
疫情大屏-精选数据集项目
项目设计
总体流程

数据血缘关系

原始业务数据(精选公共数据源)
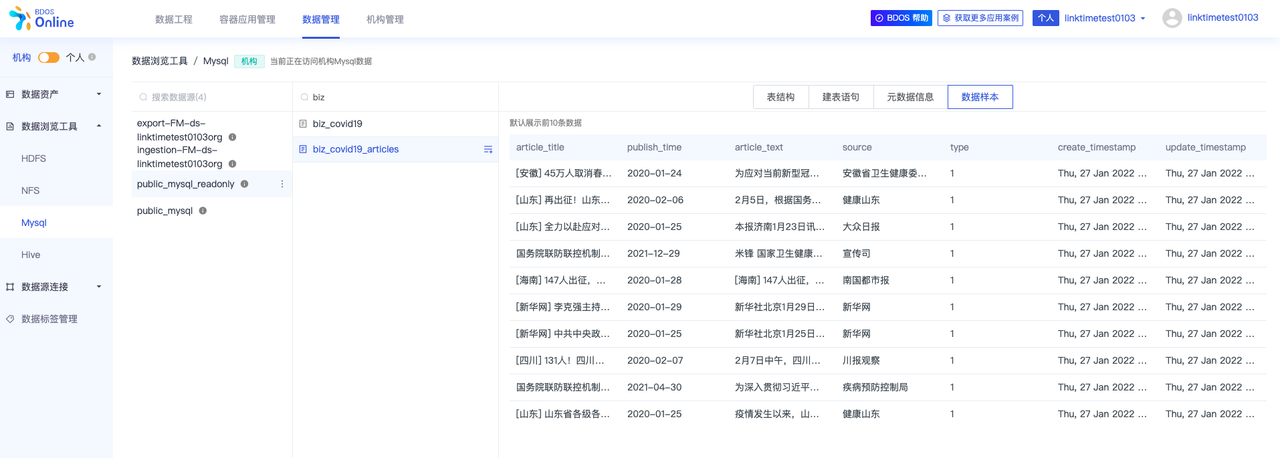
biz_covid19
数据表说明
- 每个城市,每天确诊、治愈,死亡人数情况统计表。
- 以及总共累计确诊、治愈,死亡人数统计表
数据字典
| 字段名称 | 字段中文释义 | 字段类型 | 数据样例 |
|---|---|---|---|
| index | 记录编号 | BIGINT | 1 |
| data_day | 记录日期 | TEXT | 2019-12-01 |
| name | 省 | TEXT | 湖北 |
| chirdren_name | 市 | TEXT | 武汉市 |
| total_confirm | 总确诊人数 | BIGINT | 10 |
| total_heal | 总治愈人数 | BIGINT | 1 |
| total_dead | 总死亡人数 | BIGINT | 1 |
| today_confirm | 当日确诊人数 | DOUBLE | 1 |
| today_dead | 当日死亡人数 | DOUBLE | 1 |
| today_heal | 当日治愈人数 | DOUBLE | 1 |
| today_newConfirm | 当日新增确诊人数 | DOUBLE | 2 |
biz_cov19_articles
数据表说明
- 疫情新闻摘要
数据字典
| 字段名称 | 字段中文释义 | 字段类型 | 数据样例 |
|---|---|---|---|
| article_title | 新闻标题 | VARCHART | [安徽] 45万人取消春节假期 安徽卫健系统全力应对疫情 |
| publish_time | 新闻发布时间 | VARCHART | 2020-01-24 |
| article_text | 新闻摘要 | TEXT | 为应对当前新型冠状病毒感染的肺炎疫情,1月23日深夜,省卫生健康委发出《动员令》,宣布全省卫生健康系统取消2020年春节放假。各市、县卫生健康委、医疗卫生机构以及疾控中心在春节期间将照常上班。 省卫健委相关负责人表示,此举是为确保春节期间全省卫生健康系统疫情防控措施得到有效落实,让全省群众度过一个安定祥和的新春佳节。 目前,省立医院感染病院、安医大一附院、安医大二附院、蚌医一附院、皖医弋矶山医院、安医大附属巢湖医院等省级定点医院和安中医一附院、省第二人民医院、省胸科医院、安医大附属阜阳医院、省儿童医院等省级定点后备医院均已取消春节放假,正常上班。 |
| source | 新闻发布网站 | VARCHART | 安徽省卫生健康委员会网站 |
| create_timestamp | 记录创建时间 | DATETIME | 2022-01-27 08:26:26 |
| update_timestamp | 记录修改时间 | DATETIME | 2022-01-27 08:26:26 |
数据处理过程数据
part0 准备工作
1.切换角色:为机构admin(或者机构devop)
切换为机构角色后: 1. 可以创建机构项目 2. 可以多个人合作协作进行编辑
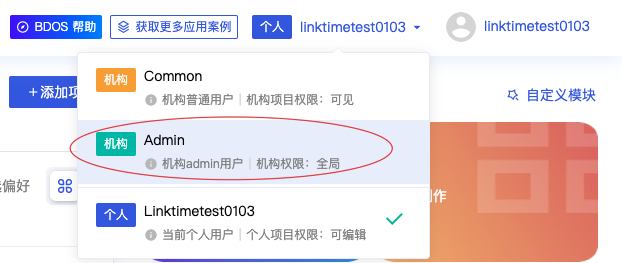
2.查询自己的机构信息
每一个机构都有自己独立的一整套信息
- 点击机构管理模块
- 点击机构资源,可以看到机构名称(后面会使用到)
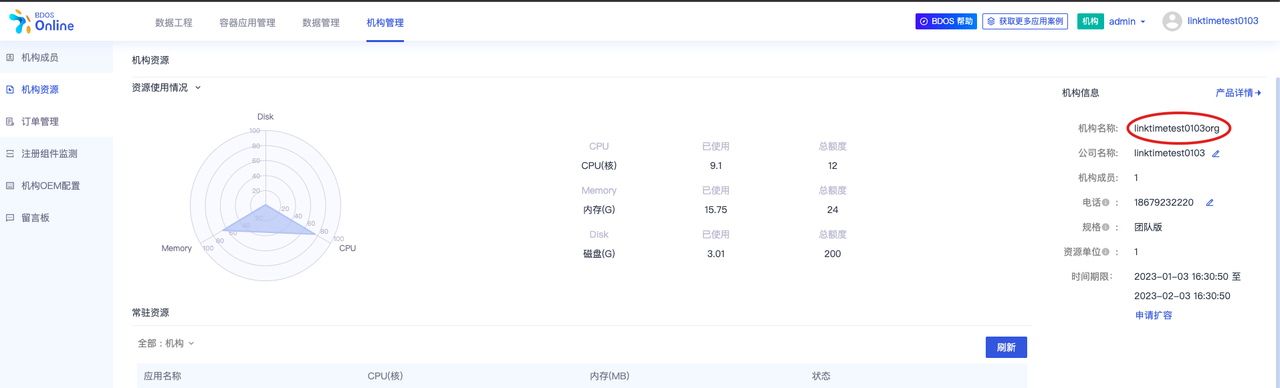
- 或者点击右上角用户头像
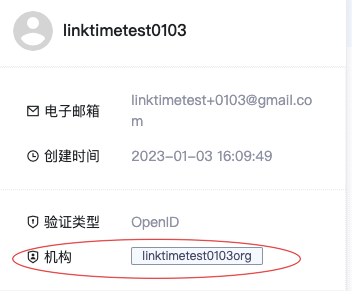
3.获取本机构 Mysql 的链接信息
每一个机构,系统都为其会内置一套数据存储组件(Mysql,Hive等等),机构角色可以获得机构Mysql的链接方式如下:
1)切换到「数据管理」菜单
2)选择数据源链接
3)任意点击数据采集/数据导出/数据服务子菜单
4)在列表中可见预置数据源,点击获取地址
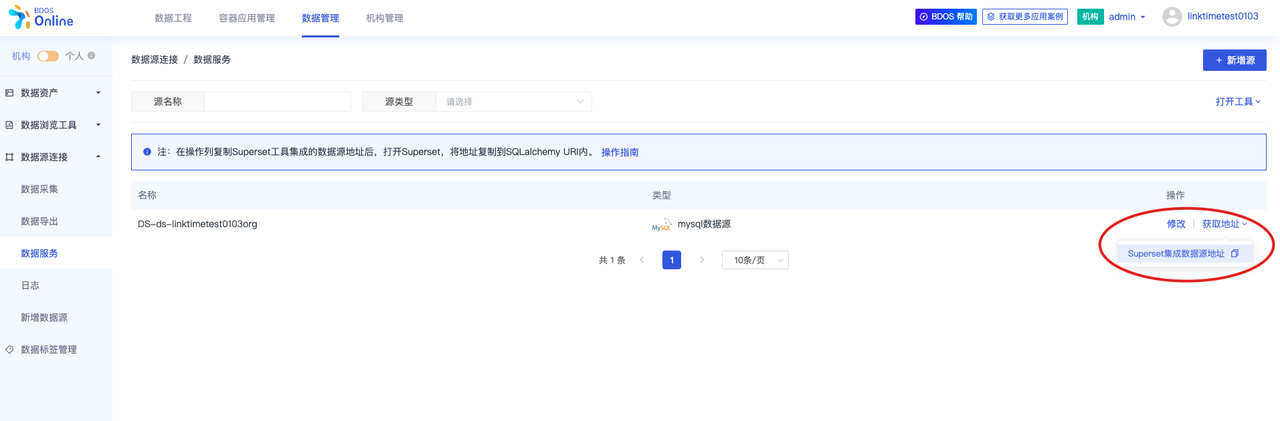
复制后得到以下格式的数据库信息
mysql://数据库账号:密码@数据库地址:端口号/数据库db
这组信息可以用于BI工具数据源链接,或者是Jupyternotebook 把数据写入数据库时候所需要的配置信息
例如:
mysql://linktimetest0103org_admin:xxxxxxxxxx@pc-uf60wbgj8zn420251.rwlb.rds.aliyuncs.com:3306/bdos_org_linktimetest0103org_db
按照格式拆解后
- username:
linktimetest0103org_admin - password:
xxxxxxxxxx(使用x脱敏替换了原始密码) - 数据库地址:
pc-uf60wbgj8zn420251.rwlb.rds.aliyuncs.com - 端口:
3306 - 数据库db:
bdos_org_linktimetest0103org_db
4.创建一个数据工程项目
- 点击创建项目,填写项目必要信息,完成项目创建

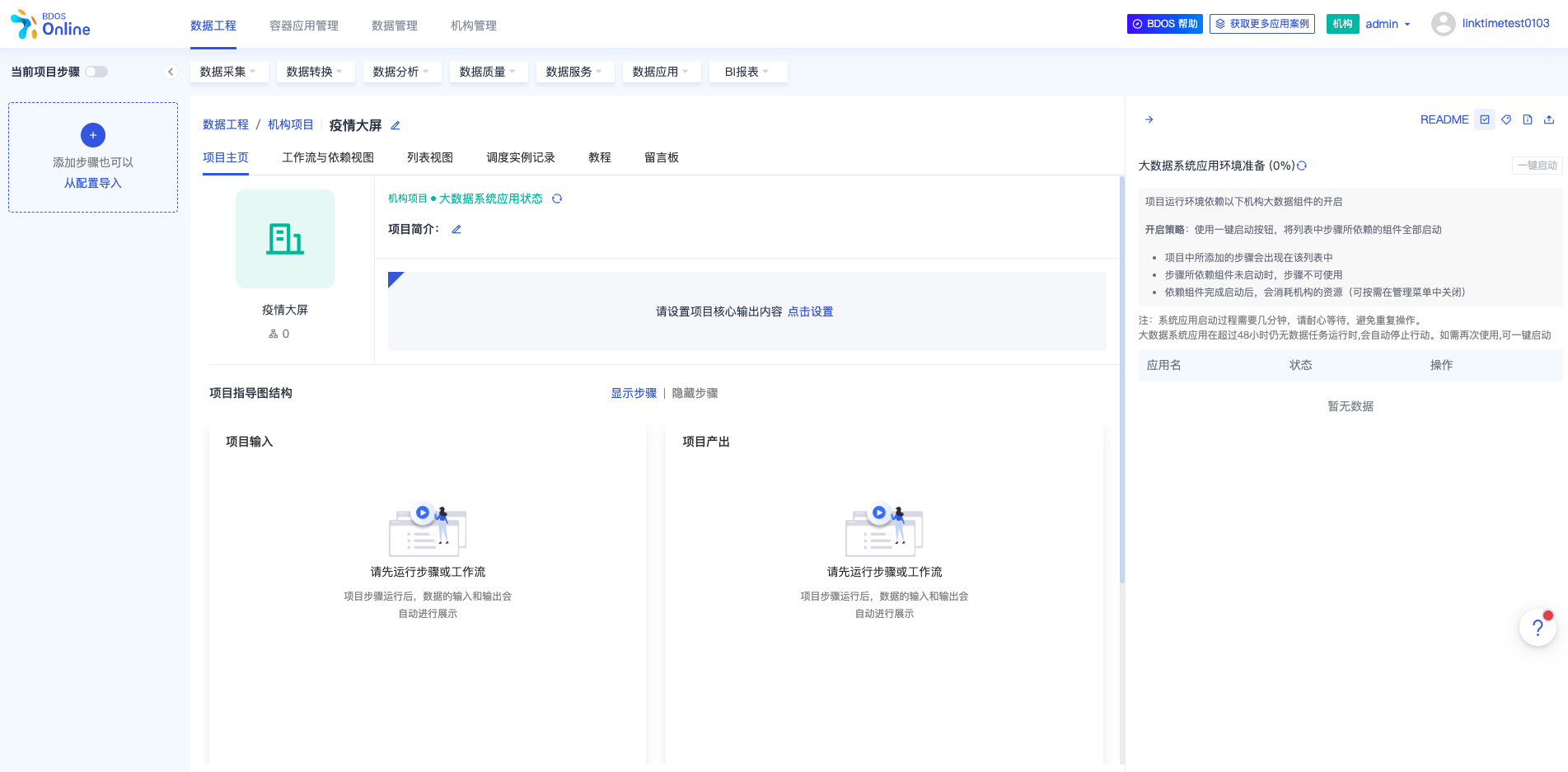
5.查看公共数据集的数据
- 切换到数据管理模块
- 可以查看下上一个章节介绍过的本教程会使用的「精选数据集」
part1: 采集疫情原始数据,完成数据计算、导出
采集:疫情病历数据
首先:使用数据库采集步骤,把疫情统计数据采集至本机构大数据组件 Hive 中


- 数据源
- 选择public_mysql_readonly
- 表
- biz_covid19
- 数据范围
- 选择全量
- 导出字段
- 默认全选
- 下一步
- 是否需要对数据进行分区
- 取消勾选(本案例先不考虑数据分区的情况)
- Hive数据库名称
- 保持默认(默认就会选择机构Hive)
- Hive表名称
- 填写:biz_covid19_data(为保证后续使用教程的方便,建议使用教程时候填写此表名)
- 保存
- 运行
然后:使用Hive程序,对采集进来的数据做清洗、切分以及计算(3个计算步骤)


数据计算-1:湖北省内外疫情对比
- 粘贴复制下面HQL代码,保存步骤并运行
- 修改第一句:替换 「机构名称」为当前机构的真实名称(可以参考part0中的第2步)
use org_机构名称; |
数据计算-2:全国各省疫情趋势
- 粘贴复制下面HQL代码,保存步骤并运行
- 修改第一句:替换 「机构名称」为当前机构的真实名称(可以参考part0中的第2步)
use org_机构名称; |
数据计算-3:湖北省疫情趋势
- 粘贴复制下面HQL代码,保存步骤并运行
- 修改第一句:替换 「机构名称」为当前机构的真实名称(可以参考part0中的第2步)
use org_机构名称; |
然后:使用ETL程序,清洗计算后的数据导出到数据集市待用

数据导出-1:导出湖北省内外疫情对比数据
- 数据源类型(输入源配置)
- 选择:Hive
- 数据源
- 选择:org_机构名 (机构Hive数据库,默认是下拉列表中第一个)
- 表
- 选择:ads_hubei_vs_others
- Query
- 保持默认
- 下一步
- 数据源类型(输出源配置)
- Mysql
- 数据源
- export-FM-ds-机构名(选择这个机构预置的Mysql输出源,默认是下拉列表中第一个)
- 表
- 填写:ads_cov19_hubei_vs_ow
- 设置主键
- 保持默认
- 建表语句
- 点击:获取建表语句
- 数据变更
- 保持默认
- 下一步
- 点击「开始匹配」,得到匹配成功的提示
- 保存
- 运行
数据导出-2:导出全国各省疫情趋势数据
- 数据源类型(输入源配置)
- 选择:Hive
- 数据源
- 选择:org_机构名 (机构Hive数据库,默认是下拉列表中第一个)
- 表
- 选择:ads_prov_by_prov
- Query
- 保持默认
- 下一步
- 数据源类型(输出源配置)
- Mysql
- 数据源
- export-FM-ds-机构名(选择这个机构预置的Mysql输出源,默认是下拉列表中第一个)
- 表
- 填写:ads_cov19_prov_by_prov
- 设置主键
- 保持默认
- 建表语句
- 点击:获取建表语句
- 数据变更
- 保持默认
- 下一步
- 点击「开始匹配」,得到匹配成功的提示
- 保存
- 运行
数据导出-3:导出湖北省疫情趋势数据
- 数据源类型(输入源配置)
- 选择:Hive
- 数据源
- 选择:org_机构名 (机构Hive数据库,默认是下拉列表中第一个)
- 表
- 选择:ads_hubei
- Query
- 保持默认
- 下一步
- 数据源类型(输出源配置)
- Mysql
- 数据源
- export-FM-ds-机构名(选择这个机构预置的Mysql输出源,默认是下拉列表中第一个)
- 表
- 填写:ads_cov19_hubei
- 设置主键
- 保持默认
- 建表语句
- 点击:获取建表语句
- 数据变更
- 保持默认
- 下一步
- 点击「开始匹配」,得到匹配成功的提示
- 保存
- 运行
part2: 采集新闻报道,完成心态、词频,文本聚类分析
采集:疫情新闻文章
首先,把公共数据源中的疫情新闻报道采集到机构数据库(Mysql)中


- 数据源类型(输入源配置)
- 选择:Mysql
- 数据源
- 选择:public_mysql_readonly
- 表
- 选择:biz_covid19_articles
- 模式切换
- 保持默认
- Query
- 保持默认
- 下一步
- 数据源类型(输出源配置)
- Mysql
- 数据源
- export-FM-ds-机构名(选择这个机构预置的Mysql输出源,默认是下拉列表中第一个)
- 表
- 填写:biz_covid19_articles
- 设置主键
- 保持默认
- 建表语句
- 点击:获取建表语句
- 数据变更
- 保持默认
- 下一步
- 点击「开始匹配」,得到匹配成功的提示
- 保存
- 运行
舆情分析:心态对比
然后,使用 JupyterNote book,做疫情分析:心态对比


- 点击进入,把以下代码进行复制粘贴
一个代码块复制进入一个单元格
安装完必要模块后,一般需要重启一下 kernel 让模块生效
pip install jieba -i https://nx.linktimecloud.com/repository/pypi-group/simple/ |
- 当copy到下面这段代码块的时候需要进行修改 :host,user,password,database 中的 xxxx 为当前机构mysql数据库的(参考part0-第2步)
#table |
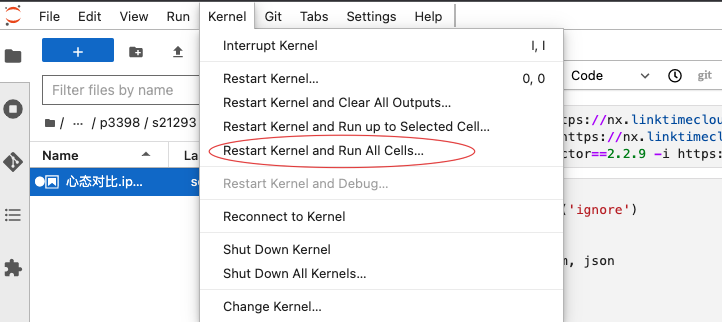
- 保存 Notebook(可以重命名为:心态对比)
- 点击 kernel,选择 restart kernel and run all cells
舆情分析:疫情词云
再创建一个 JupyterNote book 步骤 在里面创建一个 JupyterNote,做疫情分析:疫情词云
- 点击进入,把以下代码进行复制粘贴
一个代码块复制进入一个单元格
pip install jieba -i https://nx.linktimecloud.com/repository/pypi-group/simple/ |
- 当copy到下面这段代码块的时候需要进行修改 :host,user,password,database 中的 xxxx 为当前机构mysql数据库的(参考part0-第2步)
#table |
- 点击保存(可以重命名为:疫情词云)
- 点击 kernel,选择 restart kernel and run all cells
舆情分析:文本聚类
再创建一个 JupyterNote book 步骤 在里面创建一个 JupyterNote,做疫情分析:文本聚类
- 点击进入,把以下代码进行复制粘贴
一个代码块复制进入一个单元格
pip install jieba -i https://nx.linktimecloud.com/repository/pypi-group/simple/ |
- 当copy到下面这段代码块的时候需要进行修改 :host,user,password,database 中的 xxxx 为当前机构mysql数据库的(参考part0-第2步)
#table |
- 点击保存(可以重命名为:文本聚类)
- 点击 kernel,选择 restart kernel and run all cells
part3: 梳理进度,规范步骤命名
- 蓝色属于已经完成的部分

| # | 步骤名称 | 步骤类型 |
|---|---|---|
| 1 | 1.1 采集:疫情病例数据 | 数据库采集 |
| 2 | 1.2 采集:疫情新闻文章 | ETL程序 |
| 3 | 2.1 数据计算:湖北省内外疫情对比 | Hive程序 |
| 4 | 2.2 数据计算:全国各省疫情趋势 | Hive程序 |
| 5 | 2.3 数据计算-3:湖北省疫情趋势 | Hive程序 |
| 6 | 2.4 数据导出:湖北省内外疫情对比 | ETL程序 |
| 7 | 2.5 数据导出:全国各省疫情数据趋势 | ETL程序 |
| 8 | 2.6 数据导出:湖北省疫情趋势 | ETL程序 |
| 9 | 3.1 舆情分析:心态对比 | JupyterNotebook |
| 10 | 3.2 舆情分析:疫情词云 | JupyterNotebook |
| 11 | 3.3 舆情分析:文本聚类 | JupyterNotebook |
| 12 | 4.1 API-1:地图数据 | API |
| 13 | 4.2 API-2:省内省外 | API |
| 14 | 4.3 API-3:省内数据 | API |
| 15 | 4.4 API-4:心态对比 | API |
| 16 | 4.5 API-5:文本聚类 | API |
| 17 | 4.6 API-6:词云 | API |
| 18 | 5.1 疫情大屏发布 | Docker应用(通过配置) |
part4: 创建 API
数据集市列表
| # | 数据表 | API名称 | API路径 |
|---|---|---|---|
| 1 | ads_cov19_prov_by_prov | 省份分类地图数据 | /winner/country |
| 2 | ads_cov19_hubei_vs_ow | 湖北省内省外数据 | /winner/hubei |
| 3 | ads_cov19_hubei | 湖北省内城市数据 | /winner/province |
| 4 | ads_cov19_kms | 心态对比数据 | /winner/mentality |
| 5 | ads_cov19_cluster | 文本聚类数据 | /winer/tfidf |
| 6 | ads_cov19_wordcount | 疫情词云 | /winner/ciyun |
选择使用自定义 sql
/winner/country(地图数据)
- API 路径:/winner/country
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
select |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:data_day
- 值:20201231
- 测试
- 发布
/winner/hubei(省内省外数据)
- API 路径:/winner/hubei
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
select |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:data_day
- 值:20201231
- 测试
- 发布
/winner/province(省内数据)
- API 路径:/winner/province
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
select |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:data_day
- 值:20201231
- 测试
- 发布
/winner/mentality(心态对比数据)
- API 路径:/winner/mentality
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
SELECT point from bdos_org_机构名称_db.ads_cov19_kms where year=substr(cast(${year} as char), 1, 4) |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:year
- 值:2020
- 测试
- 发布
/winer/tfidf(文本聚类数据)
- API 路径:/winer/tfidf
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
select word,score from bdos_org_机构名称_db.ads_cov19_cluster where year = substr(convert(${year} , char), 1, 4) ORDER BY score desc limit 50 |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:year
- 值:2020
- 测试
- 发布
/winner/ciyun(疫情词云数据)
- API 路径:/winner/ciyun
- 下一步
- 数据源:DS-ds-机构名称(Mysql)
- 使用自定义sql
- 对应 sql 语句,需要把语句中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
select word, count from bdos_org_机构名称_db.ads_cov19_wordcount where year = substr(convert(${year} , char), 1, 4)order by count desc limit 50 |
- 保存
- API 测试:选择高级模式
- 添加参数
- 参数:year
- 值:2020
- 测试
- 发布
part5 大屏发布


- 选择通过Dockerfile
- 粘贴复制下面的 dockerfile 文件
FROM dev-reg-aliyun.linktimecloud.com/openjdk:8-jdk-stretch |
通用配置:
- CPU:0.3
- Mem:512MB
- 其他默认
网络配置:
- 添加一项,并且把容器端口改为8080
- 其余默认
环境变量:
需要把value中的「机构名称」替换为本机构的机构名称,数据库获取办法见part0:准备工作第2步
key:PATH_PREFIX
- value: /online/机构名称