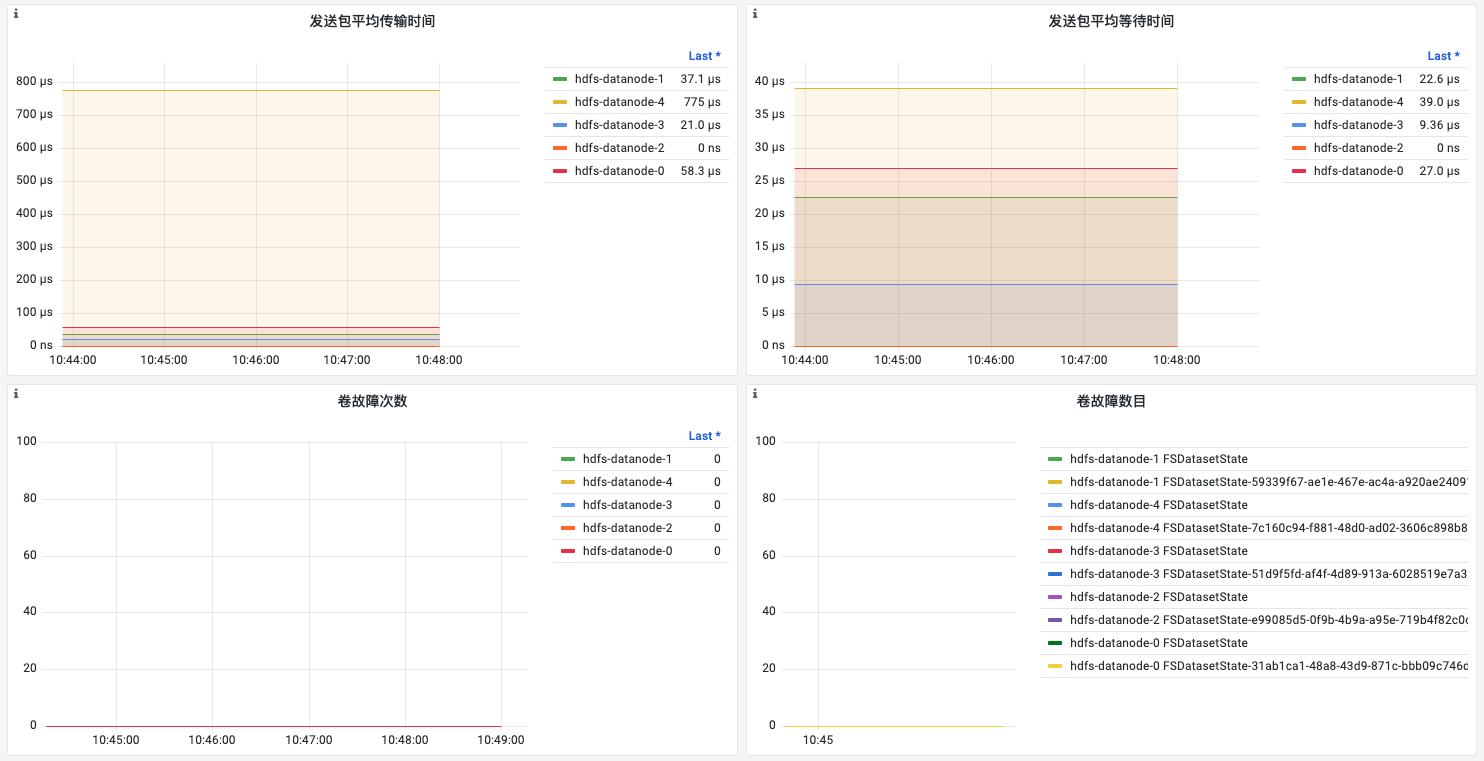
| 发送包数目 | 各datanode每秒发送包的数量 | |
| 发送包平均传输时间 | 各datanode发送包的平均耗时 | 耗时持续显著增大(通常是毫秒级),需告警排查 |
| 卷故障次数 | 磁盘卷损坏发生的次数 | 当磁盘损坏时,数据节点将无法访问存储在该磁盘上的数据块,可能会导致数据丢失和HDFS集群的不可用性。 需告警处理 |
| 卷故障数目 | 磁盘卷损坏的数量 | 当磁盘损坏时,数据节点将无法访问存储在该磁盘上的数据块,可能会导致数据丢失和HDFS集群的不可用性。 需告警处理 |
说明:
- 文件同步是指将内存中缓冲区中的数据立即写入到磁盘中,以确保数据的持久性和一致性。当数据节点接收到写请求时,它将数据写入到本地文件系统缓冲区中,并返回成功响应。此时,数据仍然存储在本地缓冲区中,如果节点在此时宕机,数据将会丢失。因此,为了保证数据的持久性,数据节点会将缓冲区中的数据同步到磁盘中。
NameNode/DataNode-JVM
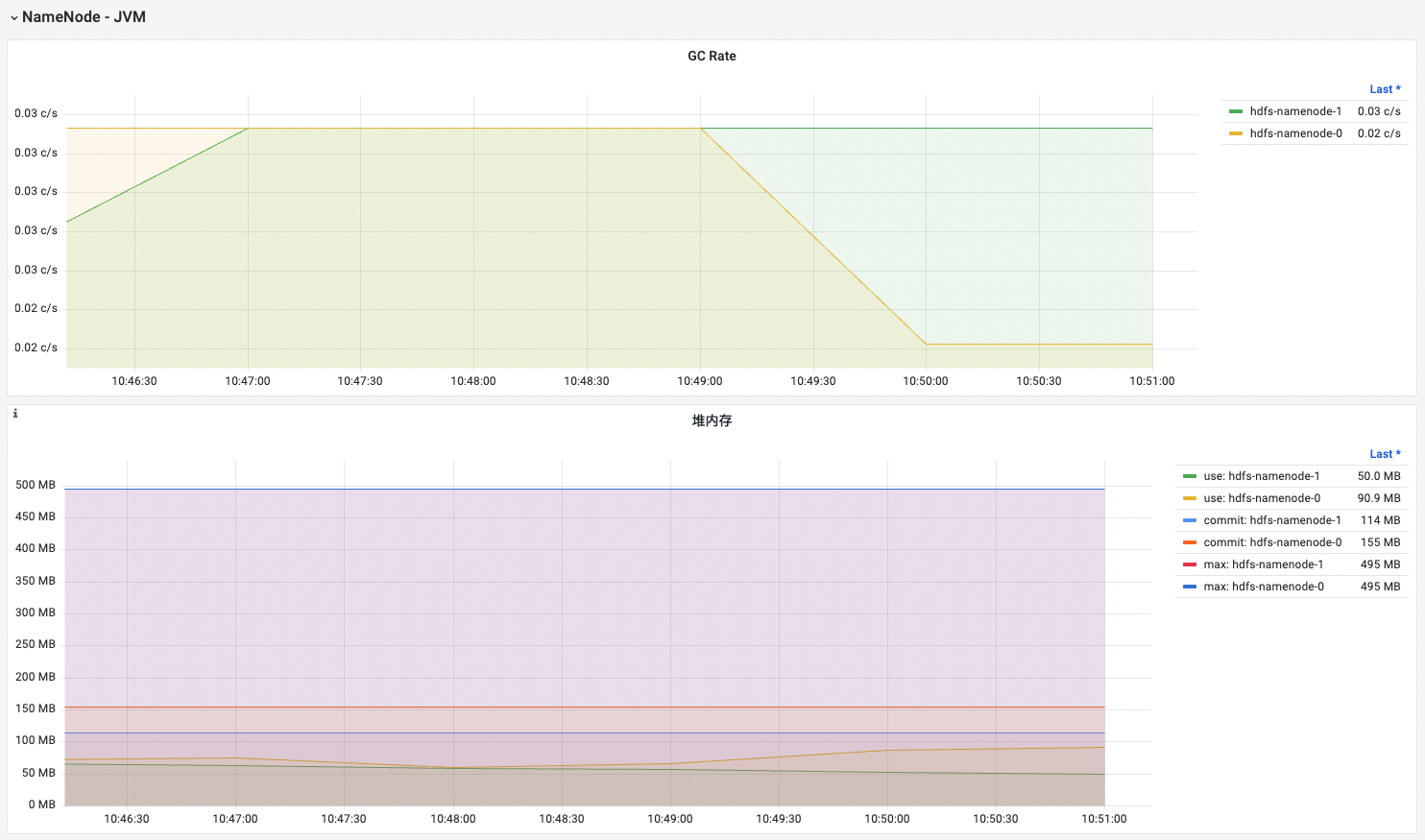
| 名称 | 指标说明 | 场景说明 |
|---|---|---|
| GC Rate | 平均每秒执行GC的次数 | 频繁的垃圾回收可能会导致应用程序不稳定,需要排查处理 |
| 堆内存 | 堆内存的使用情况(used/committed/max) | used 持续接近commited(或者max), 内存紧张,影响应用稳定性,可能存在内存泄漏或者资源不足需扩容 |
| 非堆内存 | 非堆内存的使用情况(used/committed/max) | used 持续接近commited(或者max), 内存紧张,影响应用稳定性,可能存在内存泄漏或者资源不足需扩容 |
| 线程数 | WAITING: 正在等待某些事件的线程数。如果这个数字持续较高,说明有一些操作阻塞了NameNode节点的执行,导致请求被延迟; RUNABLE: 运行的线程数。当NameNode节点有多个请求需要处理时,这个数字应该较高,如果这个数字一直很低,说明NameNode节点可能存在瓶颈或者过度负载; TIMED_RUNNING: 正在执行有限时间操作的线程数。这些有限时间的操作可能包括等待锁或等待IO操作完成。如果这个数字一直很高,说明NameNode节点可能存在一些瓶颈或者性能问题; BLOCKED: 被阻塞的线程数。这些线程可能因为等待锁或等待其他线程完成某些操作而被阻塞。如果这个数字一直很高,说明NameNode节点可能存在锁竞争问题或者性能瓶颈。 |
WAITING/BLOCKED/TIMED_RUNNING 持续高,会影响系统的可用性,说明存在性能问题,通常需要排查hdfs网络和读写 |
| 日志数(每分钟) | 不同级别日志每分钟产生的数量 | 需要特别关注error/fatal 级别的日志,需要跟进处理说明此类日志产生的原因 |
说明:
- 内存使用情况
- “used”表示Java虚拟机当前正在使用的内存大小,以字节为单位。
- “committed”表示已经分配给Java虚拟机的内存大小,保证可供使用。随着内存被释放回系统或分配给其他用途,这个值可能会随时间变化。不过,它始终大于等于当前正在使用的内存大小。
- “max”表示可用于内存管理的最大内存大小,但其值可能未定义。可用内存的最大大小也可能随时间变化,但当前正在使用和已分配的内存大小始终在这个限制范围内。
- 线程数
- WAITING(等待)状态:当一个线程正在等待另一个线程执行某个操作时,它就处于等待状态。在等待状态下,线程不会执行任何操作,直到被唤醒或中断。例如,当一个线程调用了 Object.wait() 方法时,它就会进入等待状态。
- RUNNING(运行)状态:当一个线程正在执行代码时,它就处于运行状态。在运行状态下,线程会执行其任务,直到任务完成或被阻塞。
- TIMED_RUNNING(有限时间运行)状态:当一个线程正在以有限时间运行的方式执行代码时,它就处于有限时间运行状态。在这种状态下,线程会执行其任务,但会在一定时间内停止。例如,当一个线程调用了 Thread.sleep() 方法时,它就会进入有限时间运行状态。
- TERMINATED(终止)状态:当一个线程执行完其任务后,或者因某种原因而被中断或异常终止时,它就处于终止状态。在终止状态下,线程不再执行任何操作。
12.Zookeeper监控看板
zookeeper作为一个distributed coordination在大数据的生态的分布式架构中有着极为重要的地位,如:kafka、hdfs、flink都会用zk来同步元数据信息完成高可用架构。
overview总览
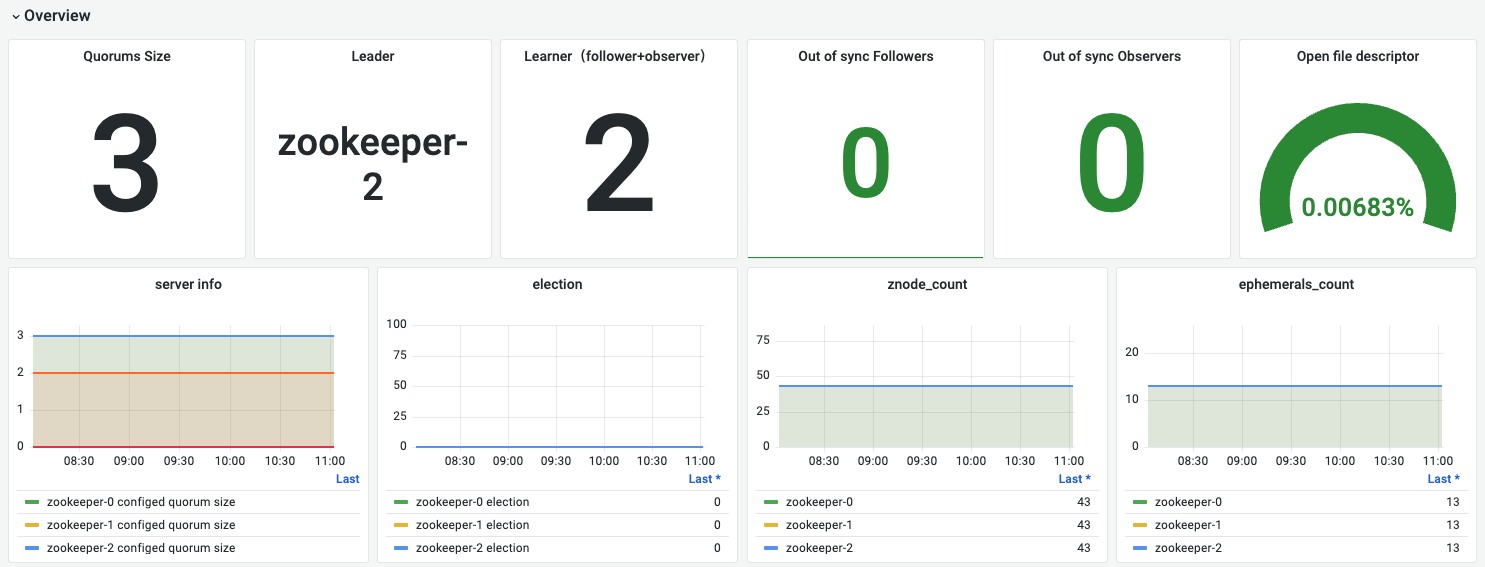
以上是一个3节点的zk cluster:1 leader + 2 follower + 0 observer。ps: 目前在我们的实际使用中比较少用到observer这个角色,适用于 “读” 远大于 “写” 的场景。
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| Quorums Size | zookeeper集群可参与election的server数量:leader + follower | 用来确认zk cluster的leader + follower在部署时的指定数量是否正确, |
| Leader | 处于Leader角色的zk server | 确定leader便于后续运维操作,比如需要确认是zk是否存在网络分区导致脑裂的情况。如果有两条leader可能是出现了脑裂 |
| Learner | follower + observer的数量 | 我们当前使用是observer一般为0。这种情况下Learner num = in sync follower num,比如上面挂掉一个follower的时候,learner是1就是说明只有一个follower处于同步状态 |
| Out of Sync followers | 掉线的followers | 是否有server异常,不为0就是有server出问题了 |
| Out of Sync observer | 掉线的observer | |
| open file descriptor | 开启文件描述符比例 | 若集群值设置比较小比如65535,有用超的风险 |
| server info | server | zk全部server节点的信息汇报,如leader情况、各个server的quorum配置情况,主要是确认server role |
| election | leader选举请求情况 | 在发生election一般伴随有server异常、重启等情况。 |
| znode_count | 全部数据node数量 | 确认zk承载数据规模,如果增长迅速需要考虑扩容zk |
| ephemerals_count | 临时数据node数量 | 确认临时数据节点数量,如果太多可能伴随着watch session增大,zk server压力也会比较大。要考虑控制在合理数量,社区做的告警建议是100以下,我们需要根据实际资源情况调整这个阈值。 |
Network
请求延时情况看板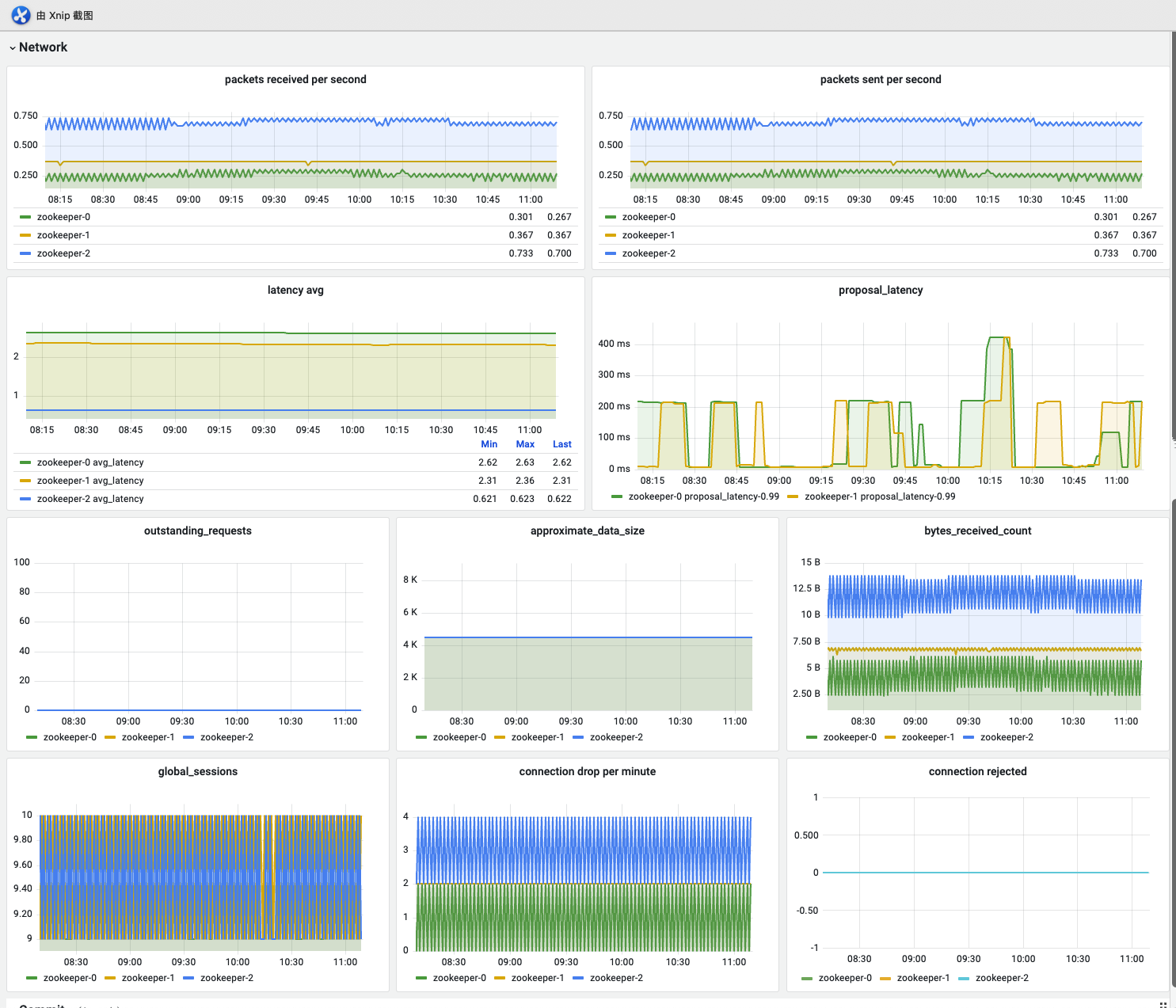
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| packets received per second | 每秒收包数量 | |
| packets sent per second | 每秒发包数量 | |
| latency avg | 所有请求平均时延 | 如果时延过高一定要引起关注,可能存在大量数据的写入zk处理不过来了 |
| proposal latency | leader发起事务处理流程的起点,Proposal 提议会发给所有 Follower 来发起一次集群内的事务投票. | 如果值非常大一般是伴随有election动作,follower都声明自己是leader后要等待其他follower放弃leader角色。如果没有伴随election,可能是zk server有问题需要注意。 zk所有会改变server状态的事务都会创建Proposal后续都伴随有commit request。 |
| outstanding_requests | 待处理的请求 | 与zk的proposal、commit机制相关,请求会排队处理。如果积压过多要进一步查看资源、网络的表现情况 |
| approximate_data_size | 近似数据大小 | zk承载元数据,在我们的使用场景中一般不会有太多数据需要存储。 |
| bytes_received_count | 接收数据大小 | zk应该是一个读多写少的系统,如果写入的流量过大,需要特别关注 |
| global_sessions | 全局存活的会话链接数 | 一般不能太高,社区建议是200以下 |
| connection drop per minute | 每分钟断开连接数,基本是超时连接 | 丢的连接太多说明客户端会有很多闲杂请求,需要合理设置客户端的连接池 |
| connection rejected | 拒绝连接数,一般是配置了监听规则或开启了认证规则后拒绝的请求 | 不断地有请求被拒绝,需要查看服务端、客户端的认证信息是否匹配。服务端的端口监听规则是否正常设置成了只有localhost才能访问 |
commit
事务处理提交情况,反应数据写入更新、zk leader选举的情况
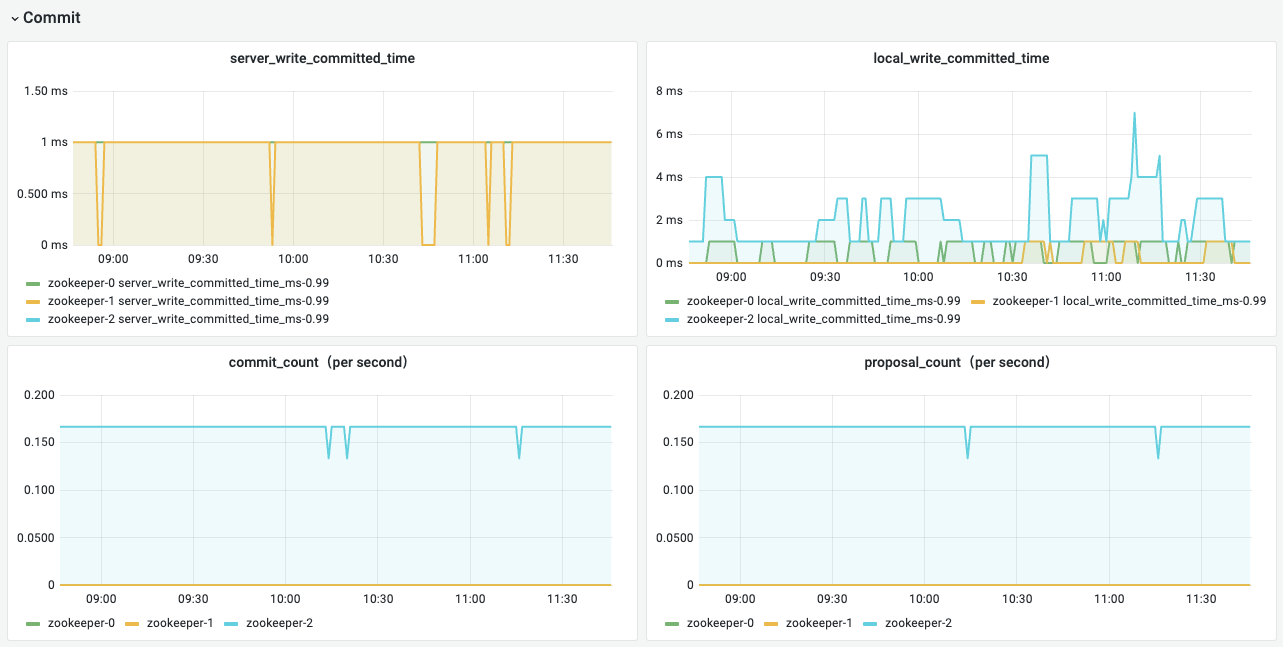
| 名称 | 指标含义 | 场景举例 |
|---|---|---|
| local_write_committed_time | 本server commit处理时间 | |
| server_write_committed_time | 由leader server发起的commit处理时间 | |
| commit_count(per second) | 每秒平均commit请求量 | 事务提交量一般与proposal能对应上,如果不对应需要注意是否有proposal创建但是没有commit处理生成,可能伴随有客户端的请求失败 |
| proposal_count(per second) | proposal请求量,又leader发起的每个proposal都会触发后续的commit process | 与上一个commit_count配合使用 |